 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAM-Body4D: Training-Free 4D Human Body Mesh Recovery from Videos
Dec 09, 2025Human Mesh Recovery (HMR) aims to reconstruct 3D human pose and shape from 2D observations and is fundamental to human-centric understanding in real-world scenarios. While recent image-based HMR methods such as SAM 3D Body achieve strong robustness on in-the-wild images, they rely on per-frame inference when applied to videos, leading to temporal inconsistency and degraded performance under occlusions. We address these issues without extra training by leveraging the inherent human continuity in videos. We propose SAM-Body4D, a training-free framework for temporally consistent and occlusion-robust HMR from videos. We first generate identity-consistent masklets using a promptable video segmentation model, then refine them with an Occlusion-Aware module to recover missing regions. The refined masklets guide SAM 3D Body to produce consistent full-body mesh trajectories, while a padding-based parallel strategy enables efficient multi-human inference. Experimental results demonstrate that SAM-Body4D achieves improved temporal stability and robustness in challenging in-the-wild videos, without any retraining. Our code and demo are available at: https://github.com/gaomingqi/sam-body4d.
ArtiWorld: LLM-Driven Articulation of 3D Objects in Scenes
Nov 18, 2025Building interactive simulators and scalable robot-learning environments requires a large number of articulated assets. However, most existing 3D assets in simulation are rigid, and manually converting them into articulated objects is extremely labor- and cost-intensive. This raises a natural question: can we automatically identify articulable objects in a scene and convert them into articulated assets directly? In this paper, we present ArtiWorld, a scene-aware pipeline that localizes candidate articulable objects from textual scene descriptions and reconstructs executable URDF models that preserve the original geometry. At the core of this pipeline is Arti4URDF, which leverages 3D point cloud, prior knowledge of a large language model (LLM), and a URDF-oriented prompt design to rapidly convert rigid objects into interactive URDF-based articulated objects while maintaining their 3D shape. We evaluate ArtiWorld at three levels: 3D simulated objects, full 3D simulated scenes, and real-world scan scenes. Across all three settings, our method consistently outperforms existing approaches and achieves state-of-the-art performance, while preserving object geometry and correctly capturing object interactivity to produce usable URDF-based articulated models. This provides a practical path toward building interactive, robot-ready simulation environments directly from existing 3D assets. Code and data will be released.
Point Linguist Model: Segment Any Object via Bridged Large 3D-Language Model
Sep 09, 2025
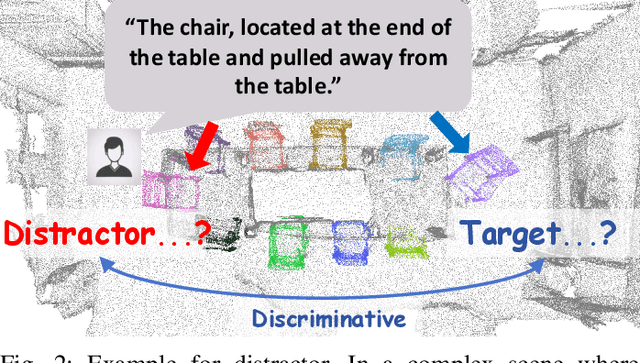


3D object segmentation with Large Language Models (LLMs) has become a prevailing paradigm due to its broad semantics, task flexibility, and strong generalization. However, this paradigm is hindered by representation misalignment: LLMs process high-level semantic tokens, whereas 3D point clouds convey only dense geometric structures. In prior methods, misalignment limits both input and output. At the input stage, dense point patches require heavy pre-alignment, weakening object-level semantics and confusing similar distractors. At the output stage, predictions depend only on dense features without explicit geometric cues, leading to a loss of fine-grained accuracy. To address these limitations, we present the Point Linguist Model (PLM), a general framework that bridges the representation gap between LLMs and dense 3D point clouds without requiring large-scale pre-alignment between 3D-text or 3D-images. Specifically, we introduce Object-centric Discriminative Representation (OcDR), which learns object-centric tokens that capture target semantics and scene relations under a hard negative-aware training objective. This mitigates the misalignment between LLM tokens and 3D points, enhances resilience to distractors, and facilitates semantic-level reasoning within LLMs. For accurate segmentation, we introduce the Geometric Reactivation Decoder (GRD), which predicts masks by combining OcDR tokens carrying LLM-inferred geometry with corresponding dense features, preserving comprehensive dense features throughout the pipeline. Extensive experiments show that PLM achieves significant improvements of +7.3 mIoU on ScanNetv2 and +6.0 mIoU on Multi3DRefer for 3D referring segmentation, with consistent gains across 7 benchmarks spanning 4 different tasks, demonstrating the effectiveness of comprehensive object-centric reasoning for robust 3D understanding.
Unlocking the Potential of Diffusion Priors in Blind Face Restoration
Aug 12, 2025
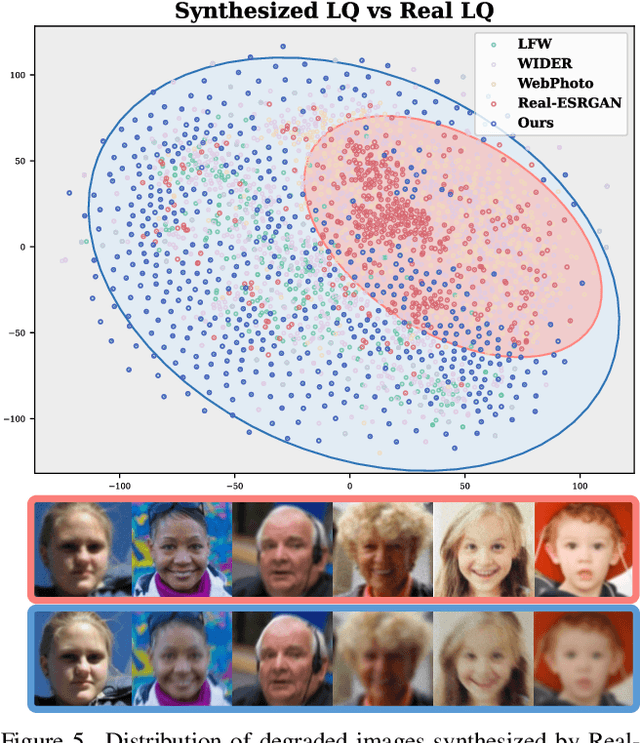
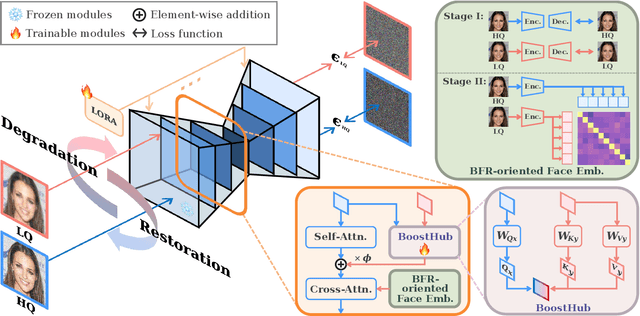
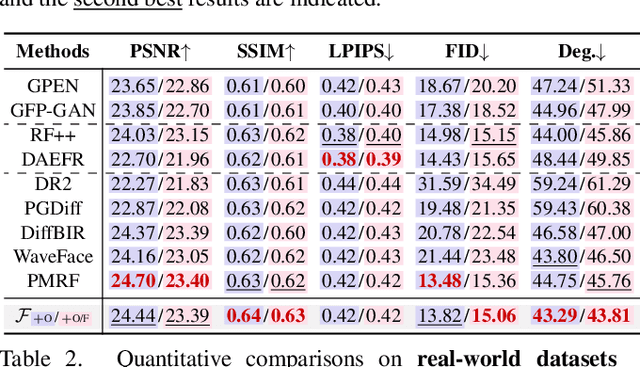
Although diffusion prior is rising as a powerful solution for blind face restoration (BFR), the inherent gap between the vanilla diffusion model and BFR settings hinders its seamless adaptation. The gap mainly stems from the discrepancy between 1) high-quality (HQ) and low-quality (LQ) images and 2) synthesized and real-world images. The vanilla diffusion model is trained on images with no or less degradations, whereas BFR handles moderately to severely degraded images. Additionally, LQ images used for training are synthesized by a naive degradation model with limited degradation patterns, which fails to simulate complex and unknown degradations in real-world scenarios. In this work, we use a unified network FLIPNET that switches between two modes to resolve specific gaps. In Restoration mode, the model gradually integrates BFR-oriented features and face embeddings from LQ images to achieve authentic and faithful face restoration. In Degradation mode, the model synthesizes real-world like degraded images based on the knowledge learned from real-world degradation datasets. Extensive evaluations on benchmark datasets show that our model 1) outperforms previous diffusion prior based BFR methods in terms of authenticity and fidelity, and 2) outperforms the naive degradation model in modeling the real-world degradations.
LLM-driven Indoor Scene Layout Generation via Scaled Human-aligned Data Synthesis and Multi-Stage Preference Optimization
Jun 09, 2025Automatic indoor layout generation has attracted increasing attention due to its potential in interior design, virtual environment construction, and embodied AI. Existing methods fall into two categories: prompt-driven approaches that leverage proprietary LLM services (e.g., GPT APIs) and learning-based methods trained on layout data upon diffusion-based models. Prompt-driven methods often suffer from spatial inconsistency and high computational costs, while learning-based methods are typically constrained by coarse relational graphs and limited datasets, restricting their generalization to diverse room categories. In this paper, we revisit LLM-based indoor layout generation and present 3D-SynthPlace, a large-scale dataset that combines synthetic layouts generated via a 'GPT synthesize, Human inspect' pipeline, upgraded from the 3D-Front dataset. 3D-SynthPlace contains nearly 17,000 scenes, covering four common room types -- bedroom, living room, kitchen, and bathroom -- enriched with diverse objects and high-level spatial annotations. We further introduce OptiScene, a strong open-source LLM optimized for indoor layout generation, fine-tuned based on our 3D-SynthPlace dataset through our two-stage training. For the warum-up stage I, we adopt supervised fine-tuning (SFT), which is taught to first generate high-level spatial descriptions then conditionally predict concrete object placements. For the reinforcing stage II, to better align the generated layouts with human design preferences, we apply multi-turn direct preference optimization (DPO), which significantly improving layout quality and generation success rates. Extensive experiments demonstrate that OptiScene outperforms traditional prompt-driven and learning-based baselines. Moreover, OptiScene shows promising potential in interactive tasks such as scene editing and robot navigation.
THU-Warwick Submission for EPIC-KITCHEN Challenge 2025: Semi-Supervised Video Object Segmentation
Jun 07, 2025In this report, we describe our approach to egocentric video object segmentation. Our method combines large-scale visual pretraining from SAM2 with depth-based geometric cues to handle complex scenes and long-term tracking. By integrating these signals in a unified framework, we achieve strong segmentation performance. On the VISOR test set, our method reaches a J&F score of 90.1%.
ReSurgSAM2: Referring Segment Anything in Surgical Video via Credible Long-term Tracking
May 13, 2025Surgical scene segmentation is critical in computer-assisted surgery and is vital for enhancing surgical quality and patient outcomes. Recently, referring surgical segmentation is emerging, given its advantage of providing surgeons with an interactive experience to segment the target object. However, existing methods are limited by low efficiency and short-term tracking, hindering their applicability in complex real-world surgical scenarios. In this paper, we introduce ReSurgSAM2, a two-stage surgical referring segmentation framework that leverages Segment Anything Model 2 to perform text-referred target detection, followed by tracking with reliable initial frame identification and diversity-driven long-term memory. For the detection stage, we propose a cross-modal spatial-temporal Mamba to generate precise detection and segmentation results. Based on these results, our credible initial frame selection strategy identifies the reliable frame for the subsequent tracking. Upon selecting the initial frame, our method transitions to the tracking stage, where it incorporates a diversity-driven memory mechanism that maintains a credible and diverse memory bank, ensuring consistent long-term tracking. Extensive experiments demonstrate that ReSurgSAM2 achieves substantial improvements in accuracy and efficiency compared to existing methods, operating in real-time at 61.2 FPS. Our code and datasets will be available at https://github.com/jinlab-imvr/ReSurgSAM2.
Few-Shot Referring Video Single- and Multi-Object Segmentation via Cross-Modal Affinity with Instance Sequence Matching
Apr 18, 2025Referring video object segmentation (RVOS) aims to segment objects in videos guided by natural language descriptions. We propose FS-RVOS, a Transformer-based model with two key components: a cross-modal affinity module and an instance sequence matching strategy, which extends FS-RVOS to multi-object segmentation (FS-RVMOS). Experiments show FS-RVOS and FS-RVMOS outperform state-of-the-art methods across diverse benchmarks, demonstrating superior robustness and accuracy.
MMCR: Benchmarking Cross-Source Reasoning in Scientific Papers
Mar 21, 2025



Fully comprehending scientific papers by machines reflects a high level of Artificial General Intelligence, requiring the ability to reason across fragmented and heterogeneous sources of information, presenting a complex and practically significant challenge. While Vision-Language Models (VLMs) have made remarkable strides in various tasks, particularly those involving reasoning with evidence source from single image or text page, their ability to use cross-source information for reasoning remains an open problem. This work presents MMCR, a high-difficulty benchmark designed to evaluate VLMs' capacity for reasoning with cross-source information from scientific papers. The benchmark comprises 276 high-quality questions, meticulously annotated by humans across 7 subjects and 10 task types. Experiments with 18 VLMs demonstrate that cross-source reasoning presents a substantial challenge for existing models. Notably, even the top-performing model, GPT-4o, achieved only 48.55% overall accuracy, with only 20% accuracy in multi-table comprehension tasks, while the second-best model, Qwen2.5-VL-72B, reached 39.86% overall accuracy. Furthermore, we investigated the impact of the Chain-of-Thought (CoT) technique on cross-source reasoning and observed a detrimental effect on small models, whereas larger models demonstrated substantially enhanced performance. These results highlight the pressing need to develop VLMs capable of effectively utilizing cross-source information for reasoning.
Exploring the Multilingual NLG Evaluation Abilities of LLM-Based Evaluators
Mar 06, 2025Previous research has shown that LLMs have potential in multilingual NLG evaluation tasks. However, existing research has not fully explored the differences in the evaluation capabilities of LLMs across different languages. To this end, this study provides a comprehensive analysis of the multilingual evaluation performance of 10 recent LLMs, spanning high-resource and low-resource languages through correlation analysis, perturbation attacks, and fine-tuning. We found that 1) excluding the reference answer from the prompt and using large-parameter LLM-based evaluators leads to better performance across various languages; 2) most LLM-based evaluators show a higher correlation with human judgments in high-resource languages than in low-resource languages; 3) in the languages where they are most sensitive to such attacks, they also tend to exhibit the highest correlation with human judgments; and 4) fine-tuning with data from a particular language yields a broadly consistent enhancement in the model's evaluation performance across diverse languages. Our findings highlight the imbalance in LLMs'evaluation capabilities across different languages and suggest that low-resource language scenarios deserve more attention.