 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSFedMed: Dual-Scale Federated Medical Image Segmentation via Mutual Distillation Between Foundation and Lightweight Models
Jan 22, 2026Foundation Models (FMs) have demonstrated strong generalization across diverse vision tasks. However, their deployment in federated settings is hindered by high computational demands, substantial communication overhead, and significant inference costs. We propose DSFedMed, a dual-scale federated framework that enables mutual knowledge distillation between a centralized foundation model and lightweight client models for medical image segmentation. To support knowledge distillation, a set of high-quality medical images is generated to replace real public datasets, and a learnability-guided sample selection strategy is proposed to enhance efficiency and effectiveness in dual-scale distillation. This mutual distillation enables the foundation model to transfer general knowledge to lightweight clients, while also incorporating client-specific insights to refine the foundation model. Evaluations on five medical imaging segmentation datasets show that DSFedMed achieves an average 2 percent improvement in Dice score while reducing communication costs and inference time by nearly 90 percent compared to existing federated foundation model baselines. These results demonstrate significant efficiency gains and scalability for resource-limited federated deployments.
Feature-Aware One-Shot Federated Learning via Hierarchical Token Sequences
Jan 07, 2026One-shot federated learning (OSFL) reduces the communication cost and privacy risks of iterative federated learning by constructing a global model with a single round of communication. However, most existing methods struggle to achieve robust performance on real-world domains such as medical imaging, or are inefficient when handling non-IID (Independent and Identically Distributed) data. To address these limitations, we introduce FALCON, a framework that enhances the effectiveness of OSFL over non-IID image data. The core idea of FALCON is to leverage the feature-aware hierarchical token sequences generation and knowledge distillation into OSFL. First, each client leverages a pretrained visual encoder with hierarchical scale encoding to compress images into hierarchical token sequences, which capture multi-scale semantics. Second, a multi-scale autoregressive transformer generator is used to model the distribution of these token sequences and generate the synthetic sequences. Third, clients upload the synthetic sequences along with the local classifier trained on the real token sequences to the server. Finally, the server incorporates knowledge distillation into global training to reduce reliance on precise distribution modeling. Experiments on medical and natural image datasets validate the effectiveness of FALCON in diverse non-IID scenarios, outperforming the best OSFL baselines by 9.58% in average accuracy.
Federated Learning for Medical Image Classification: A Comprehensive Benchmark
Apr 07, 2025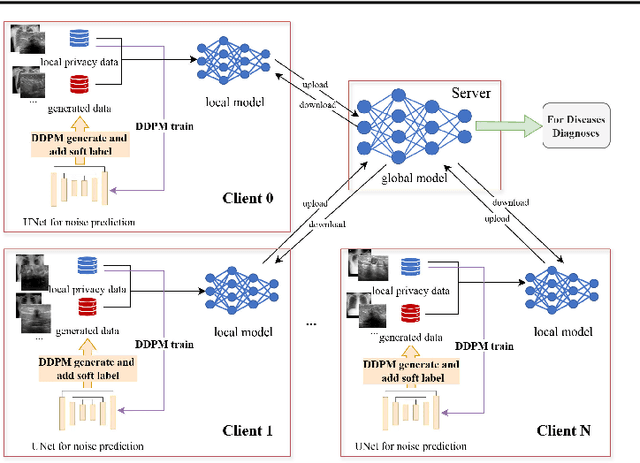
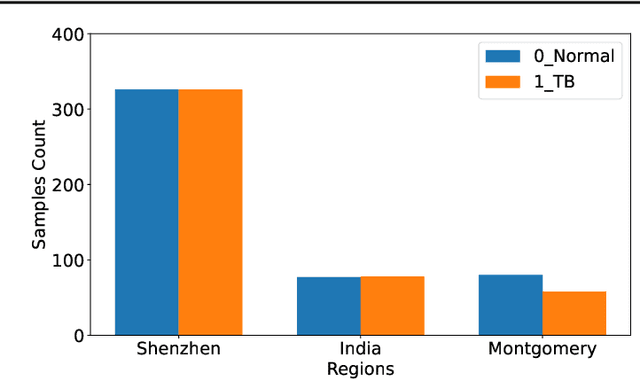
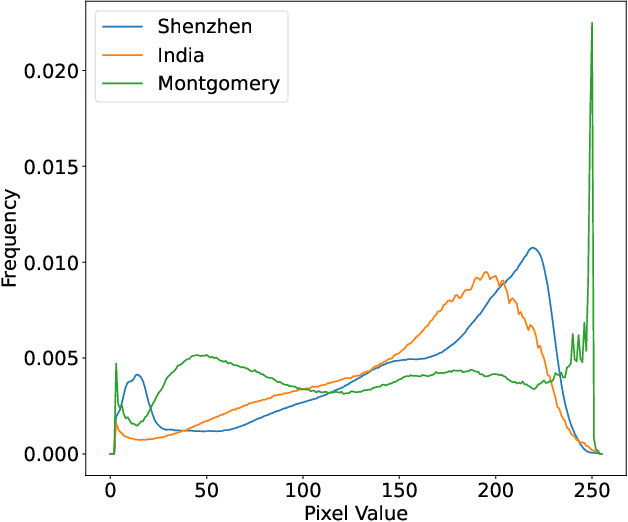
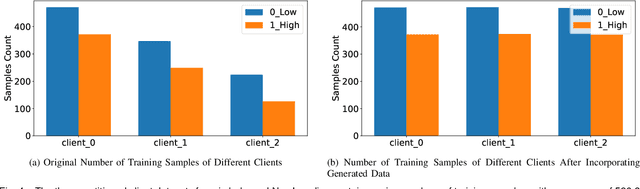
The federated learning paradigm is wellsuited for the field of medical image analysis, as it can effectively cope with machine learning on isolated multicenter data while protecting the privacy of participating parties. However, current research on optimization algorithms in federated learning often focuses on limited datasets and scenarios, primarily centered around natural images, with insufficient comparative experiments in medical contexts. In this work, we conduct a comprehensive evaluation of several state-of-the-art federated learning algorithms in the context of medical imaging. We conduct a fair comparison of classification models trained using various federated learning algorithms across multiple medical imaging datasets. Additionally, we evaluate system performance metrics, such as communication cost and computational efficiency, while considering different federated learning architectures. Our findings show that medical imaging datasets pose substantial challenges for current federated learning optimization algorithms. No single algorithm consistently delivers optimal performance across all medical federated learning scenarios, and many optimization algorithms may underperform when applied to these datasets. Our experiments provide a benchmark and guidance for future research and application of federated learning in medical imaging contexts. Furthermore, we propose an efficient and robust method that combines generative techniques using denoising diffusion probabilistic models with label smoothing to augment datasets, widely enhancing the performance of federated learning on classification tasks across various medical imaging datasets. Our code will be released on GitHub, offering a reliable and comprehensive benchmark for future federated learning studies in medical imaging.
Improving EEG Classification Through Randomly Reassembling Original and Generated Data with Transformer-based Diffusion Models
Jul 20, 2024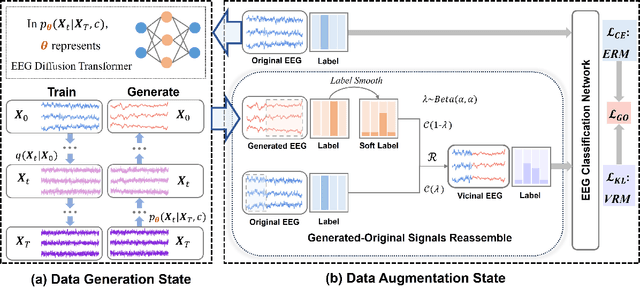
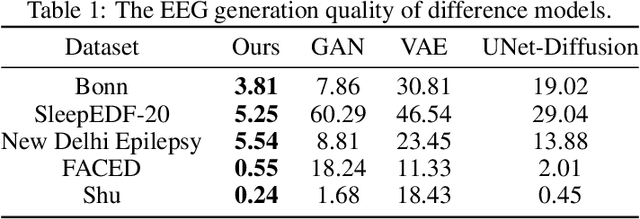
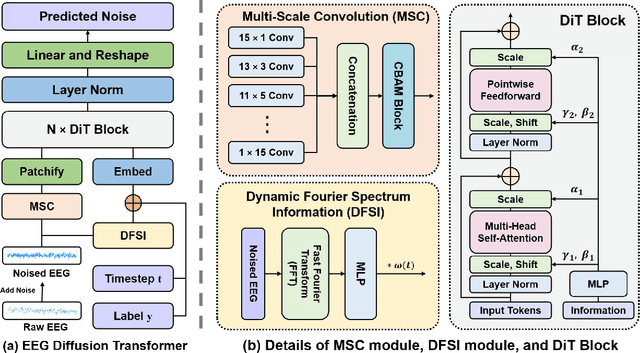
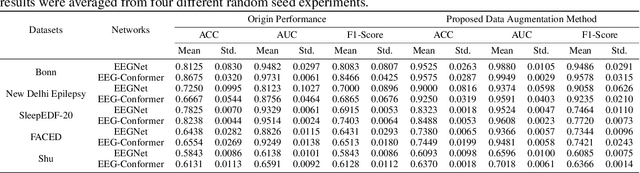
Electroencephalogram (EEG) classification has been widely used in various medical and engineering applications, where it is important for understanding brain function, diagnosing diseases, and assessing mental health conditions. However, the scarcity of EEG data severely restricts the performance of EEG classification networks, and generative model-based data augmentation methods emerging as potential solutions to overcome this challenge. There are two problems with existing such methods: (1) The quality of the generated EEG signals is not high. (2) The enhancement of EEG classification networks is not effective. In this paper, we propose a Transformer-based denoising diffusion probabilistic model and a generated data-based data augmentation method to address the above two problems. For the characteristics of EEG signals, we propose a constant-factor scaling method to preprocess the signals, which reduces the loss of information. We incorporated Multi-Scale Convolution and Dynamic Fourier Spectrum Information modules into the model, improving the stability of the training process and the quality of the generated data. The proposed augmentation method randomly reassemble the generated data with original data in the time-domain to obtain vicinal data, which improves the model performance by minimizing the empirical risk and the vicinal risk. We experiment the proposed augmentation method on five EEG datasets for four tasks and observe significant accuracy performance improvements: 14.00% on the Bonn dataset; 25.83% on the New Delhi epilepsy dataset; 4.98% on the SleepEDF-20 dataset; 9.42% on the FACED dataset; 2.5% on the Shu dataset. We intend to make the code of our method publicly accessible shortly
Better than Random: Reliable NLG Human Evaluation with Constrained Active Sampling
Jun 12, 2024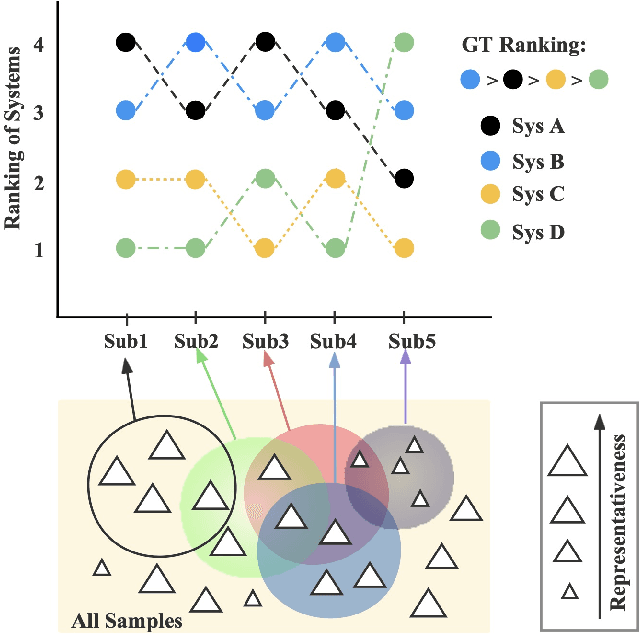
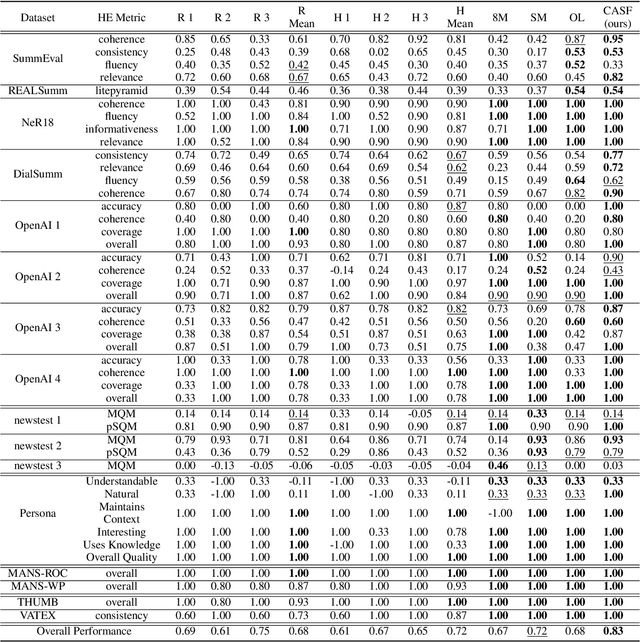
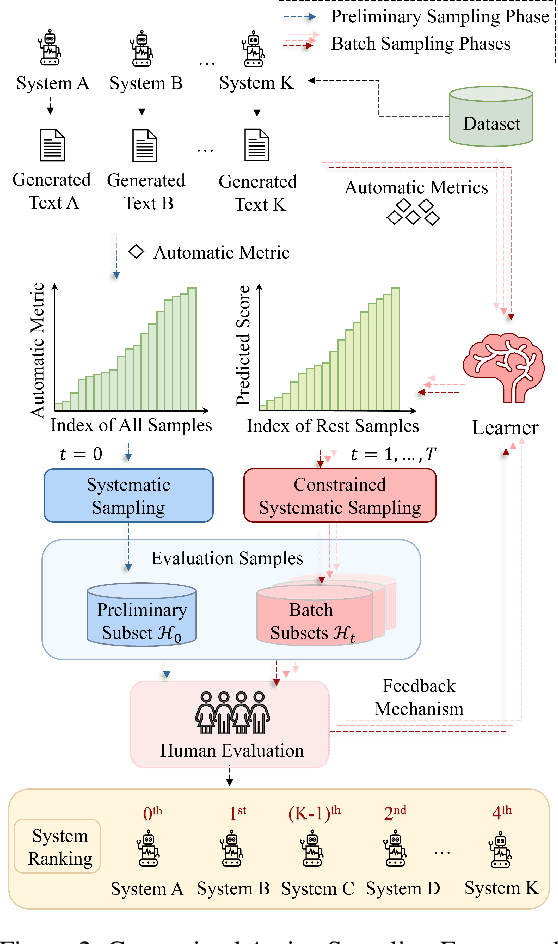
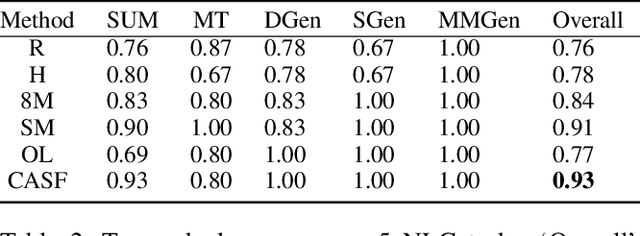
Human evaluation is viewed as a reliable evaluation method for NLG which is expensive and time-consuming. To save labor and costs, researchers usually perform human evaluation on a small subset of data sampled from the whole dataset in practice. However, different selection subsets will lead to different rankings of the systems. To give a more correct inter-system ranking and make the gold standard human evaluation more reliable, we propose a Constrained Active Sampling Framework (CASF) for reliable human judgment. CASF operates through a Learner, a Systematic Sampler and a Constrained Controller to select representative samples for getting a more correct inter-system ranking.Experiment results on 137 real NLG evaluation setups with 44 human evaluation metrics across 16 datasets and 5 NLG tasks demonstrate CASF receives 93.18% top-ranked system recognition accuracy and ranks first or ranks second on 90.91% of the human metrics with 0.83 overall inter-system ranking Kendall correlation.Code and data are publicly available online.
ProMamba: Prompt-Mamba for polyp segmentation
Mar 26, 2024Detecting polyps through colonoscopy is an important task in medical image segmentation, which provides significant assistance and reference value for clinical surgery. However, accurate segmentation of polyps is a challenging task due to two main reasons. Firstly, polyps exhibit various shapes and colors. Secondly, the boundaries between polyps and their normal surroundings are often unclear. Additionally, significant differences between different datasets lead to limited generalization capabilities of existing methods. To address these issues, we propose a segmentation model based on Prompt-Mamba, which incorporates the latest Vision-Mamba and prompt technologies. Compared to previous models trained on the same dataset, our model not only maintains high segmentation accuracy on the validation part of the same dataset but also demonstrates superior accuracy on unseen datasets, exhibiting excellent generalization capabilities. Notably, we are the first to apply the Vision-Mamba architecture to polyp segmentation and the first to utilize prompt technology in a polyp segmentation model. Our model efficiently accomplishes segmentation tasks, surpassing previous state-of-the-art methods by an average of 5% across six datasets. Furthermore, we have developed multiple versions of our model with scaled parameter counts, achieving better performance than previous models even with fewer parameters. Our code and trained weights will be released soon.
A Segmentation Foundation Model for Diverse-type Tumors
Mar 11, 2024Large pre-trained models with their numerous model parameters and extensive training datasets have shown excellent performance in various tasks. Many publicly available medical image datasets do not have a sufficient amount of data so there are few large-scale models in medical imaging. We propose a large-scale Tumor Segmentation Foundation Model (TSFM) with 1.6 billion parameters using Resblock-backbone and Transformer-bottleneck,which has good transfer ability for downstream tasks. To make TSFM exhibit good performance in tumor segmentation, we make full use of the strong spatial correlation between tumors and organs in the medical image, innovatively fuse 7 tumor datasets and 3 multi-organ datasets to build a 3D medical dataset pool, including 2779 cases with totally 300k medical images, whose size currently exceeds many other single publicly available datasets. TSFM is the pre-trained model for medical image segmentation, which also can be transferred to multiple downstream tasks for fine-tuning learning. The average performance of our pre-trained model is 2% higher than that of nnU-Net across various tumor types. In the transfer learning task, TSFM only needs 5% training epochs of nnU-Net to achieve similar performance and can surpass nnU-Net by 2% on average with 10% training epoch. Pre-trained TSFM and its code will be released soon.
FedFMS: Exploring Federated Foundation Models for Medical Image Segmentation
Mar 08, 2024
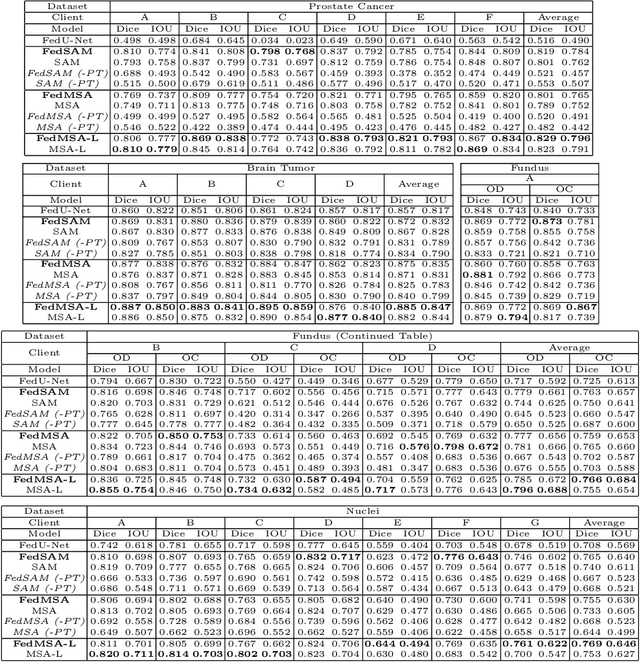


Medical image segmentation is crucial for clinical diagnosis. The Segmentation Anything Model (SAM) serves as a powerful foundation model for visual segmentation and can be adapted for medical image segmentation. However, medical imaging data typically contain privacy-sensitive information, making it challenging to train foundation models with centralized storage and sharing. To date, there are few foundation models tailored for medical image deployment within the federated learning framework, and the segmentation performance, as well as the efficiency of communication and training, remain unexplored. In response to these issues, we developed Federated Foundation models for Medical image Segmentation (FedFMS), which includes the Federated SAM (FedSAM) and a communication and training-efficient Federated SAM with Medical SAM Adapter (FedMSA). Comprehensive experiments on diverse datasets are conducted to investigate the performance disparities between centralized training and federated learning across various configurations of FedFMS. The experiments revealed that FedFMS could achieve performance comparable to models trained via centralized training methods while maintaining privacy. Furthermore, FedMSA demonstrated the potential to enhance communication and training efficiency. Our model implementation codes are available at https://github.com/LIU-YUXI/FedFMS.
Spikformer V2: Join the High Accuracy Club on ImageNet with an SNN Ticket
Jan 04, 2024Spiking Neural Networks (SNNs), known for their biologically plausible architecture, face the challenge of limited performance. The self-attention mechanism, which is the cornerstone of the high-performance Transformer and also a biologically inspired structure, is absent in existing SNNs. To this end, we explore the potential of leveraging both self-attention capability and biological properties of SNNs, and propose a novel Spiking Self-Attention (SSA) and Spiking Transformer (Spikformer). The SSA mechanism eliminates the need for softmax and captures the sparse visual feature employing spike-based Query, Key, and Value. This sparse computation without multiplication makes SSA efficient and energy-saving. Further, we develop a Spiking Convolutional Stem (SCS) with supplementary convolutional layers to enhance the architecture of Spikformer. The Spikformer enhanced with the SCS is referred to as Spikformer V2. To train larger and deeper Spikformer V2, we introduce a pioneering exploration of Self-Supervised Learning (SSL) within the SNN. Specifically, we pre-train Spikformer V2 with masking and reconstruction style inspired by the mainstream self-supervised Transformer, and then finetune the Spikformer V2 on the image classification on ImageNet. Extensive experiments show that Spikformer V2 outperforms other previous surrogate training and ANN2SNN methods. An 8-layer Spikformer V2 achieves an accuracy of 80.38% using 4 time steps, and after SSL, a 172M 16-layer Spikformer V2 reaches an accuracy of 81.10% with just 1 time step. To the best of our knowledge, this is the first time that the SNN achieves 80+% accuracy on ImageNet. The code will be available at Spikformer V2.
Dual Branch Network Towards Accurate Printed Mathematical Expression Recognition
Dec 14, 2023Over the past years, Printed Mathematical Expression Recognition (PMER) has progressed rapidly. However, due to the insufficient context information captured by Convolutional Neural Networks, some mathematical symbols might be incorrectly recognized or missed. To tackle this problem, in this paper, a Dual Branch transformer-based Network (DBN) is proposed to learn both local and global context information for accurate PMER. In our DBN, local and global features are extracted simultaneously, and a Context Coupling Module (CCM) is developed to complement the features between the global and local contexts. CCM adopts an interactive manner so that the coupled context clues are highly correlated to each expression symbol. Additionally, we design a Dynamic Soft Target (DST) strategy to utilize the similarities among symbol categories for reasonable label generation. Our experimental results have demonstrated that DBN can accurately recognize mathematical expressions and has achieved state-of-the-art performance.