 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter than Random: Reliable NLG Human Evaluation with Constrained Active Sampling
Paper and Code
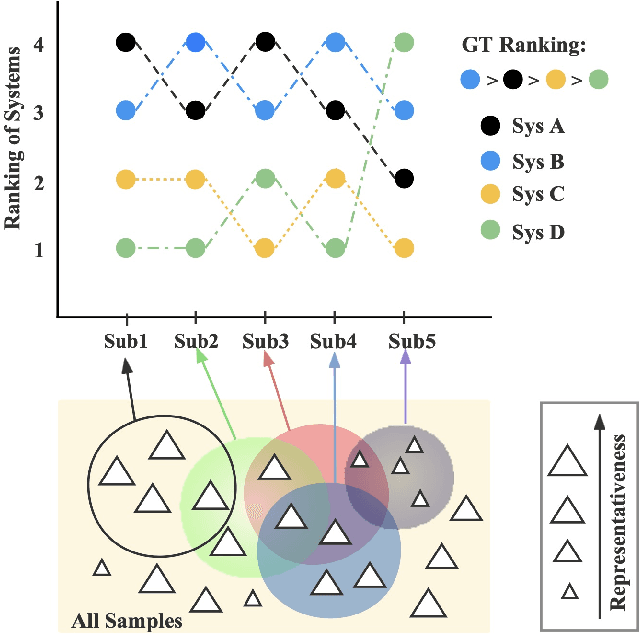
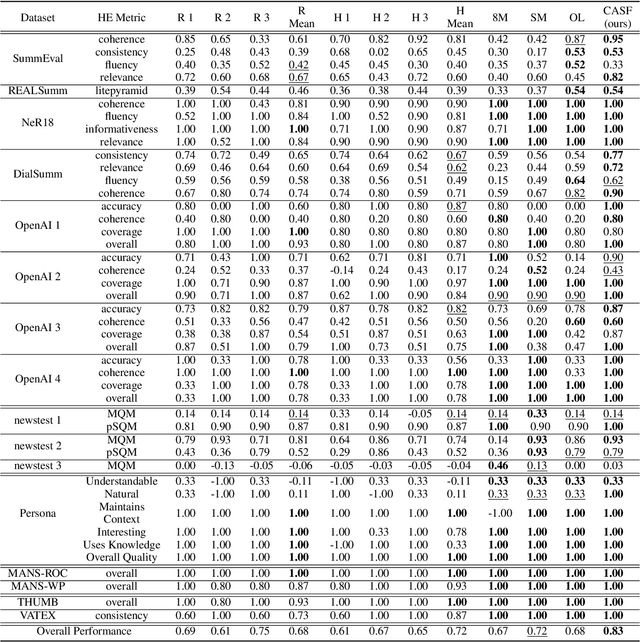
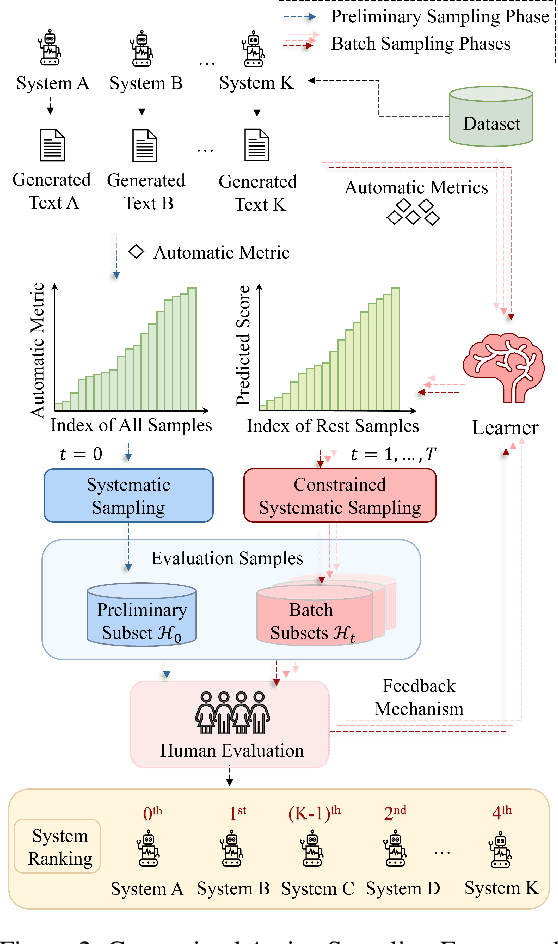
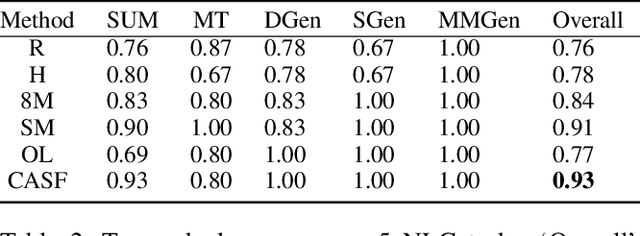
Human evaluation is viewed as a reliable evaluation method for NLG which is expensive and time-consuming. To save labor and costs, researchers usually perform human evaluation on a small subset of data sampled from the whole dataset in practice. However, different selection subsets will lead to different rankings of the systems. To give a more correct inter-system ranking and make the gold standard human evaluation more reliable, we propose a Constrained Active Sampling Framework (CASF) for reliable human judgment. CASF operates through a Learner, a Systematic Sampler and a Constrained Controller to select representative samples for getting a more correct inter-system ranking.Experiment results on 137 real NLG evaluation setups with 44 human evaluation metrics across 16 datasets and 5 NLG tasks demonstrate CASF receives 93.18% top-ranked system recognition accuracy and ranks first or ranks second on 90.91% of the human metrics with 0.83 overall inter-system ranking Kendall correlation.Code and data are publicly available online.