 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantitative Video World Model Evaluation for Geometric-Consistency
May 14, 2026Generative video models are increasingly studied as implicit world models, yet evaluating whether they produce physically plausible 3D structure and motion remains challenging. Most existing video evaluation pipelines rely heavily on human judgment or learned graders, which can be subjective and weakly diagnostic for geometric failures. We introduce PDI-Bench (Perspective Distortion Index), a quantitative framework for auditing geometric coherence in generated videos. Given a generated clip, we obtain object-centric observations via segmentation and point tracking (e.g., SAM 2, MegaSaM, and CoTracker3), lift them to 3D world-space coordinates via monocular reconstruction, and compute a set of projective-geometry residuals capturing three failure dimensions: scale-depth alignment, 3D motion consistency, and 3D structural rigidity. To support systematic evaluation, we build PDI-Dataset, covering diverse scenarios designed to stress these geometric constraints. Across state-of-the-art video generators, PDI reveals consistent geometry-specific failure modes that are not captured by common perceptual metrics, and provides a diagnostic signal for progress toward physically grounded video generation and physical world model. Our code and dataset can be found at https://pdi-bench.github.io/.
Contrastive Weak-to-strong Generalization
Oct 09, 2025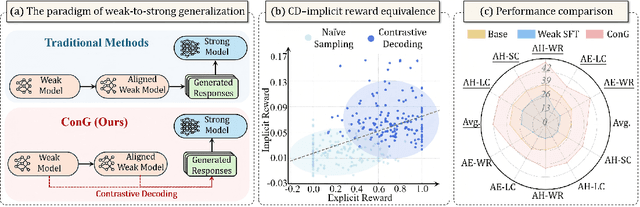
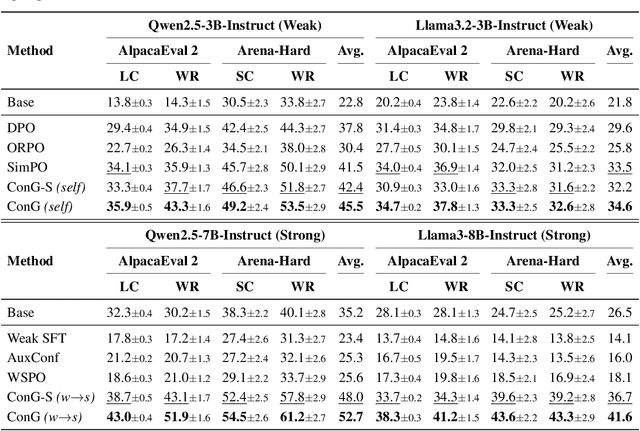
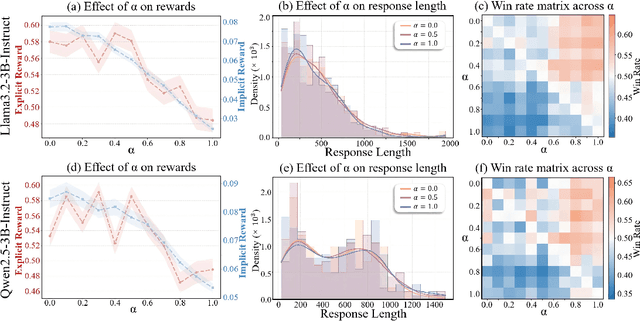
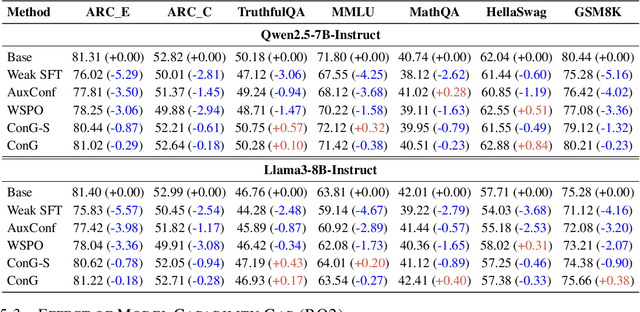
Weak-to-strong generalization provides a promising paradigm for scaling large language models (LLMs) by training stronger models on samples from aligned weaker ones, without requiring human feedback or explicit reward modeling. However, its robustness and generalization are hindered by the noise and biases in weak-model outputs, which limit its applicability in practice. To address this challenge, we leverage implicit rewards, which approximate explicit rewards through log-likelihood ratios, and reveal their structural equivalence with Contrastive Decoding (CD), a decoding strategy shown to reduce noise in LLM generation. Building on this connection, we propose Contrastive Weak-to-Strong Generalization (ConG), a framework that employs contrastive decoding between pre- and post-alignment weak models to generate higher-quality samples. This approach enables more reliable capability transfer, denoising, and improved robustness, substantially mitigating the limitations of traditional weak-to-strong methods. Empirical results across different model families confirm consistent improvements, demonstrating the generality and effectiveness of ConG. Taken together, our findings highlight the potential of ConG to advance weak-to-strong generalization and provide a promising pathway toward AGI.
Rethinking Domain-Specific LLM Benchmark Construction: A Comprehensiveness-Compactness Approach
Aug 13, 2025Numerous benchmarks have been built to evaluate the domain-specific abilities of large language models (LLMs), highlighting the need for effective and efficient benchmark construction. Existing domain-specific benchmarks primarily focus on the scaling law, relying on massive corpora for supervised fine-tuning or generating extensive question sets for broad coverage. However, the impact of corpus and question-answer (QA) set design on the precision and recall of domain-specific LLMs remains unexplored. In this paper, we address this gap and demonstrate that the scaling law is not always the optimal principle for benchmark construction in specific domains. Instead, we propose Comp-Comp, an iterative benchmarking framework based on a comprehensiveness-compactness principle. Here, comprehensiveness ensures semantic recall of the domain, while compactness enhances precision, guiding both corpus and QA set construction. To validate our framework, we conducted a case study in a well-renowned university, resulting in the creation of XUBench, a large-scale and comprehensive closed-domain benchmark. Although we use the academic domain as the case in this work, our Comp-Comp framework is designed to be extensible beyond academia, providing valuable insights for benchmark construction across various domains.
FDBPL: Faster Distillation-Based Prompt Learning for Region-Aware Vision-Language Models Adaptation
May 23, 2025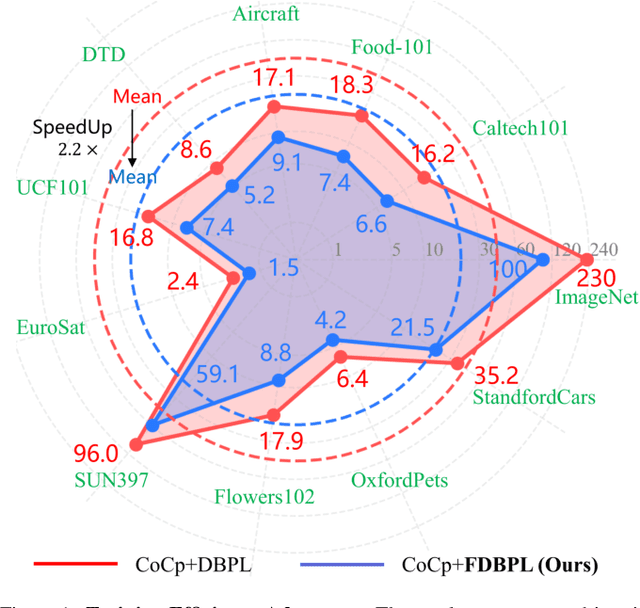
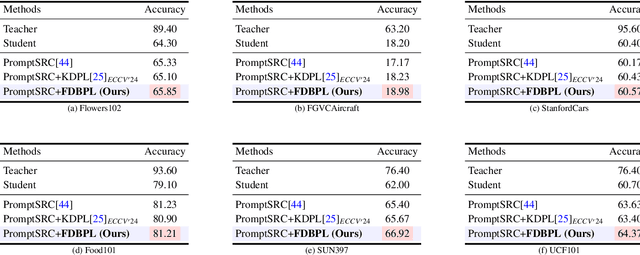
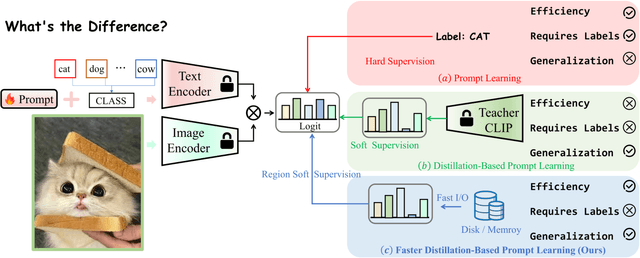
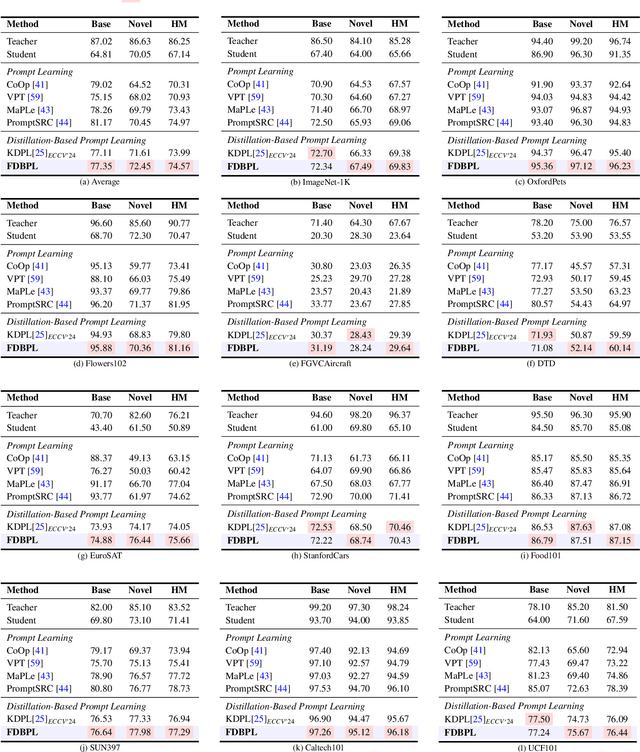
Prompt learning as a parameter-efficient method that has been widely adopted to adapt Vision-Language Models (VLMs) to downstream tasks. While hard-prompt design requires domain expertise and iterative optimization, soft-prompt methods rely heavily on task-specific hard labels, limiting their generalization to unseen categories. Recent popular distillation-based prompt learning methods improve generalization by exploiting larger teacher VLMs and unsupervised knowledge transfer, yet their repetitive teacher model online inference sacrifices the inherent training efficiency advantage of prompt learning. In this paper, we propose {{\large {\textbf{F}}}}aster {{\large {\textbf{D}}}}istillation-{{\large {\textbf{B}}}}ased {{\large {\textbf{P}}}}rompt {{\large {\textbf{L}}}}earning (\textbf{FDBPL}), which addresses these issues by sharing soft supervision contexts across multiple training stages and implementing accelerated I/O. Furthermore, FDBPL introduces a region-aware prompt learning paradigm with dual positive-negative prompt spaces to fully exploit randomly cropped regions that containing multi-level information. We propose a positive-negative space mutual learning mechanism based on similarity-difference learning, enabling student CLIP models to recognize correct semantics while learning to reject weakly related concepts, thereby improving zero-shot performance. Unlike existing distillation-based prompt learning methods that sacrifice parameter efficiency for generalization, FDBPL maintains dual advantages of parameter efficiency and strong downstream generalization. Comprehensive evaluations across 11 datasets demonstrate superior performance in base-to-new generalization, cross-dataset transfer, and robustness tests, achieving $2.2\times$ faster training speed.
MolGround: A Benchmark for Molecular Grounding
Apr 01, 2025Current molecular understanding approaches predominantly focus on the descriptive aspect of human perception, providing broad, topic-level insights. However, the referential aspect -- linking molecular concepts to specific structural components -- remains largely unexplored. To address this gap, we propose a molecular grounding benchmark designed to evaluate a model's referential abilities. We align molecular grounding with established conventions in NLP, cheminformatics, and molecular science, showcasing the potential of NLP techniques to advance molecular understanding within the AI for Science movement. Furthermore, we constructed the largest molecular understanding benchmark to date, comprising 79k QA pairs, and developed a multi-agent grounding prototype as proof of concept. This system outperforms existing models, including GPT-4o, and its grounding outputs have been integrated to enhance traditional tasks such as molecular captioning and ATC (Anatomical, Therapeutic, Chemical) classification.
Mean of Means: Human Localization with Calibration-free and Unconstrained Camera Settings (extended version)
Feb 18, 2025



Accurate human localization is crucial for various applications, especially in the Metaverse era. Existing high precision solutions rely on expensive, tag-dependent hardware, while vision-based methods offer a cheaper, tag-free alternative. However, current vision solutions based on stereo vision face limitations due to rigid perspective transformation principles and error propagation in multi-stage SVD solvers. These solutions also require multiple high-resolution cameras with strict setup constraints.To address these limitations, we propose a probabilistic approach that considers all points on the human body as observations generated by a distribution centered around the body's geometric center. This enables us to improve sampling significantly, increasing the number of samples for each point of interest from hundreds to billions. By modeling the relation between the means of the distributions of world coordinates and pixel coordinates, leveraging the Central Limit Theorem, we ensure normality and facilitate the learning process. Experimental results demonstrate human localization accuracy of 96\% within a 0.3$m$ range and nearly 100\% accuracy within a 0.5$m$ range, achieved at a low cost of only 10 USD using two web cameras with a resolution of 640$\times$480 pixels.
PolySmart @ TRECVid 2024 Video-To-Text
Dec 23, 2024



In this paper, we present our methods and results for the Video-To-Text (VTT) task at TRECVid 2024, exploring the capabilities of Vision-Language Models (VLMs) like LLaVA and LLaVA-NeXT-Video in generating natural language descriptions for video content. We investigate the impact of fine-tuning VLMs on VTT datasets to enhance description accuracy, contextual relevance, and linguistic consistency. Our analysis reveals that fine-tuning substantially improves the model's ability to produce more detailed and domain-aligned text, bridging the gap between generic VLM tasks and the specialized needs of VTT. Experimental results demonstrate that our fine-tuned model outperforms baseline VLMs across various evaluation metrics, underscoring the importance of domain-specific tuning for complex VTT tasks.
PolySmart @ TRECVid 2024 Medical Video Question Answering
Dec 20, 2024Video Corpus Visual Answer Localization (VCVAL) includes question-related video retrieval and visual answer localization in the videos. Specifically, we use text-to-text retrieval to find relevant videos for a medical question based on the similarity of video transcript and answers generated by GPT4. For the visual answer localization, the start and end timestamps of the answer are predicted by the alignments on both visual content and subtitles with queries. For the Query-Focused Instructional Step Captioning (QFISC) task, the step captions are generated by GPT4. Specifically, we provide the video captions generated by the LLaVA-Next-Video model and the video subtitles with timestamps as context, and ask GPT4 to generate step captions for the given medical query. We only submit one run for evaluation and it obtains a F-score of 11.92 and mean IoU of 9.6527.
PolySmart and VIREO @ TRECVid 2024 Ad-hoc Video Search
Dec 20, 2024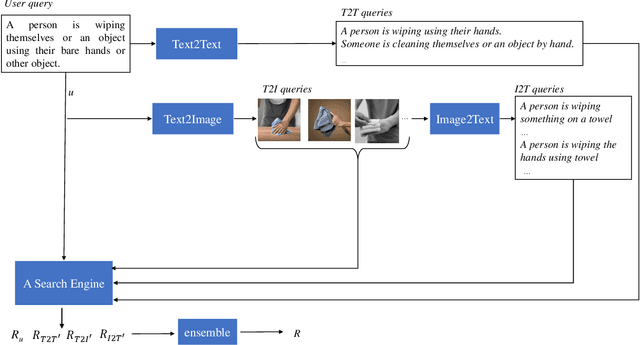


This year, we explore generation-augmented retrieval for the TRECVid AVS task. Specifically, the understanding of textual query is enhanced by three generations, including Text2Text, Text2Image, and Image2Text, to address the out-of-vocabulary problem. Using different combinations of them and the rank list retrieved by the original query, we submitted four automatic runs. For manual runs, we use a large language model (LLM) (i.e., GPT4) to rephrase test queries based on the concept bank of the search engine, and we manually check again to ensure all the concepts used in the rephrased queries are in the bank. The result shows that the fusion of the original and generated queries outperforms the original query on TV24 query sets. The generated queries retrieve different rank lists from the original query.
Multi-Level Querying using A Knowledge Pyramid
Jul 31, 2024



This paper addresses the need for improved precision in existing Retrieval-Augmented Generation (RAG) methods that primarily focus on enhancing recall. We propose a multi-layer knowledge pyramid approach within the RAG framework to achieve a better balance between precision and recall. The knowledge pyramid consists of three layers: Ontologies, Knowledge Graphs (KGs), and chunk-based raw text. We employ cross-layer augmentation techniques for comprehensive knowledge coverage and dynamic updates of the Ontology schema and instances. To ensure compactness, we utilize cross-layer filtering methods for knowledge condensation in KGs. Our approach, named PolyRAG, follows a waterfall model for retrieval, starting from the top of the pyramid and progressing down until a confident answer is obtained. We introduce two benchmarks for domain-specific knowledge retrieval, one in the academic domain and the other in the financial domain. The effectiveness of the methods has been validated through comprehensive experiments by outperforming 19 SOTA methods. An encouraging observation is that the proposed method has augmented the GPT-4, providing 395\% F1 gain by improving its performance from 0.1636 to 0.8109.