 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-based NLG Evaluation: Current Status and Challenges
Paper and Code
Feb 02, 2024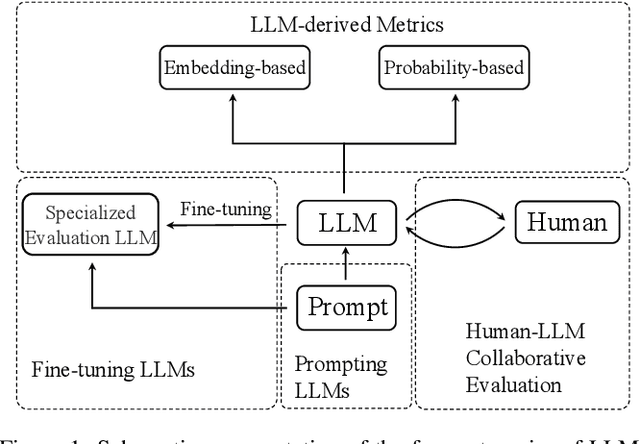
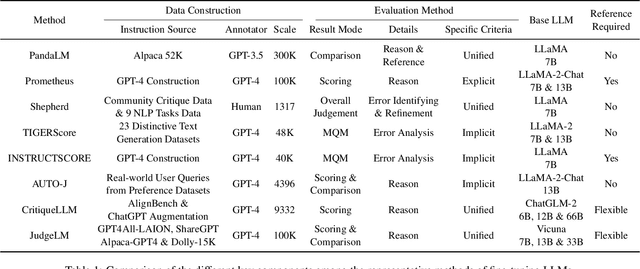

Evaluating natural language generation (NLG) is a vital but challenging problem in artificial intelligence. Traditional evaluation metrics mainly capturing content (e.g. n-gram) overlap between system outputs and references are far from satisfactory, and large language models (LLMs) such as ChatGPT have demonstrated great potential in NLG evaluation in recent years. Various automatic evaluation methods based on LLMs have been proposed, including metrics derived from LLMs, prompting LLMs, and fine-tuning LLMs with labeled evaluation data. In this survey, we first give a taxonomy of LLM-based NLG evaluation methods, and discuss their pros and cons, respectively. We also discuss human-LLM collaboration for NLG evaluation. Lastly, we discuss several open problems in this area and point out future research directions.