 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Every Head Count: Sparse Attention Without the Speed-Performance Trade-off
Nov 12, 2025The design of Large Language Models (LLMs) has long been hampered by a fundamental conflict within their core attention mechanism: its remarkable expressivity is built upon a computational complexity of $O(H \cdot N^2)$ that grows quadratically with the context size ($N$) and linearly with the number of heads ($H$). This standard implementation harbors significant computational redundancy, as all heads independently compute attention over the same sequence space. Existing sparse methods, meanwhile, often trade information integrity for computational efficiency. To resolve this efficiency-performance trade-off, we propose SPAttention, whose core contribution is the introduction of a new paradigm we term Principled Structural Sparsity. SPAttention does not merely drop connections but instead reorganizes the computational task by partitioning the total attention workload into balanced, non-overlapping distance bands, assigning each head a unique segment. This approach transforms the multi-head attention mechanism from $H$ independent $O(N^2)$ computations into a single, collaborative $O(N^2)$ computation, fundamentally reducing complexity by a factor of $H$. The structured inductive bias compels functional specialization among heads, enabling a more efficient allocation of computational resources from redundant modeling to distinct dependencies across the entire sequence span. Extensive empirical validation on the OLMoE-1B-7B and 0.25B-1.75B model series demonstrates that while delivering an approximately two-fold increase in training throughput, its performance is on par with standard dense attention, even surpassing it on select key metrics, while consistently outperforming representative sparse attention methods including Longformer, Reformer, and BigBird across all evaluation metrics.
Kling-Avatar: Grounding Multimodal Instructions for Cascaded Long-Duration Avatar Animation Synthesis
Sep 11, 2025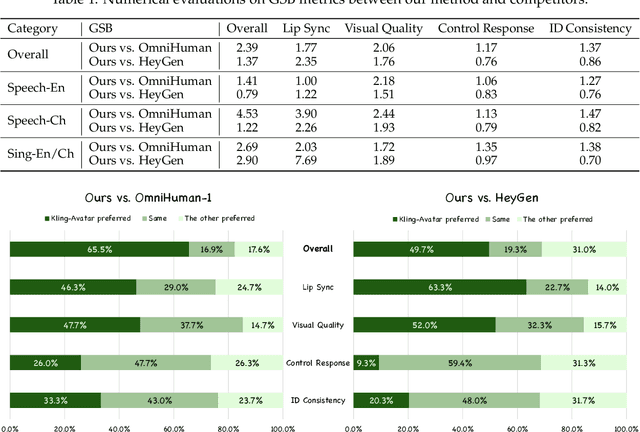
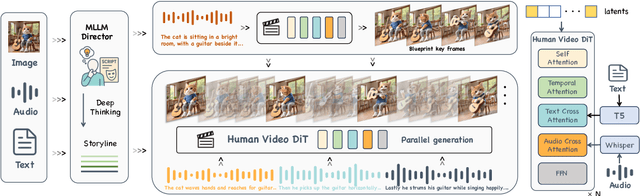


Recent advances in audio-driven avatar video generation have significantly enhanced audio-visual realism. However, existing methods treat instruction conditioning merely as low-level tracking driven by acoustic or visual cues, without modeling the communicative purpose conveyed by the instructions. This limitation compromises their narrative coherence and character expressiveness. To bridge this gap, we introduce Kling-Avatar, a novel cascaded framework that unifies multimodal instruction understanding with photorealistic portrait generation. Our approach adopts a two-stage pipeline. In the first stage, we design a multimodal large language model (MLLM) director that produces a blueprint video conditioned on diverse instruction signals, thereby governing high-level semantics such as character motion and emotions. In the second stage, guided by blueprint keyframes, we generate multiple sub-clips in parallel using a first-last frame strategy. This global-to-local framework preserves fine-grained details while faithfully encoding the high-level intent behind multimodal instructions. Our parallel architecture also enables fast and stable generation of long-duration videos, making it suitable for real-world applications such as digital human livestreaming and vlogging. To comprehensively evaluate our method, we construct a benchmark of 375 curated samples covering diverse instructions and challenging scenarios. Extensive experiments demonstrate that Kling-Avatar is capable of generating vivid, fluent, long-duration videos at up to 1080p and 48 fps, achieving superior performance in lip synchronization accuracy, emotion and dynamic expressiveness, instruction controllability, identity preservation, and cross-domain generalization. These results establish Kling-Avatar as a new benchmark for semantically grounded, high-fidelity audio-driven avatar synthesis.
C2-Evo: Co-Evolving Multimodal Data and Model for Self-Improving Reasoning
Jul 22, 2025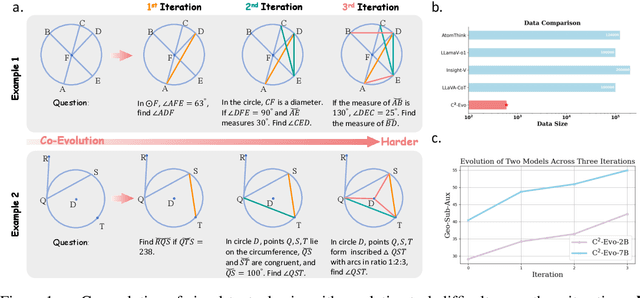

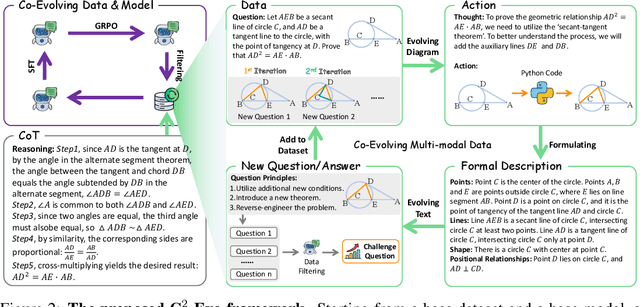
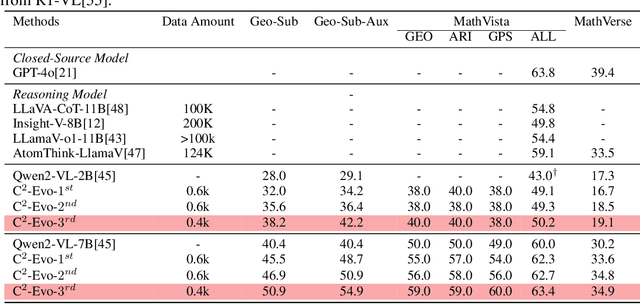
Recent advances in multimodal large language models (MLLMs) have shown impressive reasoning capabilities. However, further enhancing existing MLLMs necessitates high-quality vision-language datasets with carefully curated task complexities, which are both costly and challenging to scale. Although recent self-improving models that iteratively refine themselves offer a feasible solution, they still suffer from two core challenges: (i) most existing methods augment visual or textual data separately, resulting in discrepancies in data complexity (e.g., over-simplified diagrams paired with redundant textual descriptions); and (ii) the evolution of data and models is also separated, leading to scenarios where models are exposed to tasks with mismatched difficulty levels. To address these issues, we propose C2-Evo, an automatic, closed-loop self-improving framework that jointly evolves both training data and model capabilities. Specifically, given a base dataset and a base model, C2-Evo enhances them by a cross-modal data evolution loop and a data-model evolution loop. The former loop expands the base dataset by generating complex multimodal problems that combine structured textual sub-problems with iteratively specified geometric diagrams, while the latter loop adaptively selects the generated problems based on the performance of the base model, to conduct supervised fine-tuning and reinforcement learning alternately. Consequently, our method continuously refines its model and training data, and consistently obtains considerable performance gains across multiple mathematical reasoning benchmarks. Our code, models, and datasets will be released.
GGTalker: Talking Head Systhesis with Generalizable Gaussian Priors and Identity-Specific Adaptation
Jun 26, 2025Creating high-quality, generalizable speech-driven 3D talking heads remains a persistent challenge. Previous methods achieve satisfactory results for fixed viewpoints and small-scale audio variations, but they struggle with large head rotations and out-of-distribution (OOD) audio. Moreover, they are constrained by the need for time-consuming, identity-specific training. We believe the core issue lies in the lack of sufficient 3D priors, which limits the extrapolation capabilities of synthesized talking heads. To address this, we propose GGTalker, which synthesizes talking heads through a combination of generalizable priors and identity-specific adaptation. We introduce a two-stage Prior-Adaptation training strategy to learn Gaussian head priors and adapt to individual characteristics. We train Audio-Expression and Expression-Visual priors to capture the universal patterns of lip movements and the general distribution of head textures. During the Customized Adaptation, individual speaking styles and texture details are precisely modeled. Additionally, we introduce a color MLP to generate fine-grained, motion-aligned textures and a Body Inpainter to blend rendered results with the background, producing indistinguishable, photorealistic video frames. Comprehensive experiments show that GGTalker achieves state-of-the-art performance in rendering quality, 3D consistency, lip-sync accuracy, and training efficiency.
SyncTalk++: High-Fidelity and Efficient Synchronized Talking Heads Synthesis Using Gaussian Splatting
Jun 17, 2025



Achieving high synchronization in the synthesis of realistic, speech-driven talking head videos presents a significant challenge. A lifelike talking head requires synchronized coordination of subject identity, lip movements, facial expressions, and head poses. The absence of these synchronizations is a fundamental flaw, leading to unrealistic results. To address the critical issue of synchronization, identified as the ''devil'' in creating realistic talking heads, we introduce SyncTalk++, which features a Dynamic Portrait Renderer with Gaussian Splatting to ensure consistent subject identity preservation and a Face-Sync Controller that aligns lip movements with speech while innovatively using a 3D facial blendshape model to reconstruct accurate facial expressions. To ensure natural head movements, we propose a Head-Sync Stabilizer, which optimizes head poses for greater stability. Additionally, SyncTalk++ enhances robustness to out-of-distribution (OOD) audio by incorporating an Expression Generator and a Torso Restorer, which generate speech-matched facial expressions and seamless torso regions. Our approach maintains consistency and continuity in visual details across frames and significantly improves rendering speed and quality, achieving up to 101 frames per second. Extensive experiments and user studies demonstrate that SyncTalk++ outperforms state-of-the-art methods in synchronization and realism. We recommend watching the supplementary video: https://ziqiaopeng.github.io/synctalk++.
Removal of Hallucination on Hallucination: Debate-Augmented RAG
May 24, 2025Retrieval-Augmented Generation (RAG) enhances factual accuracy by integrating external knowledge, yet it introduces a critical issue: erroneous or biased retrieval can mislead generation, compounding hallucinations, a phenomenon we term Hallucination on Hallucination. To address this, we propose Debate-Augmented RAG (DRAG), a training-free framework that integrates Multi-Agent Debate (MAD) mechanisms into both retrieval and generation stages. In retrieval, DRAG employs structured debates among proponents, opponents, and judges to refine retrieval quality and ensure factual reliability. In generation, DRAG introduces asymmetric information roles and adversarial debates, enhancing reasoning robustness and mitigating factual inconsistencies. Evaluations across multiple tasks demonstrate that DRAG improves retrieval reliability, reduces RAG-induced hallucinations, and significantly enhances overall factual accuracy. Our code is available at https://github.com/Huenao/Debate-Augmented-RAG.
Selftok: Discrete Visual Tokens of Autoregression, by Diffusion, and for Reasoning
May 18, 2025We completely discard the conventional spatial prior in image representation and introduce a novel discrete visual tokenizer: Self-consistency Tokenizer (Selftok). At its design core, we compose an autoregressive (AR) prior -- mirroring the causal structure of language -- into visual tokens by using the reverse diffusion process of image generation. The AR property makes Selftok fundamentally distinct from traditional spatial tokens in the following two key ways: - Selftok offers an elegant and minimalist approach to unify diffusion and AR for vision-language models (VLMs): By representing images with Selftok tokens, we can train a VLM using a purely discrete autoregressive architecture -- like that in LLMs -- without requiring additional modules or training objectives. - We theoretically show that the AR prior satisfies the Bellman equation, whereas the spatial prior does not. Therefore, Selftok supports reinforcement learning (RL) for visual generation with effectiveness comparable to that achieved in LLMs. Besides the AR property, Selftok is also a SoTA tokenizer that achieves a favorable trade-off between high-quality reconstruction and compression rate. We use Selftok to build a pure AR VLM for both visual comprehension and generation tasks. Impressively, without using any text-image training pairs, a simple policy gradient RL working in the visual tokens can significantly boost the visual generation benchmark, surpassing all the existing models by a large margin. Therefore, we believe that Selftok effectively addresses the long-standing challenge that visual tokens cannot support effective RL. When combined with the well-established strengths of RL in LLMs, this brings us one step closer to realizing a truly multimodal LLM. Project Page: https://selftok-team.github.io/report/.
Discrete Visual Tokens of Autoregression, by Diffusion, and for Reasoning
May 12, 2025We completely discard the conventional spatial prior in image representation and introduce a novel discrete visual tokenizer: Self-consistency Tokenizer (Selftok). At its design core, we compose an autoregressive (AR) prior -- mirroring the causal structure of language -- into visual tokens by using the reverse diffusion process of image generation. The AR property makes Selftok fundamentally distinct from traditional spatial tokens in the following two key ways: - Selftok offers an elegant and minimalist approach to unify diffusion and AR for vision-language models (VLMs): By representing images with Selftok tokens, we can train a VLM using a purely discrete autoregressive architecture -- like that in LLMs -- without requiring additional modules or training objectives. - We theoretically show that the AR prior satisfies the Bellman equation, whereas the spatial prior does not. Therefore, Selftok supports reinforcement learning (RL) for visual generation with effectiveness comparable to that achieved in LLMs. Besides the AR property, Selftok is also a SoTA tokenizer that achieves a favorable trade-off between high-quality reconstruction and compression rate. We use Selftok to build a pure AR VLM for both visual comprehension and generation tasks. Impressively, without using any text-image training pairs, a simple policy gradient RL working in the visual tokens can significantly boost the visual generation benchmark, surpassing all the existing models by a large margin. Therefore, we believe that Selftok effectively addresses the long-standing challenge that visual tokens cannot support effective RL. When combined with the well-established strengths of RL in LLMs, this brings us one step closer to realizing a truly multimodal LLM. Project Page: https://selftok-team.github.io/report/.
On Path to Multimodal Generalist: General-Level and General-Bench
May 07, 2025The Multimodal Large Language Model (MLLM) is currently experiencing rapid growth, driven by the advanced capabilities of LLMs. Unlike earlier specialists, existing MLLMs are evolving towards a Multimodal Generalist paradigm. Initially limited to understanding multiple modalities, these models have advanced to not only comprehend but also generate across modalities. Their capabilities have expanded from coarse-grained to fine-grained multimodal understanding and from supporting limited modalities to arbitrary ones. While many benchmarks exist to assess MLLMs, a critical question arises: Can we simply assume that higher performance across tasks indicates a stronger MLLM capability, bringing us closer to human-level AI? We argue that the answer is not as straightforward as it seems. This project introduces General-Level, an evaluation framework that defines 5-scale levels of MLLM performance and generality, offering a methodology to compare MLLMs and gauge the progress of existing systems towards more robust multimodal generalists and, ultimately, towards AGI. At the core of the framework is the concept of Synergy, which measures whether models maintain consistent capabilities across comprehension and generation, and across multiple modalities. To support this evaluation, we present General-Bench, which encompasses a broader spectrum of skills, modalities, formats, and capabilities, including over 700 tasks and 325,800 instances. The evaluation results that involve over 100 existing state-of-the-art MLLMs uncover the capability rankings of generalists, highlighting the challenges in reaching genuine AI. We expect this project to pave the way for future research on next-generation multimodal foundation models, providing a robust infrastructure to accelerate the realization of AGI. Project page: https://generalist.top/
Reasoning Physical Video Generation with Diffusion Timestep Tokens via Reinforcement Learning
Apr 22, 2025Despite recent progress in video generation, producing videos that adhere to physical laws remains a significant challenge. Traditional diffusion-based methods struggle to extrapolate to unseen physical conditions (eg, velocity) due to their reliance on data-driven approximations. To address this, we propose to integrate symbolic reasoning and reinforcement learning to enforce physical consistency in video generation. We first introduce the Diffusion Timestep Tokenizer (DDT), which learns discrete, recursive visual tokens by recovering visual attributes lost during the diffusion process. The recursive visual tokens enable symbolic reasoning by a large language model. Based on it, we propose the Phys-AR framework, which consists of two stages: The first stage uses supervised fine-tuning to transfer symbolic knowledge, while the second stage applies reinforcement learning to optimize the model's reasoning abilities through reward functions based on physical conditions. Our approach allows the model to dynamically adjust and improve the physical properties of generated videos, ensuring adherence to physical laws. Experimental results demonstrate that PhysAR can generate videos that are physically consistent.