 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge\textsc{NaVIDA}: Vision-Language Navigation with Inverse Dynamics Augmentation
Jan 26, 2026Vision-and-Language Navigation (VLN) requires agents to interpret natural language instructions and act coherently in visually rich environments. However, most existing methods rely on reactive state-action mappings without explicitly modeling how actions causally transform subsequent visual observations. Lacking such vision-action causality, agents cannot anticipate the visual changes induced by its own actions, leading to unstable behaviors, weak generalization, and cumulative error along trajectory. To address these issues, we introduce \textsc{NaVIDA} (\textbf{Nav}igation with \textbf{I}nverse \textbf{D}ynamics \textbf{A}ugmentation), a unified VLN framework that couples policy learning with action-grounded visual dynamics and adaptive execution. \textsc{NaVIDA} augments training with chunk-based inverse-dynamics supervision to learn causal relationship between visual changes and corresponding actions. To structure this supervision and extend the effective planning range, \textsc{NaVIDA} employs hierarchical probabilistic action chunking (HPAC), which organizes trajectories into multi-step chunks and provides discriminative, longer-range visual-change cues. To further curb error accumulation and stabilize behavior at inference, an entropy-guided mechanism adaptively sets the execution horizon of action chunks. Extensive experiments show that \textsc{NaVIDA} achieves superior navigation performance compared to state-of-the-art methods with fewer parameters (3B vs. 8B). Real-world robot evaluations further validate the practical feasibility and effectiveness of our approach. Code and data will be available upon acceptance.
MoFu: Scale-Aware Modulation and Fourier Fusion for Multi-Subject Video Generation
Dec 26, 2025Multi-subject video generation aims to synthesize videos from textual prompts and multiple reference images, ensuring that each subject preserves natural scale and visual fidelity. However, current methods face two challenges: scale inconsistency, where variations in subject size lead to unnatural generation, and permutation sensitivity, where the order of reference inputs causes subject distortion. In this paper, we propose MoFu, a unified framework that tackles both challenges. For scale inconsistency, we introduce Scale-Aware Modulation (SMO), an LLM-guided module that extracts implicit scale cues from the prompt and modulates features to ensure consistent subject sizes. To address permutation sensitivity, we present a simple yet effective Fourier Fusion strategy that processes the frequency information of reference features via the Fast Fourier Transform to produce a unified representation. Besides, we design a Scale-Permutation Stability Loss to jointly encourage scale-consistent and permutation-invariant generation. To further evaluate these challenges, we establish a dedicated benchmark with controlled variations in subject scale and reference permutation. Extensive experiments demonstrate that MoFu significantly outperforms existing methods in preserving natural scale, subject fidelity, and overall visual quality.
GLaD: Geometric Latent Distillation for Vision-Language-Action Models
Dec 10, 2025
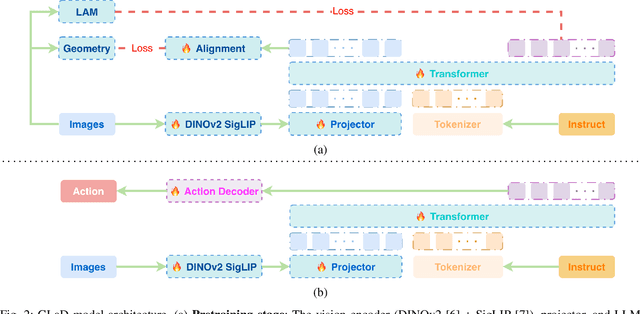
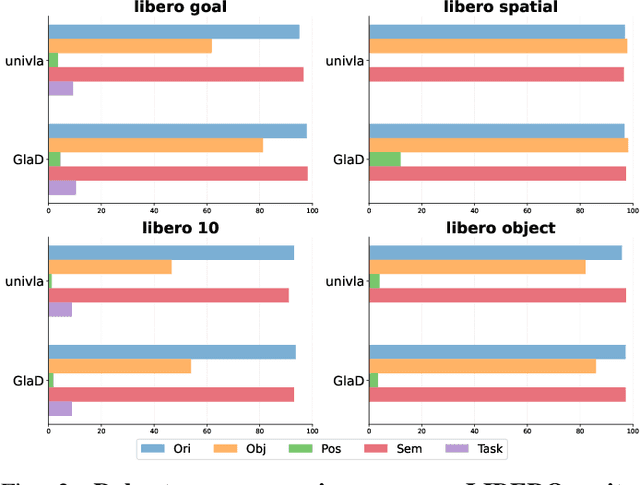

Most existing Vision-Language-Action (VLA) models rely primarily on RGB information, while ignoring geometric cues crucial for spatial reasoning and manipulation. In this work, we introduce GLaD, a geometry-aware VLA framework that incorporates 3D geometric priors during pretraining through knowledge distillation. Rather than distilling geometric features solely into the vision encoder, we align the LLM's hidden states corresponding to visual tokens with features from a frozen geometry-aware vision transformer (VGGT), ensuring that geometric understanding is deeply integrated into the multimodal representations that drive action prediction. Pretrained on the Bridge dataset with this geometry distillation mechanism, GLaD achieves 94.1% average success rate across four LIBERO task suites, outperforming UniVLA (92.5%) which uses identical pretraining data. These results validate that geometry-aware pretraining enhances spatial reasoning and policy generalization without requiring explicit depth sensors or 3D annotations.
Explicit Temporal-Semantic Modeling for Dense Video Captioning via Context-Aware Cross-Modal Interaction
Nov 13, 2025Dense video captioning jointly localizes and captions salient events in untrimmed videos. Recent methods primarily focus on leveraging additional prior knowledge and advanced multi-task architectures to achieve competitive performance. However, these pipelines rely on implicit modeling that uses frame-level or fragmented video features, failing to capture the temporal coherence across event sequences and comprehensive semantics within visual contexts. To address this, we propose an explicit temporal-semantic modeling framework called Context-Aware Cross-Modal Interaction (CACMI), which leverages both latent temporal characteristics within videos and linguistic semantics from text corpus. Specifically, our model consists of two core components: Cross-modal Frame Aggregation aggregates relevant frames to extract temporally coherent, event-aligned textual features through cross-modal retrieval; and Context-aware Feature Enhancement utilizes query-guided attention to integrate visual dynamics with pseudo-event semantics. Extensive experiments on the ActivityNet Captions and YouCook2 datasets demonstrate that CACMI achieves the state-of-the-art performance on dense video captioning task.
CurriFlow: Curriculum-Guided Depth Fusion with Optical Flow-Based Temporal Alignment for 3D Semantic Scene Completion
Oct 14, 2025Semantic Scene Completion (SSC) aims to infer complete 3D geometry and semantics from monocular images, serving as a crucial capability for camera-based perception in autonomous driving. However, existing SSC methods relying on temporal stacking or depth projection often lack explicit motion reasoning and struggle with occlusions and noisy depth supervision. We propose CurriFlow, a novel semantic occupancy prediction framework that integrates optical flow-based temporal alignment with curriculum-guided depth fusion. CurriFlow employs a multi-level fusion strategy to align segmentation, visual, and depth features across frames using pre-trained optical flow, thereby improving temporal consistency and dynamic object understanding. To enhance geometric robustness, a curriculum learning mechanism progressively transitions from sparse yet accurate LiDAR depth to dense but noisy stereo depth during training, ensuring stable optimization and seamless adaptation to real-world deployment. Furthermore, semantic priors from the Segment Anything Model (SAM) provide category-agnostic supervision, strengthening voxel-level semantic learning and spatial consistency. Experiments on the SemanticKITTI benchmark demonstrate that CurriFlow achieves state-of-the-art performance with a mean IoU of 16.9, validating the effectiveness of our motion-guided and curriculum-aware design for camera-based 3D semantic scene completion.
ActiveVLN: Towards Active Exploration via Multi-Turn RL in Vision-and-Language Navigation
Sep 16, 2025The Vision-and-Language Navigation (VLN) task requires an agent to follow natural language instructions and navigate through complex environments. Existing MLLM-based VLN methods primarily rely on imitation learning (IL) and often use DAgger for post-training to mitigate covariate shift. While effective, these approaches incur substantial data collection and training costs. Reinforcement learning (RL) offers a promising alternative. However, prior VLN RL methods lack dynamic interaction with the environment and depend on expert trajectories for reward shaping, rather than engaging in open-ended active exploration. This restricts the agent's ability to discover diverse and plausible navigation routes. To address these limitations, we propose ActiveVLN, a VLN framework that explicitly enables active exploration through multi-turn RL. In the first stage, a small fraction of expert trajectories is used for IL to bootstrap the agent. In the second stage, the agent iteratively predicts and executes actions, automatically collects diverse trajectories, and optimizes multiple rollouts via the GRPO objective. To further improve RL efficiency, we introduce a dynamic early-stopping strategy to prune long-tail or likely failed trajectories, along with additional engineering optimizations. Experiments show that ActiveVLN achieves the largest performance gains over IL baselines compared to both DAgger-based and prior RL-based post-training methods, while reaching competitive performance with state-of-the-art approaches despite using a smaller model. Code and data will be released soon.
$\mathcal{P}^3$: Toward Versatile Embodied Agents
Aug 09, 2025Embodied agents have shown promising generalization capabilities across diverse physical environments, making them essential for a wide range of real-world applications. However, building versatile embodied agents poses critical challenges due to three key issues: dynamic environment perception, open-ended tool usage, and complex multi-task planning. Most previous works rely solely on feedback from tool agents to perceive environmental changes and task status, which limits adaptability to real-time dynamics, causes error accumulation, and restricts tool flexibility. Furthermore, multi-task scheduling has received limited attention, primarily due to the inherent complexity of managing task dependencies and balancing competing priorities in dynamic and complex environments. To overcome these challenges, we introduce $\mathcal{P}^3$, a unified framework that integrates real-time perception and dynamic scheduling. Specifically, $\mathcal{P}^3$ enables 1) \textbf Perceive relevant task information actively from the environment, 2) \textbf Plug and utilize any tool without feedback requirement, and 3) \textbf Plan multi-task execution based on prioritizing urgent tasks and dynamically adjusting task order based on dependencies. Extensive real-world experiments show that our approach bridges the gap between benchmarks and practical deployment, delivering highly transferable, general-purpose embodied agents. Code and data will be released soon.
3D-MoRe: Unified Modal-Contextual Reasoning for Embodied Question Answering
Jul 16, 2025
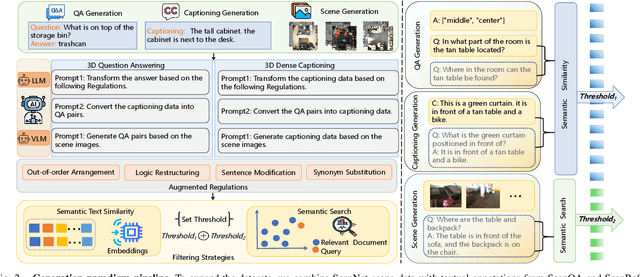


With the growing need for diverse and scalable data in indoor scene tasks, such as question answering and dense captioning, we propose 3D-MoRe, a novel paradigm designed to generate large-scale 3D-language datasets by leveraging the strengths of foundational models. The framework integrates key components, including multi-modal embedding, cross-modal interaction, and a language model decoder, to process natural language instructions and 3D scene data. This approach facilitates enhanced reasoning and response generation in complex 3D environments. Using the ScanNet 3D scene dataset, along with text annotations from ScanQA and ScanRefer, 3D-MoRe generates 62,000 question-answer (QA) pairs and 73,000 object descriptions across 1,513 scenes. We also employ various data augmentation techniques and implement semantic filtering to ensure high-quality data. Experiments on ScanQA demonstrate that 3D-MoRe significantly outperforms state-of-the-art baselines, with the CIDEr score improving by 2.15\%. Similarly, on ScanRefer, our approach achieves a notable increase in CIDEr@0.5 by 1.84\%, highlighting its effectiveness in both tasks. Our code and generated datasets will be publicly released to benefit the community, and both can be accessed on the https://3D-MoRe.github.io.
PhyBlock: A Progressive Benchmark for Physical Understanding and Planning via 3D Block Assembly
Jun 10, 2025While vision-language models (VLMs) have demonstrated promising capabilities in reasoning and planning for embodied agents, their ability to comprehend physical phenomena, particularly within structured 3D environments, remains severely limited. To close this gap, we introduce PhyBlock, a progressive benchmark designed to assess VLMs on physical understanding and planning through robotic 3D block assembly tasks. PhyBlock integrates a novel four-level cognitive hierarchy assembly task alongside targeted Visual Question Answering (VQA) samples, collectively aimed at evaluating progressive spatial reasoning and fundamental physical comprehension, including object properties, spatial relationships, and holistic scene understanding. PhyBlock includes 2600 block tasks (400 assembly tasks, 2200 VQA tasks) and evaluates models across three key dimensions: partial completion, failure diagnosis, and planning robustness. We benchmark 21 state-of-the-art VLMs, highlighting their strengths and limitations in physically grounded, multi-step planning. Our empirical findings indicate that the performance of VLMs exhibits pronounced limitations in high-level planning and reasoning capabilities, leading to a notable decline in performance for the growing complexity of the tasks. Error analysis reveals persistent difficulties in spatial orientation and dependency reasoning. Surprisingly, chain-of-thought prompting offers minimal improvements, suggesting spatial tasks heavily rely on intuitive model comprehension. We position PhyBlock as a unified testbed to advance embodied reasoning, bridging vision-language understanding and real-world physical problem-solving.
SAMamba: Adaptive State Space Modeling with Hierarchical Vision for Infrared Small Target Detection
May 29, 2025Infrared small target detection (ISTD) is vital for long-range surveillance in military, maritime, and early warning applications. ISTD is challenged by targets occupying less than 0.15% of the image and low distinguishability from complex backgrounds. Existing deep learning methods often suffer from information loss during downsampling and inefficient global context modeling. This paper presents SAMamba, a novel framework integrating SAM2's hierarchical feature learning with Mamba's selective sequence modeling. Key innovations include: (1) A Feature Selection Adapter (FS-Adapter) for efficient natural-to-infrared domain adaptation via dual-stage selection (token-level with a learnable task embedding and channel-wise adaptive transformations); (2) A Cross-Channel State-Space Interaction (CSI) module for efficient global context modeling with linear complexity using selective state space modeling; and (3) A Detail-Preserving Contextual Fusion (DPCF) module that adaptively combines multi-scale features with a gating mechanism to balance high-resolution and low-resolution feature contributions. SAMamba addresses core ISTD challenges by bridging the domain gap, maintaining fine-grained details, and efficiently modeling long-range dependencies. Experiments on NUAA-SIRST, IRSTD-1k, and NUDT-SIRST datasets show SAMamba significantly outperforms state-of-the-art methods, especially in challenging scenarios with heterogeneous backgrounds and varying target scales. Code: https://github.com/zhengshuchen/SAMamba.