 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Mobile Magnetic Manipulation Platform for Gastrointestinal Navigation with Deep Reinforcement Learning Control
Jan 22, 2026Targeted drug delivery in the gastrointestinal (GI) tract using magnetic robots offers a promising alternative to systemic treatments. However, controlling these robots is a major challenge. Stationary magnetic systems have a limited workspace, while mobile systems (e.g., coils on a robotic arm) suffer from a "model-calibration bottleneck", requiring complex, pre-calibrated physical models that are time-consuming to create and computationally expensive. This paper presents a compact, low-cost mobile magnetic manipulation platform that overcomes this limitation using Deep Reinforcement Learning (DRL). Our system features a compact four-electromagnet array mounted on a UR5 collaborative robot. A Soft Actor-Critic (SAC)-based control strategy is trained through a sim-to-real pipeline, enabling effective policy deployment within 15 minutes and significantly reducing setup time. We validated the platform by controlling a 7-mm magnetic capsule along 2D trajectories. Our DRL-based controller achieved a root-mean-square error (RMSE) of 1.18~mm for a square path and 1.50~mm for a circular path. We also demonstrated successful tracking over a clinically relevant, 30 cm * 20 cm workspace. This work demonstrates a rapidly deployable, model-free control framework capable of precise magnetic manipulation in a large workspace,validated using a 2D GI phantom.
QMBench: A Research Level Benchmark for Quantum Materials Research
Dec 19, 2025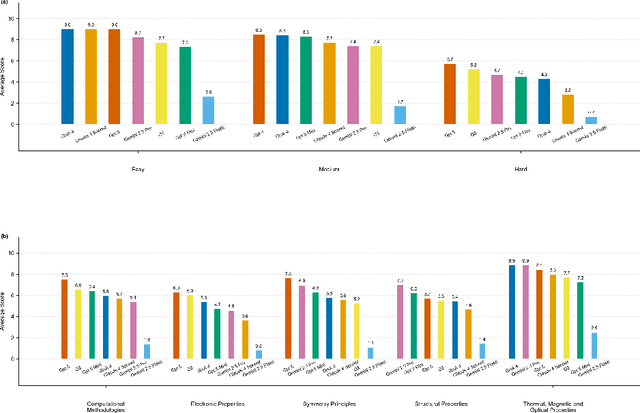

We introduce QMBench, a comprehensive benchmark designed to evaluate the capability of large language model agents in quantum materials research. This specialized benchmark assesses the model's ability to apply condensed matter physics knowledge and computational techniques such as density functional theory to solve research problems in quantum materials science. QMBench encompasses different domains of the quantum material research, including structural properties, electronic properties, thermodynamic and other properties, symmetry principle and computational methodologies. By providing a standardized evaluation framework, QMBench aims to accelerate the development of an AI scientist capable of making creative contributions to quantum materials research. We expect QMBench to be developed and constantly improved by the research community.
Aligning by Misaligning: Boundary-aware Curriculum Learning for Multimodal Alignment
Nov 11, 2025Most multimodal models treat every negative pair alike, ignoring the ambiguous negatives that differ from the positive by only a small detail. We propose Boundary-Aware Curriculum with Local Attention (BACL), a lightweight add-on that turns these borderline cases into a curriculum signal. A Boundary-aware Negative Sampler gradually raises difficulty, while a Contrastive Local Attention loss highlights where the mismatch occurs. The two modules are fully differentiable and work with any off-the-shelf dual encoder. Theory predicts a fast O(1/n) error rate; practice shows up to +32% R@1 over CLIP and new SOTA on four large-scale benchmarks, all without extra labels.
Removal of Hallucination on Hallucination: Debate-Augmented RAG
May 24, 2025Retrieval-Augmented Generation (RAG) enhances factual accuracy by integrating external knowledge, yet it introduces a critical issue: erroneous or biased retrieval can mislead generation, compounding hallucinations, a phenomenon we term Hallucination on Hallucination. To address this, we propose Debate-Augmented RAG (DRAG), a training-free framework that integrates Multi-Agent Debate (MAD) mechanisms into both retrieval and generation stages. In retrieval, DRAG employs structured debates among proponents, opponents, and judges to refine retrieval quality and ensure factual reliability. In generation, DRAG introduces asymmetric information roles and adversarial debates, enhancing reasoning robustness and mitigating factual inconsistencies. Evaluations across multiple tasks demonstrate that DRAG improves retrieval reliability, reduces RAG-induced hallucinations, and significantly enhances overall factual accuracy. Our code is available at https://github.com/Huenao/Debate-Augmented-RAG.
PolySmart @ TRECVid 2024 Medical Video Question Answering
Dec 20, 2024Video Corpus Visual Answer Localization (VCVAL) includes question-related video retrieval and visual answer localization in the videos. Specifically, we use text-to-text retrieval to find relevant videos for a medical question based on the similarity of video transcript and answers generated by GPT4. For the visual answer localization, the start and end timestamps of the answer are predicted by the alignments on both visual content and subtitles with queries. For the Query-Focused Instructional Step Captioning (QFISC) task, the step captions are generated by GPT4. Specifically, we provide the video captions generated by the LLaVA-Next-Video model and the video subtitles with timestamps as context, and ask GPT4 to generate step captions for the given medical query. We only submit one run for evaluation and it obtains a F-score of 11.92 and mean IoU of 9.6527.
Prior Knowledge Integration via LLM Encoding and Pseudo Event Regulation for Video Moment Retrieval
Jul 23, 2024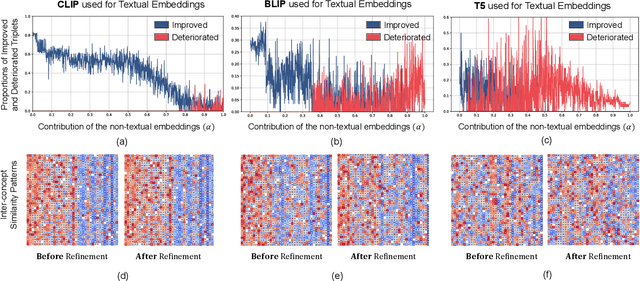
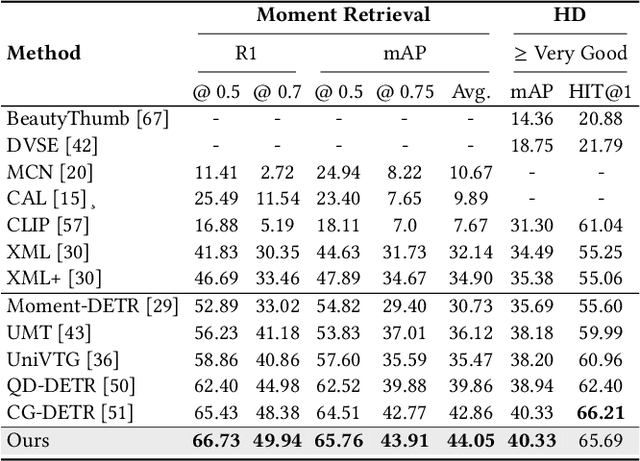
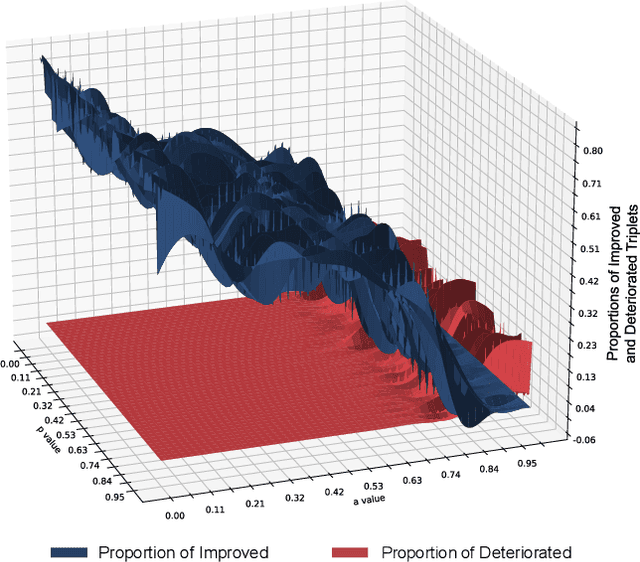
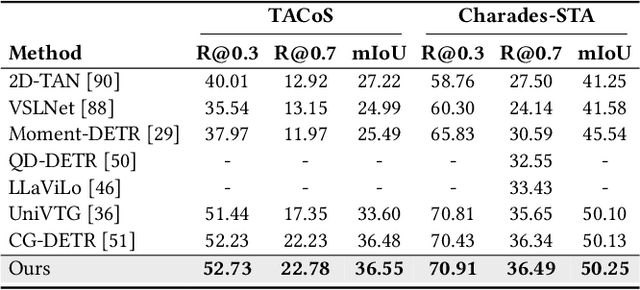
In this paper, we investigate the feasibility of leveraging large language models (LLMs) for integrating general knowledge and incorporating pseudo-events as priors for temporal content distribution in video moment retrieval (VMR) models. The motivation behind this study arises from the limitations of using LLMs as decoders for generating discrete textual descriptions, which hinders their direct application to continuous outputs like salience scores and inter-frame embeddings that capture inter-frame relations. To overcome these limitations, we propose utilizing LLM encoders instead of decoders. Through a feasibility study, we demonstrate that LLM encoders effectively refine inter-concept relations in multimodal embeddings, even without being trained on textual embeddings. We also show that the refinement capability of LLM encoders can be transferred to other embeddings, such as BLIP and T5, as long as these embeddings exhibit similar inter-concept similarity patterns to CLIP embeddings. We present a general framework for integrating LLM encoders into existing VMR architectures, specifically within the fusion module. Through experimental validation, we demonstrate the effectiveness of our proposed methods by achieving state-of-the-art performance in VMR. The source code can be accessed at https://github.com/fletcherjiang/LLMEPET.
LibriSQA: Advancing Free-form and Open-ended Spoken Question Answering with a Novel Dataset and Framework
Aug 30, 2023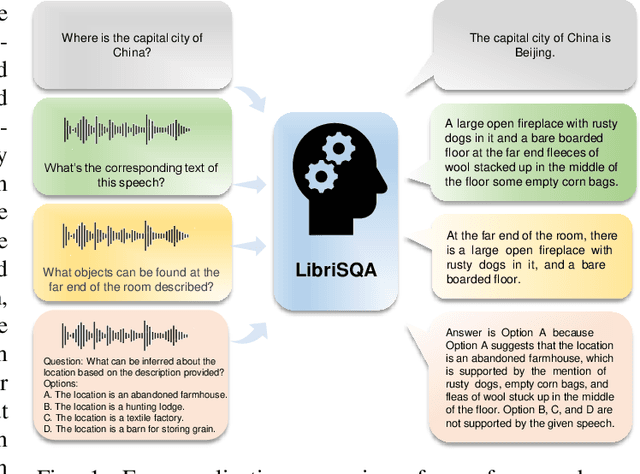
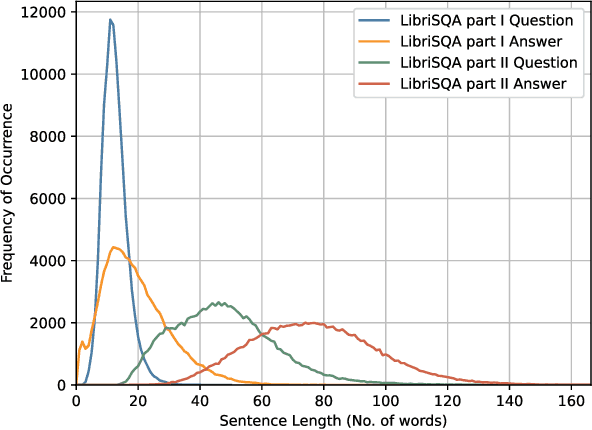
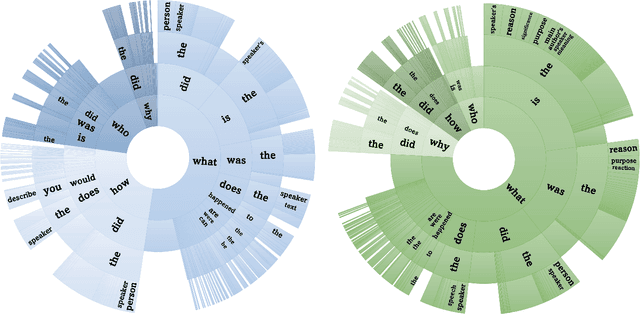
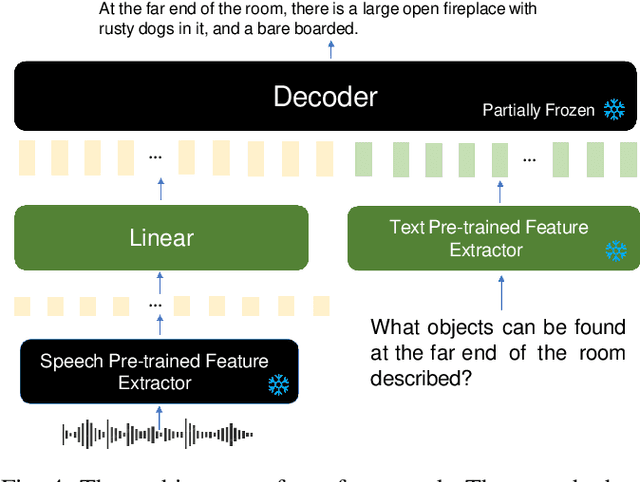
While Large Language Models (LLMs) have demonstrated commendable performance across a myriad of domains and tasks, existing LLMs still exhibit a palpable deficit in handling multimodal functionalities, especially for the Spoken Question Answering (SQA) task which necessitates precise alignment and deep interaction between speech and text features. To address the SQA challenge on LLMs, we initially curated the free-form and open-ended LibriSQA dataset from Librispeech, comprising Part I with natural conversational formats and Part II encompassing multiple-choice questions followed by answers and analytical segments. Both parts collectively include 107k SQA pairs that cover various topics. Given the evident paucity of existing speech-text LLMs, we propose a lightweight, end-to-end framework to execute the SQA task on the LibriSQA, witnessing significant results. By reforming ASR into the SQA format, we further substantiate our framework's capability in handling ASR tasks. Our empirical findings bolster the LLMs' aptitude for aligning and comprehending multimodal information, paving the way for the development of universal multimodal LLMs. The dataset and demo can be found at https://github.com/ZihanZhaoSJTU/LibriSQA.