 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA0: An Affordance-Aware Hierarchical Model for General Robotic Manipulation
Apr 21, 2025



Robotic manipulation faces critical challenges in understanding spatial affordances--the "where" and "how" of object interactions--essential for complex manipulation tasks like wiping a board or stacking objects. Existing methods, including modular-based and end-to-end approaches, often lack robust spatial reasoning capabilities. Unlike recent point-based and flow-based affordance methods that focus on dense spatial representations or trajectory modeling, we propose A0, a hierarchical affordance-aware diffusion model that decomposes manipulation tasks into high-level spatial affordance understanding and low-level action execution. A0 leverages the Embodiment-Agnostic Affordance Representation, which captures object-centric spatial affordances by predicting contact points and post-contact trajectories. A0 is pre-trained on 1 million contact points data and fine-tuned on annotated trajectories, enabling generalization across platforms. Key components include Position Offset Attention for motion-aware feature extraction and a Spatial Information Aggregation Layer for precise coordinate mapping. The model's output is executed by the action execution module. Experiments on multiple robotic systems (Franka, Kinova, Realman, and Dobot) demonstrate A0's superior performance in complex tasks, showcasing its efficiency, flexibility, and real-world applicability.
GIFT: Generated Indoor video frames for Texture-less point tracking
Mar 17, 2025
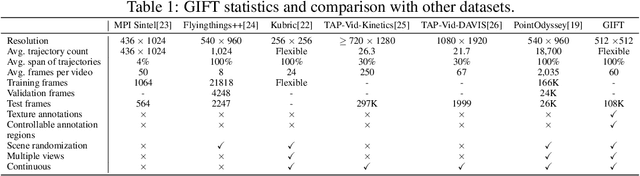
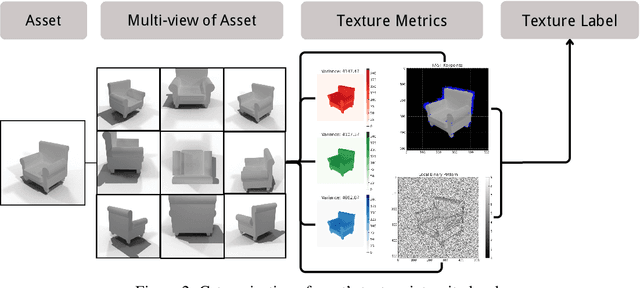
Point tracking is becoming a powerful solver for motion estimation and video editing. Compared to classical feature matching, point tracking methods have the key advantage of robustly tracking points under complex camera motion trajectories and over extended periods. However, despite certain improvements in methodologies, current point tracking methods still struggle to track any position in video frames, especially in areas that are texture-less or weakly textured. In this work, we first introduce metrics for evaluating the texture intensity of a 3D object. Using these metrics, we classify the 3D models in ShapeNet into three levels of texture intensity and create GIFT, a challenging synthetic benchmark comprising 1800 indoor video sequences with rich annotations. Unlike existing datasets that assign ground truth points arbitrarily, GIFT precisely anchors ground truth on classified target objects, ensuring that each video corresponds to a specific texture intensity level. Furthermore, we comprehensively evaluate current methods on GIFT to assess their performance across different texture intensity levels and analyze the impact of texture on point tracking.