 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefining and Detecting Vulnerability in Human Evaluation Guidelines: A Preliminary Study Towards Reliable NLG Evaluation
Jun 12, 2024
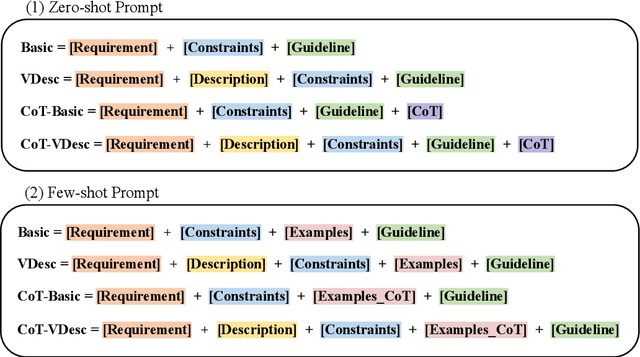
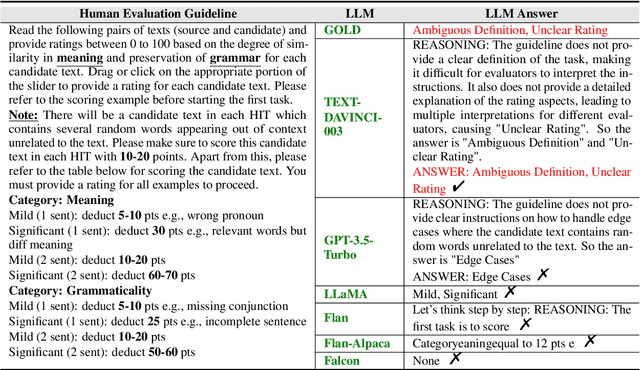
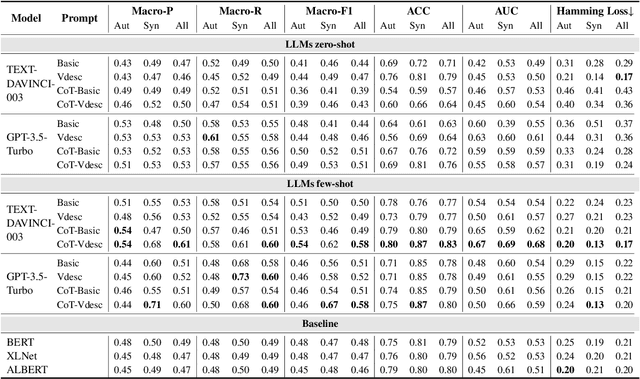
Human evaluation serves as the gold standard for assessing the quality of Natural Language Generation (NLG) systems. Nevertheless, the evaluation guideline, as a pivotal element ensuring reliable and reproducible human assessment, has received limited attention.Our investigation revealed that only 29.84% of recent papers involving human evaluation at top conferences release their evaluation guidelines, with vulnerabilities identified in 77.09% of these guidelines. Unreliable evaluation guidelines can yield inaccurate assessment outcomes, potentially impeding the advancement of NLG in the right direction. To address these challenges, we take an initial step towards reliable evaluation guidelines and propose the first human evaluation guideline dataset by collecting annotations of guidelines extracted from existing papers as well as generated via Large Language Models (LLMs). We then introduce a taxonomy of eight vulnerabilities and formulate a principle for composing evaluation guidelines. Furthermore, a method for detecting guideline vulnerabilities has been explored using LLMs, and we offer a set of recommendations to enhance reliability in human evaluation. The annotated human evaluation guideline dataset and code for the vulnerability detection method are publicly available online.
Better than Random: Reliable NLG Human Evaluation with Constrained Active Sampling
Jun 12, 2024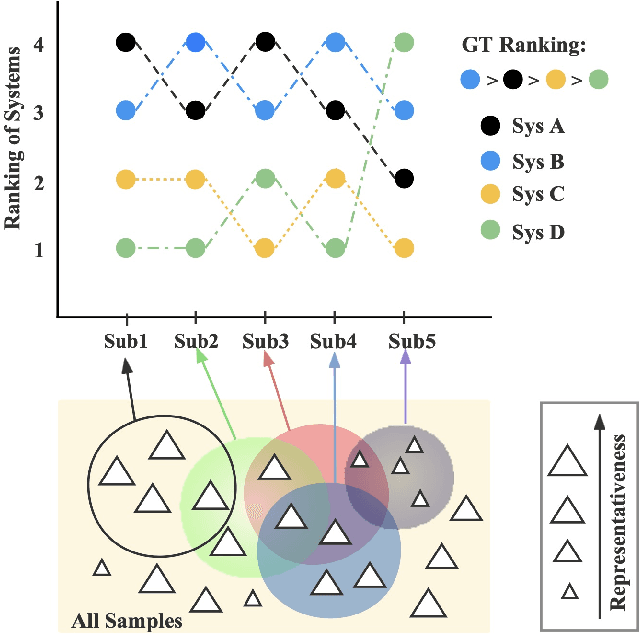
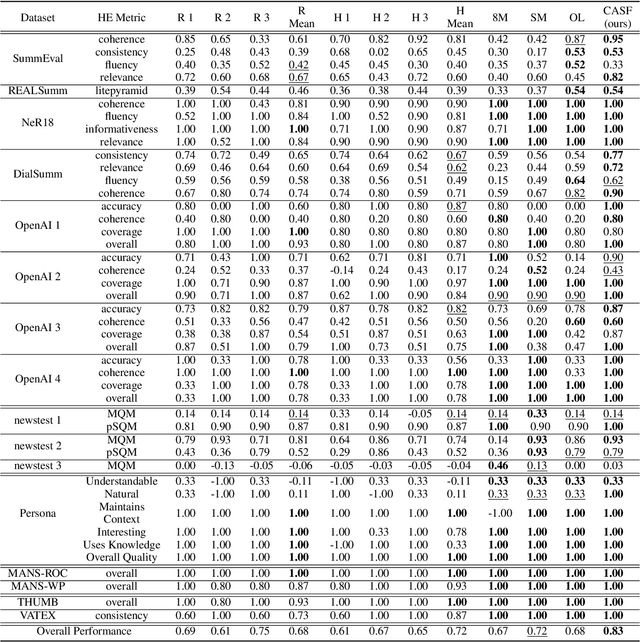
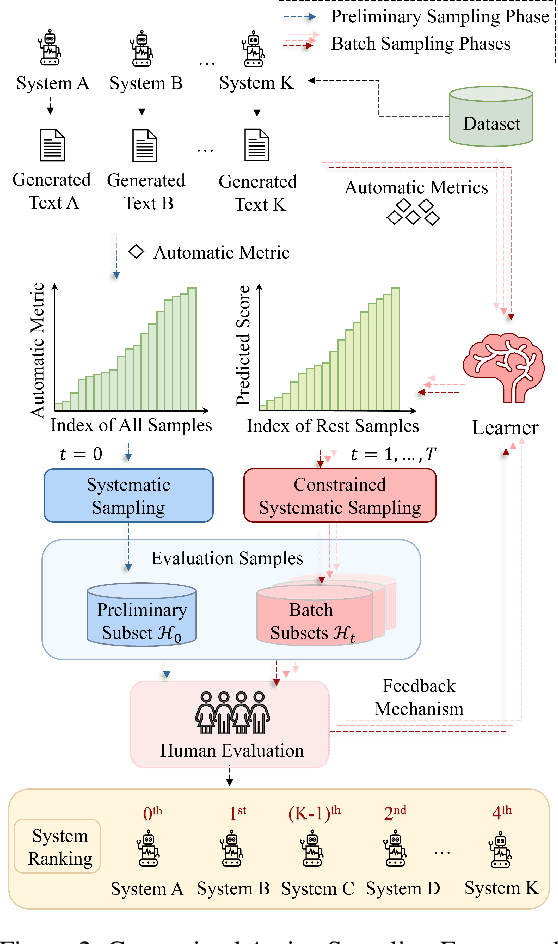
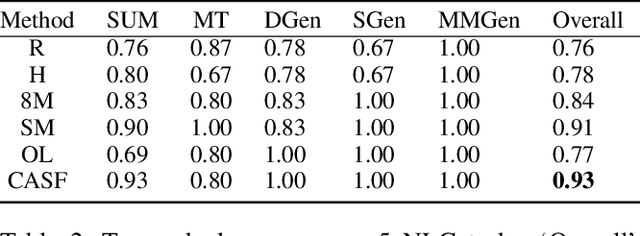
Human evaluation is viewed as a reliable evaluation method for NLG which is expensive and time-consuming. To save labor and costs, researchers usually perform human evaluation on a small subset of data sampled from the whole dataset in practice. However, different selection subsets will lead to different rankings of the systems. To give a more correct inter-system ranking and make the gold standard human evaluation more reliable, we propose a Constrained Active Sampling Framework (CASF) for reliable human judgment. CASF operates through a Learner, a Systematic Sampler and a Constrained Controller to select representative samples for getting a more correct inter-system ranking.Experiment results on 137 real NLG evaluation setups with 44 human evaluation metrics across 16 datasets and 5 NLG tasks demonstrate CASF receives 93.18% top-ranked system recognition accuracy and ranks first or ranks second on 90.91% of the human metrics with 0.83 overall inter-system ranking Kendall correlation.Code and data are publicly available online.
Benchmarking Knowledge Boundary for Large Language Model: A Different Perspective on Model Evaluation
Feb 18, 2024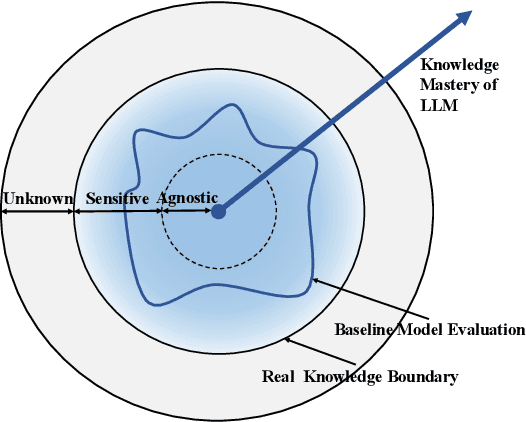
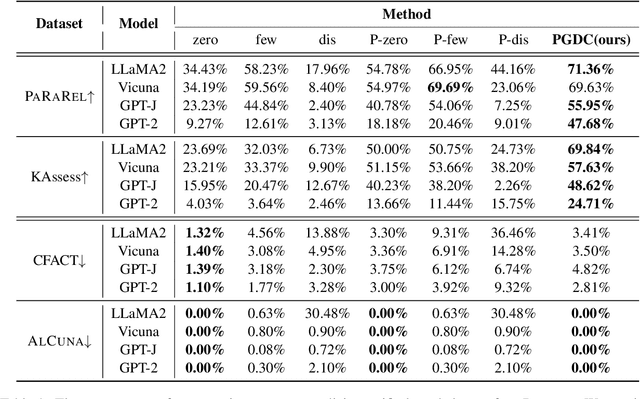
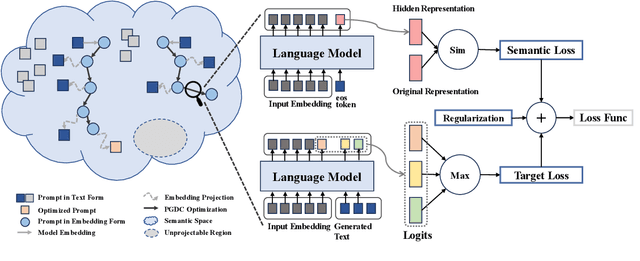

In recent years, substantial advancements have been made in the development of large language models, achieving remarkable performance across diverse tasks. To evaluate the knowledge ability of language models, previous studies have proposed lots of benchmarks based on question-answering pairs. We argue that it is not reliable and comprehensive to evaluate language models with a fixed question or limited paraphrases as the query, since language models are sensitive to prompt. Therefore, we introduce a novel concept named knowledge boundary to encompass both prompt-agnostic and prompt-sensitive knowledge within language models. Knowledge boundary avoids prompt sensitivity in language model evaluations, rendering them more dependable and robust. To explore the knowledge boundary for a given model, we propose projected gradient descent method with semantic constraints, a new algorithm designed to identify the optimal prompt for each piece of knowledge. Experiments demonstrate a superior performance of our algorithm in computing the knowledge boundary compared to existing methods. Furthermore, we evaluate the ability of multiple language models in several domains with knowledge boundary.
LLM-based NLG Evaluation: Current Status and Challenges
Feb 02, 2024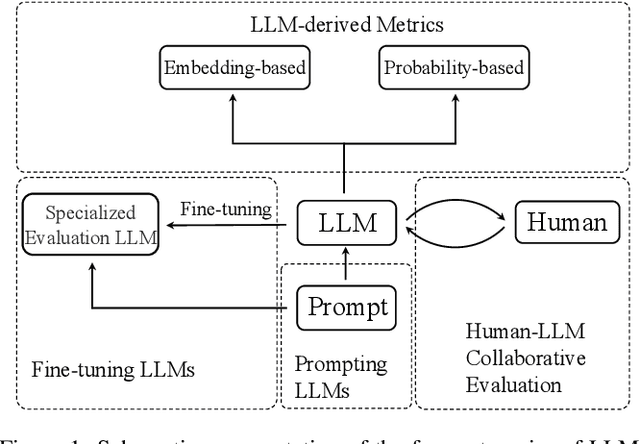
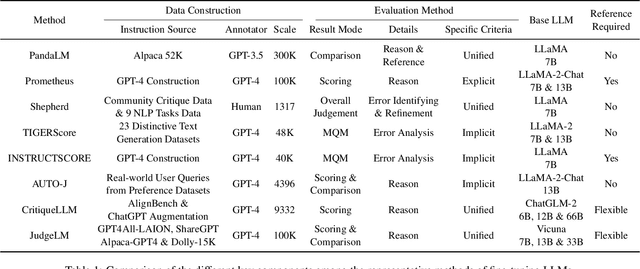

Evaluating natural language generation (NLG) is a vital but challenging problem in artificial intelligence. Traditional evaluation metrics mainly capturing content (e.g. n-gram) overlap between system outputs and references are far from satisfactory, and large language models (LLMs) such as ChatGPT have demonstrated great potential in NLG evaluation in recent years. Various automatic evaluation methods based on LLMs have been proposed, including metrics derived from LLMs, prompting LLMs, and fine-tuning LLMs with labeled evaluation data. In this survey, we first give a taxonomy of LLM-based NLG evaluation methods, and discuss their pros and cons, respectively. We also discuss human-LLM collaboration for NLG evaluation. Lastly, we discuss several open problems in this area and point out future research directions.
How do the resting EEG preprocessing states affect the outcomes of postprocessing?
Oct 22, 2023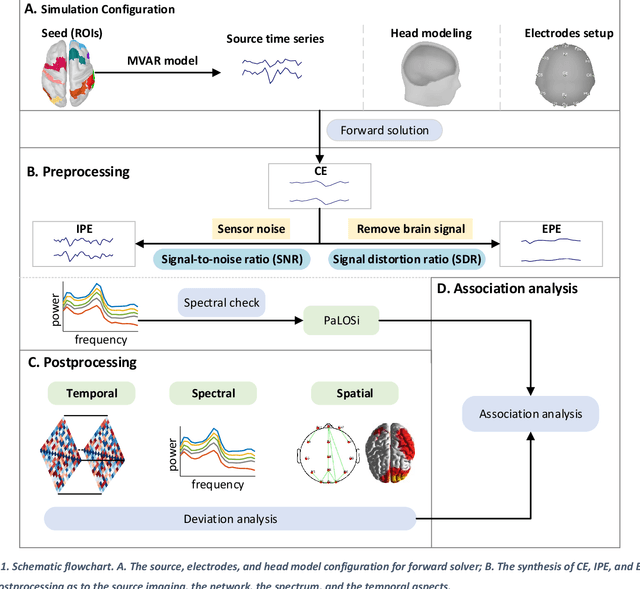
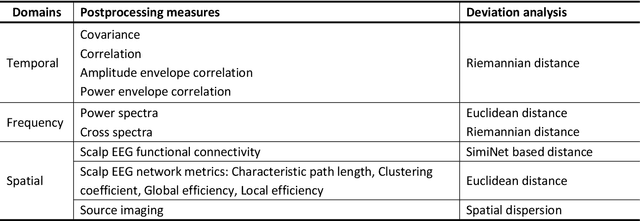
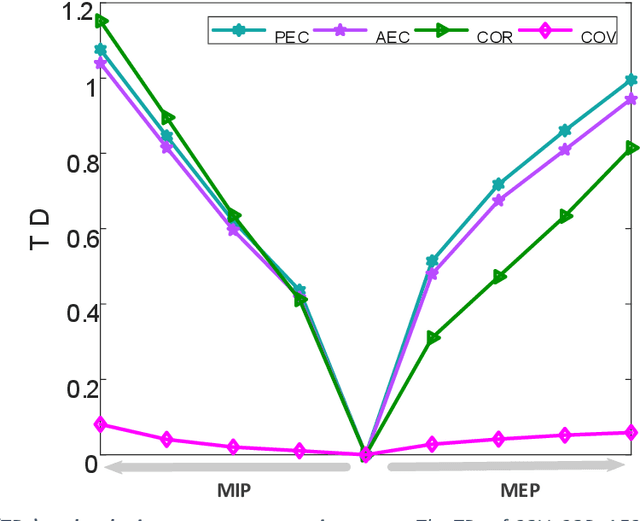
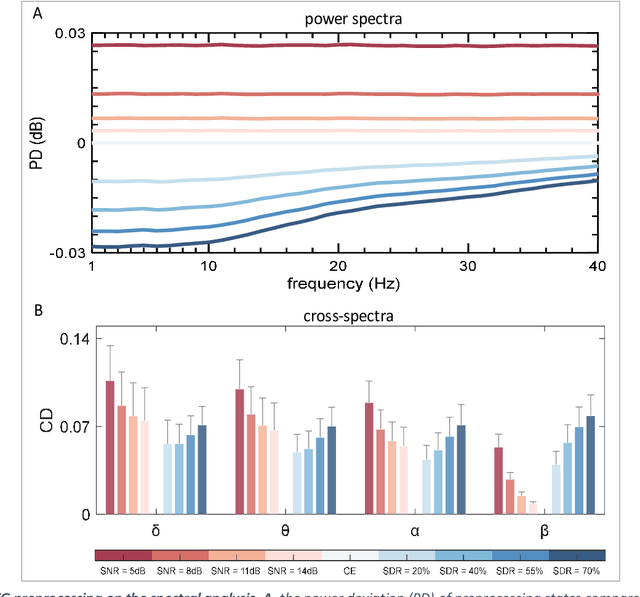
Plenty of artifact removal tools and pipelines have been developed to correct the EEG recordings and discover the values below the waveforms. Without visual inspection from the experts, it is susceptible to derive improper preprocessing states, like the insufficient preprocessed EEG (IPE), and the excessive preprocessed EEG (EPE). However, little is known about the impacts of IPE or EPE on the postprocessing in the frequency, spatial and temporal domains, particularly as to the spectra and the functional connectivity (FC) analysis. Here, the clean EEG (CE) was synthesized as the ground truth based on the New-York head model and the multivariate autoregressive model. Later, the IPE and the EPE were simulated by injecting the Gaussian noise and losing the brain activities, respectively. Then, the impacts on postprocessing were quantified by the deviation caused by the IPE or EPE from the CE as to the 4 temporal statistics, the multichannel power, the cross spectra, the dispersion of source imaging, and the properties of scalp EEG network. Lastly, the association analysis was performed between the PaLOSi metric and the varying trends of postprocessing with the evolution of preprocessing states. This study shed light on how the postprocessing outcomes are affected by the preprocessing states and PaLOSi may be a potential effective quality metric.
Parallel Log Spectra index : a quality metric in large scale resting EEG preprocessing
Oct 18, 2023



Toward large scale electrophysiology data analysis, many preprocessing pipelines are developed to reject artifacts as the prerequisite step before the downstream analysis. A mainstay of these pipelines is based on the data driven approach -- Independent Component Analysis (ICA). Nevertheless, there is little effort put to the preprocessing quality control. In this paper, attentions to this issue were carefully paid by our observation that after running ICA based preprocessing pipeline: some subjects showed approximately Parallel multichannel Log power Spectra (PaLOS), namely, multichannel power spectra are proportional to each other. Firstly, the presence of PaLOS and its implications to connectivity analysis were described by real instance and simulation; secondly, we built its mathematical model and proposed the PaLOS index (PaLOSi) based on the common principal component analysis to detect its presence; thirdly, the performance of PaLOSi was tested on 30094 cases of EEG from 5 databases. The results showed that 1) the PaLOS implies a sole source which is physiologically implausible. 2) PaLOSi can detect the excessive elimination of brain components and is robust in terms of channel number, electrode layout, reference, and the other factors. 3) PaLOSi can output the channel and frequency wise index to help for in-depth check. This paper presented the PaLOS issue in the quality control step after running the preprocessing pipeline and the proposed PaLOSi may serve as a novel data quality metric in the large-scale automatic preprocessing.
Human-like Summarization Evaluation with ChatGPT
Apr 05, 2023



Evaluating text summarization is a challenging problem, and existing evaluation metrics are far from satisfactory. In this study, we explored ChatGPT's ability to perform human-like summarization evaluation using four human evaluation methods on five datasets. We found that ChatGPT was able to complete annotations relatively smoothly using Likert scale scoring, pairwise comparison, Pyramid, and binary factuality evaluation. Additionally, it outperformed commonly used automatic evaluation metrics on some datasets. Furthermore, we discussed the impact of different prompts, compared its performance with that of human evaluation, and analyzed the generated explanations and invalid responses.
How to Describe Images in a More Funny Way? Towards a Modular Approach to Cross-Modal Sarcasm Generation
Nov 20, 2022
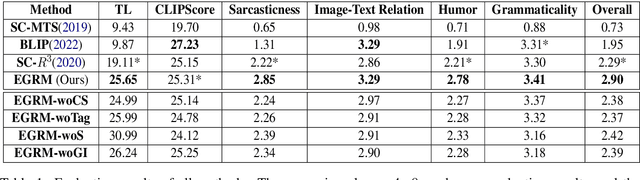
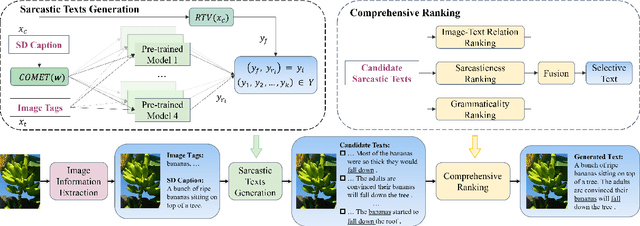

Sarcasm generation has been investigated in previous studies by considering it as a text-to-text generation problem, i.e., generating a sarcastic sentence for an input sentence. In this paper, we study a new problem of cross-modal sarcasm generation (CMSG), i.e., generating a sarcastic description for a given image. CMSG is challenging as models need to satisfy the characteristics of sarcasm, as well as the correlation between different modalities. In addition, there should be some inconsistency between the two modalities, which requires imagination. Moreover, high-quality training data is insufficient. To address these problems, we take a step toward generating sarcastic descriptions from images without paired training data and propose an Extraction-Generation-Ranking based Modular method (EGRM) for cross-model sarcasm generation. Specifically, EGRM first extracts diverse information from an image at different levels and uses the obtained image tags, sentimental descriptive caption, and commonsense-based consequence to generate candidate sarcastic texts. Then, a comprehensive ranking algorithm, which considers image-text relation, sarcasticness, and grammaticality, is proposed to select a final text from the candidate texts. Human evaluation at five criteria on a total of 1200 generated image-text pairs from eight systems and auxiliary automatic evaluation show the superiority of our method.
Push and Pull Search Embedded in an M2M Framework for Solving Constrained Multi-objective Optimization Problems
Jun 02, 2019
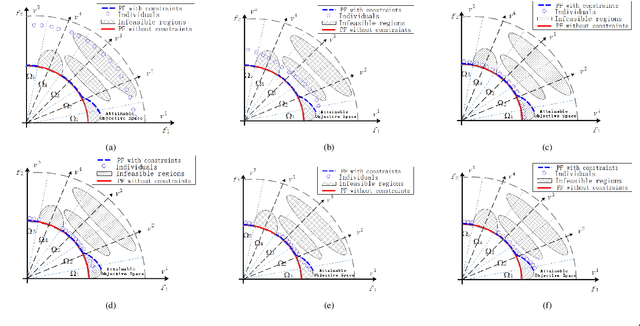

In dealing with constrained multi-objective optimization problems (CMOPs), a key issue of multi-objective evolutionary algorithms (MOEAs) is to balance the convergence and diversity of working populations.
Embedding Push and Pull Search in the Framework of Differential Evolution for Solving Constrained Single-objective Optimization Problems
Dec 16, 2018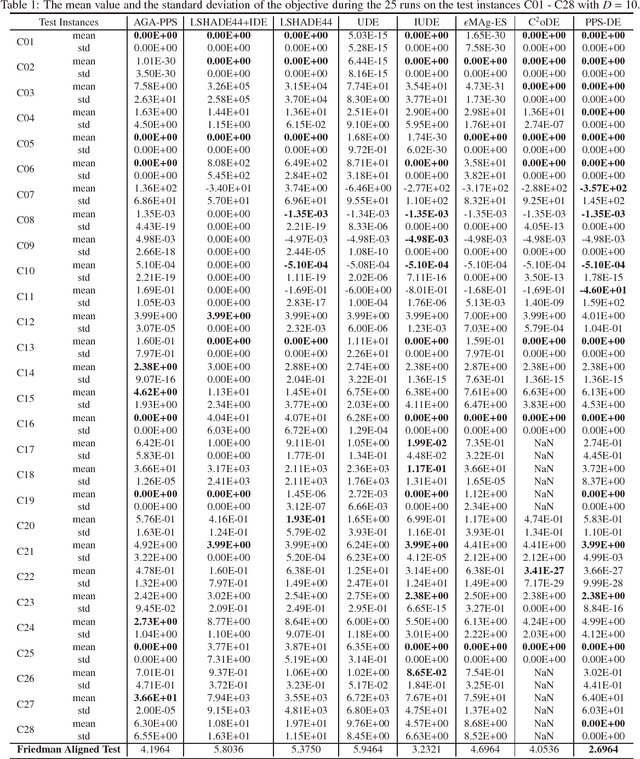
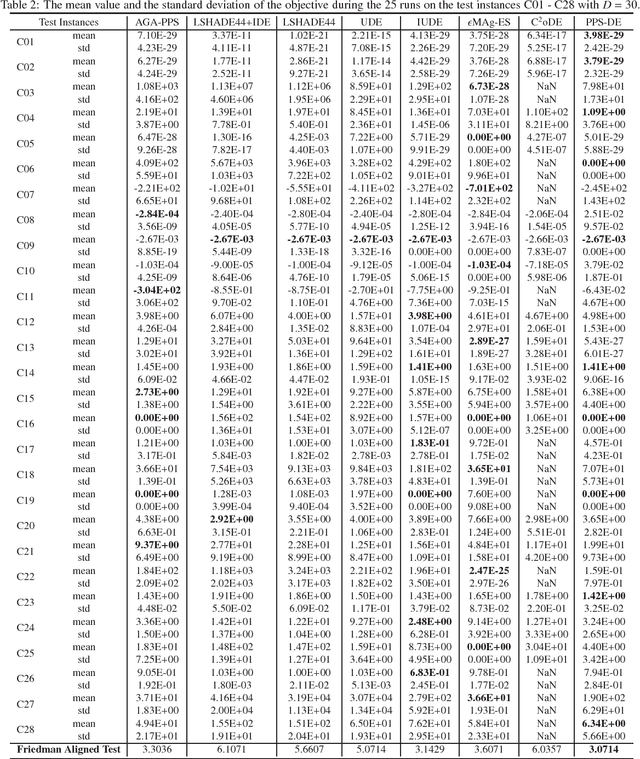
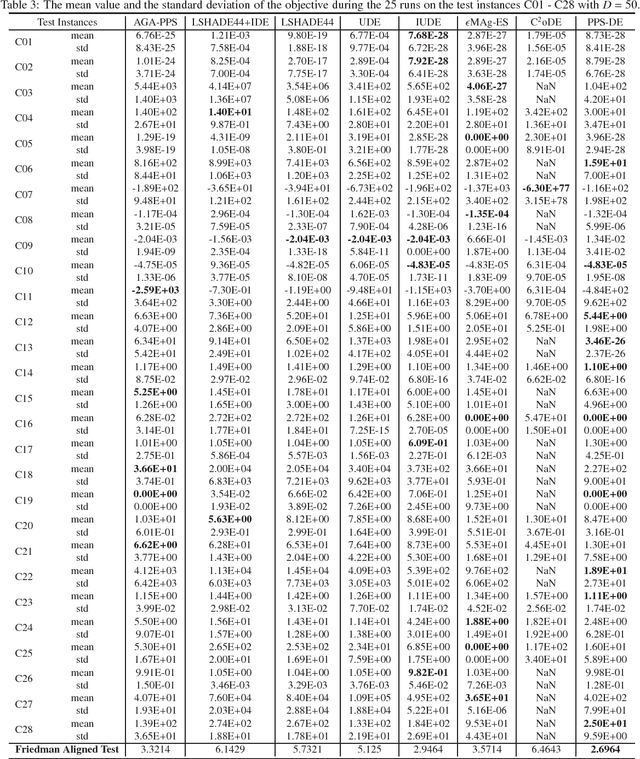
This paper proposes a push and pull search method in the framework of differential evolution (PPS-DE) to solve constrained single-objective optimization problems (CSOPs). More specifically, two sub-populations, including the top and bottom sub-populations, are collaborated with each other to search global optimal solutions efficiently. The top sub-population adopts the pull and pull search (PPS) mechanism to deal with constraints, while the bottom sub-population use the superiority of feasible solutions (SF) technique to deal with constraints. In the top sub-population, the search process is divided into two different stages --- push and pull stages.An adaptive DE variant with three trial vector generation strategies is employed in the proposed PPS-DE. In the top sub-population, all the three trial vector generation strategies are used to generate offsprings, just like in CoDE. In the bottom sub-population, a strategy adaptation, in which the trial vector generation strategies are periodically self-adapted by learning from their experiences in generating promising solutions in the top sub-population, is used to choose a suitable trial vector generation strategy to generate one offspring. Furthermore, a parameter adaptation strategy from LSHADE44 is employed in both sup-populations to generate scale factor $F$ and crossover rate $CR$ for each trial vector generation strategy. Twenty-eight CSOPs with 10-, 30-, and 50-dimensional decision variables provided in the CEC2018 competition on real parameter single objective optimization are optimized by the proposed PPS-DE. The experimental results demonstrate that the proposed PPS-DE has the best performance compared with the other seven state-of-the-art algorithms, including AGA-PPS, LSHADE44, LSHADE44+IDE, UDE, IUDE, $\epsilon$MAg-ES and C$^2$oDE.