 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShow Me When and Where: Towards Referring Video Object Segmentation in the Wild
Mar 15, 2026Referring video object segmentation (RVOS) has recently generated great popularity in computer vision due to its widespread applications. Existing RVOS setting contains elaborately trimmed videos, with text-referred objects always appearing in all frames, which however fail to fully reflect the realistic challenges of this task. This simplified setting requires RVOS methods to only predict where objects, with no need to show when the objects appear. In this work, we introduce a new setting towards in-the-wild RVOS. To this end, we collect a new benchmark dataset using Youtube Untrimmed videos for RVOS - YoURVOS, which contains 1,120 in-the-wild videos with 7 times more duration and scenes than existing datasets. Our new benchmark challenges RVOS methods to show not only where but also when objects appear in videos. To set a baseline, we propose Object-level Multimodal TransFormers (OMFormer) to tackle the challenges, which are characterized by encoding object-level multimodal interactions for efficient and global spatial-temporal localisation. We demonstrate that previous VOS methods struggle on our YoURVOS benchmark, especially with the increase of target-absent frames, while our OMFormer consistently performs well. Our YoURVOS dataset offers an imperative benchmark, which will push forward the advancement of RVOS methods for practical applications.
RADAR: Closed-Loop Robotic Data Generation via Semantic Planning and Autonomous Causal Environment Reset
Mar 12, 2026The acquisition of large-scale physical interaction data, a critical prerequisite for modern robot learning, is severely bottlenecked by the prohibitive cost and scalability limits of human-in-the-loop collection paradigms. To break this barrier, we introduce Robust Autonomous Data Acquisition for Robotics (RADAR), a fully autonomous, closed-loop data generation engine that completely removes human intervention from the collection cycle. RADAR elegantly divides the cognitive load into a four-module pipeline. Anchored by 2-5 3D human demonstrations as geometric priors, a Vision-Language Model first orchestrates scene-relevant task generation via precise semantic object grounding and skill retrieval. Next, a Graph Neural Network policy translates these subtasks into physical actions via in-context imitation learning. Following execution, the VLM performs automated success evaluation using a structured Visual Question Answering pipeline. Finally, to shatter the bottleneck of manual resets, a Finite State Machine orchestrates an autonomous environment reset and asymmetric data routing mechanism. Driven by simultaneous forward-reverse planning with a strict Last-In, First-Out causal sequence, the system seamlessly restores unstructured workspaces and robustly recovers from execution failures. This continuous brain-cerebellum synergy transforms data collection into a self-sustaining process. Extensive evaluations highlight RADAR's exceptional versatility. In simulation, our framework achieves up to 90% success rates on complex, long-horizon tasks, effortlessly solving challenges where traditional baselines plummet to near-zero performance. In real-world deployments, the system reliably executes diverse, contact-rich skills (e.g., deformable object manipulation) via few-shot adaptation without domain-specific fine-tuning, providing a highly scalable paradigm for robotic data acquisition.
LLM-driven Indoor Scene Layout Generation via Scaled Human-aligned Data Synthesis and Multi-Stage Preference Optimization
Jun 09, 2025Automatic indoor layout generation has attracted increasing attention due to its potential in interior design, virtual environment construction, and embodied AI. Existing methods fall into two categories: prompt-driven approaches that leverage proprietary LLM services (e.g., GPT APIs) and learning-based methods trained on layout data upon diffusion-based models. Prompt-driven methods often suffer from spatial inconsistency and high computational costs, while learning-based methods are typically constrained by coarse relational graphs and limited datasets, restricting their generalization to diverse room categories. In this paper, we revisit LLM-based indoor layout generation and present 3D-SynthPlace, a large-scale dataset that combines synthetic layouts generated via a 'GPT synthesize, Human inspect' pipeline, upgraded from the 3D-Front dataset. 3D-SynthPlace contains nearly 17,000 scenes, covering four common room types -- bedroom, living room, kitchen, and bathroom -- enriched with diverse objects and high-level spatial annotations. We further introduce OptiScene, a strong open-source LLM optimized for indoor layout generation, fine-tuned based on our 3D-SynthPlace dataset through our two-stage training. For the warum-up stage I, we adopt supervised fine-tuning (SFT), which is taught to first generate high-level spatial descriptions then conditionally predict concrete object placements. For the reinforcing stage II, to better align the generated layouts with human design preferences, we apply multi-turn direct preference optimization (DPO), which significantly improving layout quality and generation success rates. Extensive experiments demonstrate that OptiScene outperforms traditional prompt-driven and learning-based baselines. Moreover, OptiScene shows promising potential in interactive tasks such as scene editing and robot navigation.
Masked Language Models are Good Heterogeneous Graph Generalizers
Jun 06, 2025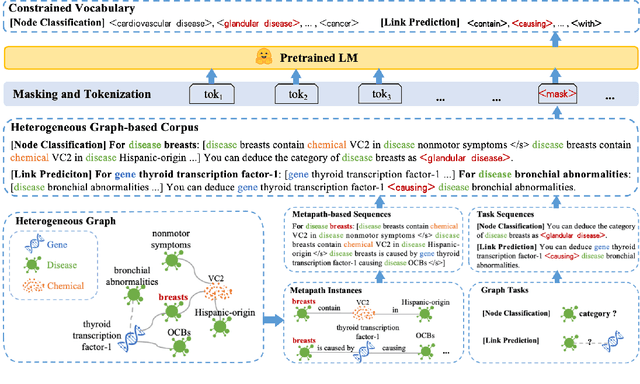
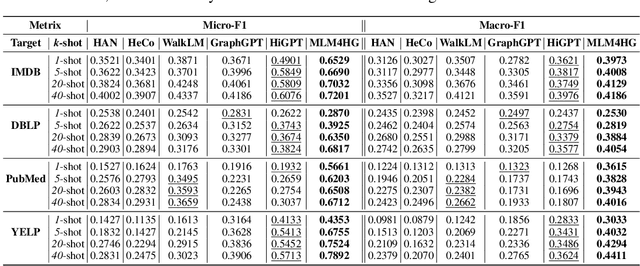
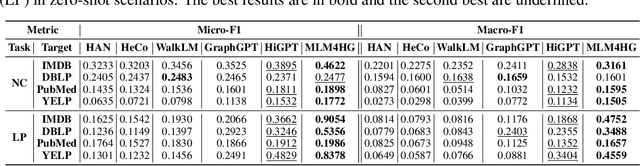
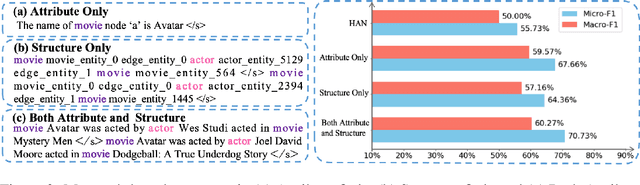
Heterogeneous graph neural networks (HGNNs) excel at capturing structural and semantic information in heterogeneous graphs (HGs), while struggling to generalize across domains and tasks. Recently, some researchers have turned to integrating HGNNs with large language models (LLMs) for more generalizable heterogeneous graph learning. However, these approaches typically extract structural information via HGNNs as HG tokens, and disparities in embedding spaces between HGNNs and LLMs have been shown to bias the LLM's comprehension of HGs. Moreover, as these HG tokens are often derived from node-level tasks, the model's ability to generalize across tasks remains limited. To this end, we propose a simple yet effective Masked Language Modeling-based method, called MLM4HG. MLM4HG introduces metapath-based textual sequences instead of HG tokens to extract structural and semantic information inherent in HGs, and designs customized textual templates to unify different graph tasks into a coherent cloze-style "mask" token prediction paradigm. Specifically, MLM4HG first converts HGs from various domains to texts based on metapaths, and subsequently combines them with the unified task texts to form a HG-based corpus. Moreover, the corpus is fed into a pretrained LM for fine-tuning with a constrained target vocabulary, enabling the fine-tuned LM to generalize to unseen target HGs. Extensive cross-domain and multi-task experiments on four real-world datasets demonstrate the superior generalization performance of MLM4HG over state-of-the-art methods in both few-shot and zero-shot scenarios. Our code is available at https://github.com/BUPT-GAMMA/MLM4HG.
RefComp: A Reference-guided Unified Framework for Unpaired Point Cloud Completion
Apr 18, 2025The unpaired point cloud completion task aims to complete a partial point cloud by using models trained with no ground truth. Existing unpaired point cloud completion methods are class-aware, i.e., a separate model is needed for each object class. Since they have limited generalization capabilities, these methods perform poorly in real-world scenarios when confronted with a wide range of point clouds of generic 3D objects. In this paper, we propose a novel unpaired point cloud completion framework, namely the Reference-guided Completion (RefComp) framework, which attains strong performance in both the class-aware and class-agnostic training settings. The RefComp framework transforms the unpaired completion problem into a shape translation problem, which is solved in the latent feature space of the partial point clouds. To this end, we introduce the use of partial-complete point cloud pairs, which are retrieved by using the partial point cloud to be completed as a template. These point cloud pairs are used as reference data to guide the completion process. Our RefComp framework uses a reference branch and a target branch with shared parameters for shape fusion and shape translation via a Latent Shape Fusion Module (LSFM) to enhance the structural features along the completion pipeline. Extensive experiments demonstrate that the RefComp framework achieves not only state-of-the-art performance in the class-aware training setting but also competitive results in the class-agnostic training setting on both virtual scans and real-world datasets.
CoLLM: A Large Language Model for Composed Image Retrieval
Mar 25, 2025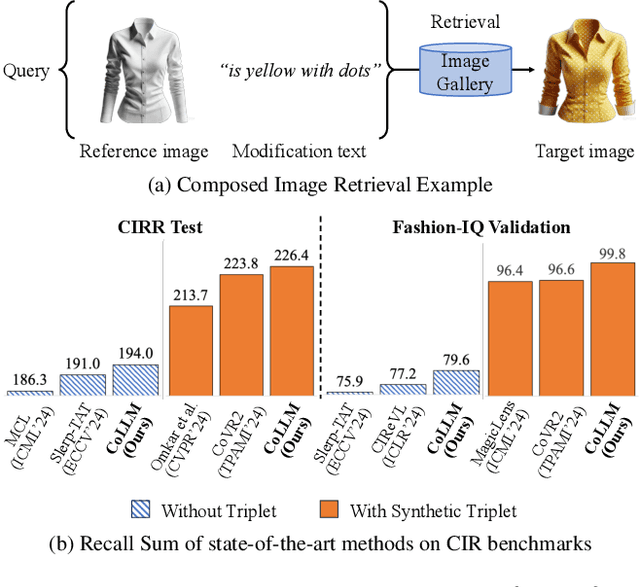
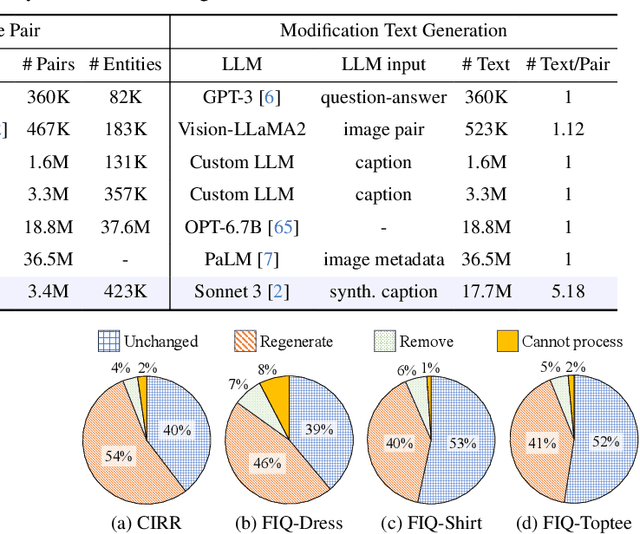
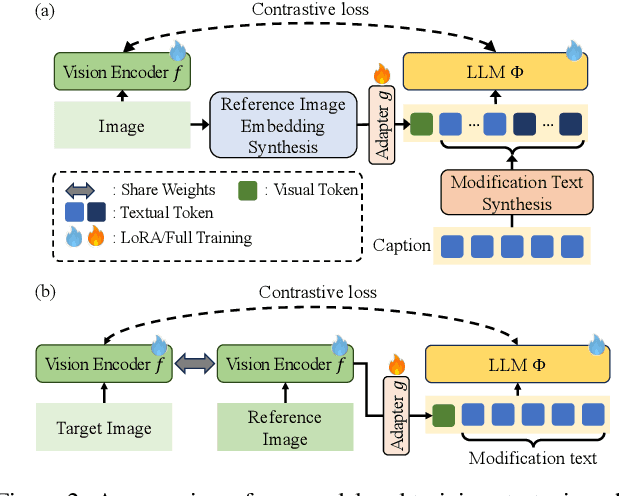
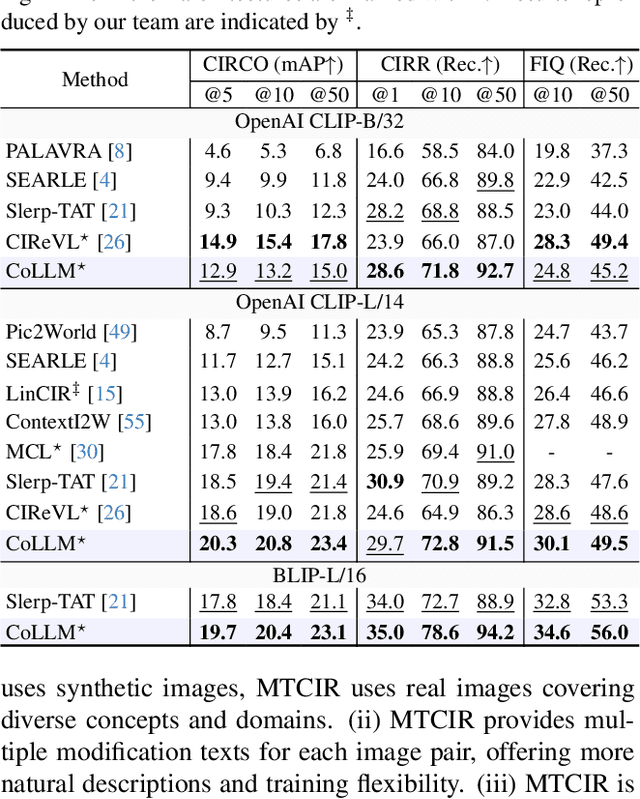
Composed Image Retrieval (CIR) is a complex task that aims to retrieve images based on a multimodal query. Typical training data consists of triplets containing a reference image, a textual description of desired modifications, and the target image, which are expensive and time-consuming to acquire. The scarcity of CIR datasets has led to zero-shot approaches utilizing synthetic triplets or leveraging vision-language models (VLMs) with ubiquitous web-crawled image-caption pairs. However, these methods have significant limitations: synthetic triplets suffer from limited scale, lack of diversity, and unnatural modification text, while image-caption pairs hinder joint embedding learning of the multimodal query due to the absence of triplet data. Moreover, existing approaches struggle with complex and nuanced modification texts that demand sophisticated fusion and understanding of vision and language modalities. We present CoLLM, a one-stop framework that effectively addresses these limitations. Our approach generates triplets on-the-fly from image-caption pairs, enabling supervised training without manual annotation. We leverage Large Language Models (LLMs) to generate joint embeddings of reference images and modification texts, facilitating deeper multimodal fusion. Additionally, we introduce Multi-Text CIR (MTCIR), a large-scale dataset comprising 3.4M samples, and refine existing CIR benchmarks (CIRR and Fashion-IQ) to enhance evaluation reliability. Experimental results demonstrate that CoLLM achieves state-of-the-art performance across multiple CIR benchmarks and settings. MTCIR yields competitive results, with up to 15% performance improvement. Our refined benchmarks provide more reliable evaluation metrics for CIR models, contributing to the advancement of this important field.
GIFT: Generated Indoor video frames for Texture-less point tracking
Mar 17, 2025
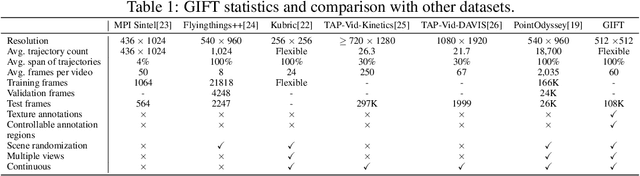
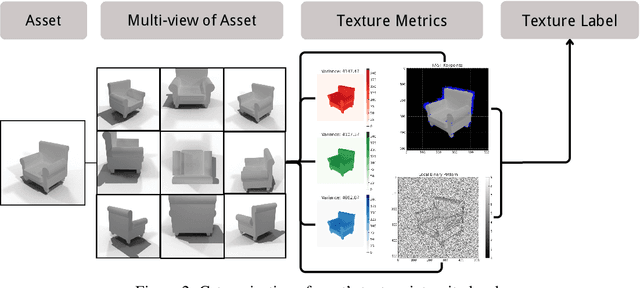
Point tracking is becoming a powerful solver for motion estimation and video editing. Compared to classical feature matching, point tracking methods have the key advantage of robustly tracking points under complex camera motion trajectories and over extended periods. However, despite certain improvements in methodologies, current point tracking methods still struggle to track any position in video frames, especially in areas that are texture-less or weakly textured. In this work, we first introduce metrics for evaluating the texture intensity of a 3D object. Using these metrics, we classify the 3D models in ShapeNet into three levels of texture intensity and create GIFT, a challenging synthetic benchmark comprising 1800 indoor video sequences with rich annotations. Unlike existing datasets that assign ground truth points arbitrarily, GIFT precisely anchors ground truth on classified target objects, ensuring that each video corresponds to a specific texture intensity level. Furthermore, we comprehensively evaluate current methods on GIFT to assess their performance across different texture intensity levels and analyze the impact of texture on point tracking.
Bringing Multimodality to Amazon Visual Search System
Dec 17, 2024



Image to image matching has been well studied in the computer vision community. Previous studies mainly focus on training a deep metric learning model matching visual patterns between the query image and gallery images. In this study, we show that pure image-to-image matching suffers from false positives caused by matching to local visual patterns. To alleviate this issue, we propose to leverage recent advances in vision-language pretraining research. Specifically, we introduce additional image-text alignment losses into deep metric learning, which serve as constraints to the image-to-image matching loss. With additional alignments between the text (e.g., product title) and image pairs, the model can learn concepts from both modalities explicitly, which avoids matching low-level visual features. We progressively develop two variants, a 3-tower and a 4-tower model, where the latter takes one more short text query input. Through extensive experiments, we show that this change leads to a substantial improvement to the image to image matching problem. We further leveraged this model for multimodal search, which takes both image and reformulation text queries to improve search quality. Both offline and online experiments show strong improvements on the main metrics. Specifically, we see 4.95% relative improvement on image matching click through rate with the 3-tower model and 1.13% further improvement from the 4-tower model.
Agri-LLaVA: Knowledge-Infused Large Multimodal Assistant on Agricultural Pests and Diseases
Dec 03, 2024



In the general domain, large multimodal models (LMMs) have achieved significant advancements, yet challenges persist in applying them to specific fields, especially agriculture. As the backbone of the global economy, agriculture confronts numerous challenges, with pests and diseases being particularly concerning due to their complexity, variability, rapid spread, and high resistance. This paper specifically addresses these issues. We construct the first multimodal instruction-following dataset in the agricultural domain, covering over 221 types of pests and diseases with approximately 400,000 data entries. This dataset aims to explore and address the unique challenges in pest and disease control. Based on this dataset, we propose a knowledge-infused training method to develop Agri-LLaVA, an agricultural multimodal conversation system. To accelerate progress in this field and inspire more researchers to engage, we design a diverse and challenging evaluation benchmark for agricultural pests and diseases. Experimental results demonstrate that Agri-LLaVA excels in agricultural multimodal conversation and visual understanding, providing new insights and approaches to address agricultural pests and diseases. By open-sourcing our dataset and model, we aim to promote research and development in LMMs within the agricultural domain and make significant contributions to tackle the challenges of agricultural pests and diseases. All resources can be found at https://github.com/Kki2Eve/Agri-LLaVA.
PlantCamo: Plant Camouflage Detection
Oct 23, 2024


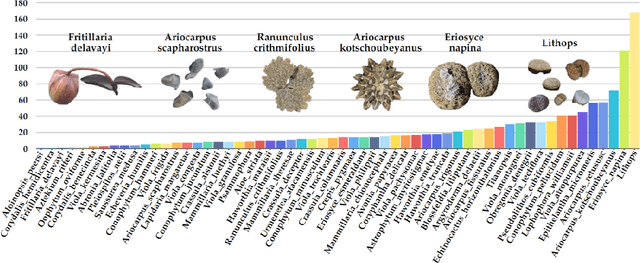
Camouflaged Object Detection (COD) aims to detect objects with camouflaged properties. Although previous studies have focused on natural (animals and insects) and unnatural (artistic and synthetic) camouflage detection, plant camouflage has been neglected. However, plant camouflage plays a vital role in natural camouflage. Therefore, this paper introduces a new challenging problem of Plant Camouflage Detection (PCD). To address this problem, we introduce the PlantCamo dataset, which comprises 1,250 images with camouflaged plants representing 58 object categories in various natural scenes. To investigate the current status of plant camouflage detection, we conduct a large-scale benchmark study using 20+ cutting-edge COD models on the proposed dataset. Due to the unique characteristics of plant camouflage, including holes and irregular borders, we developed a new framework, named PCNet, dedicated to PCD. Our PCNet surpasses performance thanks to its multi-scale global feature enhancement and refinement. Finally, we discuss the potential applications and insights, hoping this work fills the gap in fine-grained COD research and facilitates further intelligent ecology research. All resources will be available on https://github.com/yjybuaa/PlantCamo.