 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Multimodal Federated Learning via Chained Modality Optimization
Jun 01, 2026Multimodal Federated Learning (MMFL) enables privacy-preserving collaborative learning across decentralized clients with heterogeneous data and modality availability. However, most existing MMFL methods cast multimodal training as a joint optimization problem, overlooking a key bottleneck: modality competition, where dominant modalities suppress weaker ones and lead to suboptimal global models. To address this, we propose FedMChain, a balanced MMFL framework that structures federated multimodal training as a chain of modality-wise phases. This phase-wise design gives each modality a dedicated local optimization window on multimodal clients to mitigate modality competition, and further promotes cross-modal complementarity via an error-compensated regularizer. On the server side, we employ a sparse sign-guided aggregation strategy that leverages directional sign agreement for robust intra-modality aggregation, avoids destructive averaging, and supports less frequent synchronization to reduce communication overhead. Extensive experiments on multimodal benchmarks demonstrate that FedMChain consistently improves predictive performance while requiring less frequent communication than baselines.
Panoramic Affordance Prediction
Mar 16, 2026Affordance prediction serves as a critical bridge between perception and action in embodied AI. However, existing research is confined to pinhole camera models, which suffer from narrow Fields of View (FoV) and fragmented observations, often missing critical holistic environmental context. In this paper, we present the first exploration into Panoramic Affordance Prediction, utilizing 360-degree imagery to capture global spatial relationships and holistic scene understanding. To facilitate this novel task, we first introduce PAP-12K, a large-scale benchmark dataset containing over 1,000 ultra-high-resolution (12k, 11904 x 5952) panoramic images with over 12k carefully annotated QA pairs and affordance masks. Furthermore, we propose PAP, a training-free, coarse-to-fine pipeline inspired by the human foveal visual system to tackle the ultra-high resolution and severe distortion inherent in panoramic images. PAP employs recursive visual routing via grid prompting to progressively locate targets, applies an adaptive gaze mechanism to rectify local geometric distortions, and utilizes a cascaded grounding pipeline to extract precise instance-level masks. Experimental results on PAP-12K reveal that existing affordance prediction methods designed for standard perspective images suffer severe performance degradation and fail due to the unique challenges of panoramic vision. In contrast, PAP framework effectively overcomes these obstacles, significantly outperforming state-of-the-art baselines and highlighting the immense potential of panoramic perception for robust embodied intelligence.
DVD: Deterministic Video Depth Estimation with Generative Priors
Mar 12, 2026Existing video depth estimation faces a fundamental trade-off: generative models suffer from stochastic geometric hallucinations and scale drift, while discriminative models demand massive labeled datasets to resolve semantic ambiguities. To break this impasse, we present DVD, the first framework to deterministically adapt pre-trained video diffusion models into single-pass depth regressors. Specifically, DVD features three core designs: (i) repurposing the diffusion timestep as a structural anchor to balance global stability with high-frequency details; (ii) latent manifold rectification (LMR) to mitigate regression-induced over-smoothing, enforcing differential constraints to restore sharp boundaries and coherent motion; and (iii) global affine coherence, an inherent property bounding inter-window divergence, which enables seamless long-video inference without requiring complex temporal alignment. Extensive experiments demonstrate that DVD achieves state-of-the-art zero-shot performance across benchmarks. Furthermore, DVD successfully unlocks the profound geometric priors implicit in video foundation models using 163x less task-specific data than leading baselines. Notably, we fully release our pipeline, providing the whole training suite for SOTA video depth estimation to benefit the open-source community.
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
Show, Don't Tell: Morphing Latent Reasoning into Image Generation
Feb 02, 2026Text-to-image (T2I) generation has achieved remarkable progress, yet existing methods often lack the ability to dynamically reason and refine during generation--a hallmark of human creativity. Current reasoning-augmented paradigms most rely on explicit thought processes, where intermediate reasoning is decoded into discrete text at fixed steps with frequent image decoding and re-encoding, leading to inefficiencies, information loss, and cognitive mismatches. To bridge this gap, we introduce LatentMorph, a novel framework that seamlessly integrates implicit latent reasoning into the T2I generation process. At its core, LatentMorph introduces four lightweight components: (i) a condenser for summarizing intermediate generation states into compact visual memory, (ii) a translator for converting latent thoughts into actionable guidance, (iii) a shaper for dynamically steering next image token predictions, and (iv) an RL-trained invoker for adaptively determining when to invoke reasoning. By performing reasoning entirely in continuous latent spaces, LatentMorph avoids the bottlenecks of explicit reasoning and enables more adaptive self-refinement. Extensive experiments demonstrate that LatentMorph (I) enhances the base model Janus-Pro by $16\%$ on GenEval and $25\%$ on T2I-CompBench; (II) outperforms explicit paradigms (e.g., TwiG) by $15\%$ and $11\%$ on abstract reasoning tasks like WISE and IPV-Txt, (III) while reducing inference time by $44\%$ and token consumption by $51\%$; and (IV) exhibits $71\%$ cognitive alignment with human intuition on reasoning invocation.
Step-DeepResearch Technical Report
Dec 24, 2025As LLMs shift toward autonomous agents, Deep Research has emerged as a pivotal metric. However, existing academic benchmarks like BrowseComp often fail to meet real-world demands for open-ended research, which requires robust skills in intent recognition, long-horizon decision-making, and cross-source verification. To address this, we introduce Step-DeepResearch, a cost-effective, end-to-end agent. We propose a Data Synthesis Strategy Based on Atomic Capabilities to reinforce planning and report writing, combined with a progressive training path from agentic mid-training to SFT and RL. Enhanced by a Checklist-style Judger, this approach significantly improves robustness. Furthermore, to bridge the evaluation gap in the Chinese domain, we establish ADR-Bench for realistic deep research scenarios. Experimental results show that Step-DeepResearch (32B) scores 61.4% on Scale AI Research Rubrics. On ADR-Bench, it significantly outperforms comparable models and rivals SOTA closed-source models like OpenAI and Gemini DeepResearch. These findings prove that refined training enables medium-sized models to achieve expert-level capabilities at industry-leading cost-efficiency.
A4-Agent: An Agentic Framework for Zero-Shot Affordance Reasoning
Dec 16, 2025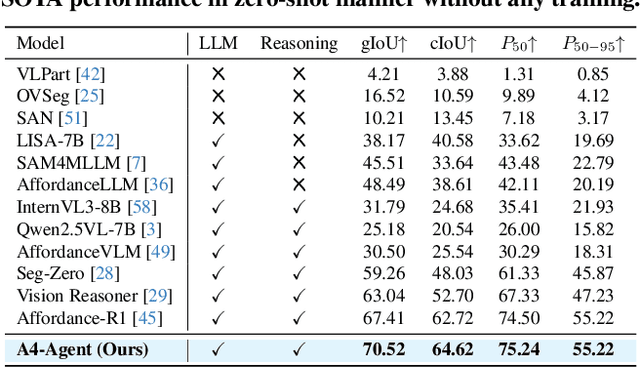
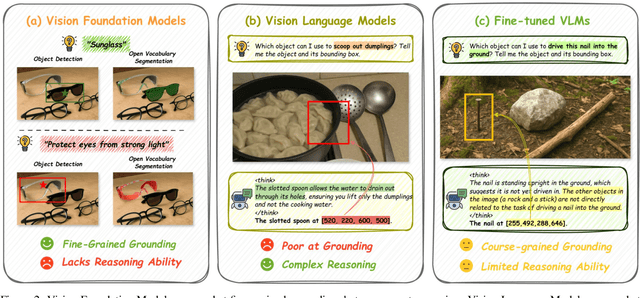
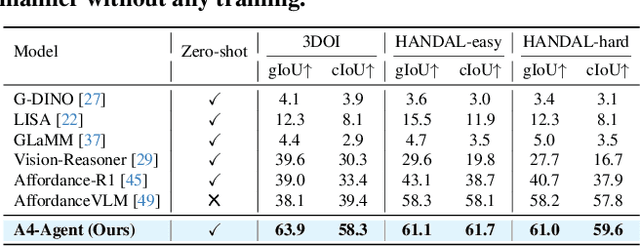
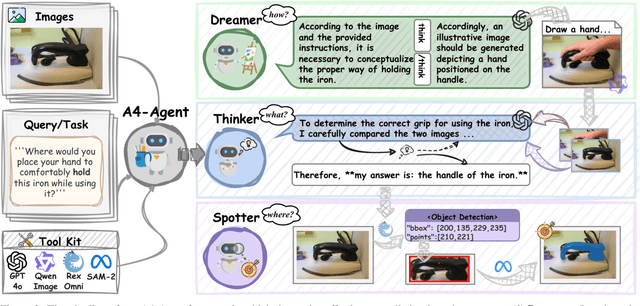
Affordance prediction, which identifies interaction regions on objects based on language instructions, is critical for embodied AI. Prevailing end-to-end models couple high-level reasoning and low-level grounding into a single monolithic pipeline and rely on training over annotated datasets, which leads to poor generalization on novel objects and unseen environments. In this paper, we move beyond this paradigm by proposing A4-Agent, a training-free agentic framework that decouples affordance prediction into a three-stage pipeline. Our framework coordinates specialized foundation models at test time: (1) a $\textbf{Dreamer}$ that employs generative models to visualize $\textit{how}$ an interaction would look; (2) a $\textbf{Thinker}$ that utilizes large vision-language models to decide $\textit{what}$ object part to interact with; and (3) a $\textbf{Spotter}$ that orchestrates vision foundation models to precisely locate $\textit{where}$ the interaction area is. By leveraging the complementary strengths of pre-trained models without any task-specific fine-tuning, our zero-shot framework significantly outperforms state-of-the-art supervised methods across multiple benchmarks and demonstrates robust generalization to real-world settings.
TiViBench: Benchmarking Think-in-Video Reasoning for Video Generative Models
Nov 17, 2025The rapid evolution of video generative models has shifted their focus from producing visually plausible outputs to tackling tasks requiring physical plausibility and logical consistency. However, despite recent breakthroughs such as Veo 3's chain-of-frames reasoning, it remains unclear whether these models can exhibit reasoning capabilities similar to large language models (LLMs). Existing benchmarks predominantly evaluate visual fidelity and temporal coherence, failing to capture higher-order reasoning abilities. To bridge this gap, we propose TiViBench, a hierarchical benchmark specifically designed to evaluate the reasoning capabilities of image-to-video (I2V) generation models. TiViBench systematically assesses reasoning across four dimensions: i) Structural Reasoning & Search, ii) Spatial & Visual Pattern Reasoning, iii) Symbolic & Logical Reasoning, and iv) Action Planning & Task Execution, spanning 24 diverse task scenarios across 3 difficulty levels. Through extensive evaluations, we show that commercial models (e.g., Sora 2, Veo 3.1) demonstrate stronger reasoning potential, while open-source models reveal untapped potential that remains hindered by limited training scale and data diversity. To further unlock this potential, we introduce VideoTPO, a simple yet effective test-time strategy inspired by preference optimization. By performing LLM self-analysis on generated candidates to identify strengths and weaknesses, VideoTPO significantly enhances reasoning performance without requiring additional training, data, or reward models. Together, TiViBench and VideoTPO pave the way for evaluating and advancing reasoning in video generation models, setting a foundation for future research in this emerging field.
Multimodal Spatial Reasoning in the Large Model Era: A Survey and Benchmarks
Oct 29, 2025Humans possess spatial reasoning abilities that enable them to understand spaces through multimodal observations, such as vision and sound. Large multimodal reasoning models extend these abilities by learning to perceive and reason, showing promising performance across diverse spatial tasks. However, systematic reviews and publicly available benchmarks for these models remain limited. In this survey, we provide a comprehensive review of multimodal spatial reasoning tasks with large models, categorizing recent progress in multimodal large language models (MLLMs) and introducing open benchmarks for evaluation. We begin by outlining general spatial reasoning, focusing on post-training techniques, explainability, and architecture. Beyond classical 2D tasks, we examine spatial relationship reasoning, scene and layout understanding, as well as visual question answering and grounding in 3D space. We also review advances in embodied AI, including vision-language navigation and action models. Additionally, we consider emerging modalities such as audio and egocentric video, which contribute to novel spatial understanding through new sensors. We believe this survey establishes a solid foundation and offers insights into the growing field of multimodal spatial reasoning. Updated information about this survey, codes and implementation of the open benchmarks can be found at https://github.com/zhengxuJosh/Awesome-Spatial-Reasoning.
PhysToolBench: Benchmarking Physical Tool Understanding for MLLMs
Oct 10, 2025The ability to use, understand, and create tools is a hallmark of human intelligence, enabling sophisticated interaction with the physical world. For any general-purpose intelligent agent to achieve true versatility, it must also master these fundamental skills. While modern Multimodal Large Language Models (MLLMs) leverage their extensive common knowledge for high-level planning in embodied AI and in downstream Vision-Language-Action (VLA) models, the extent of their true understanding of physical tools remains unquantified. To bridge this gap, we present PhysToolBench, the first benchmark dedicated to evaluating the comprehension of physical tools by MLLMs. Our benchmark is structured as a Visual Question Answering (VQA) dataset comprising over 1,000 image-text pairs. It assesses capabilities across three distinct difficulty levels: (1) Tool Recognition: Requiring the recognition of a tool's primary function. (2) Tool Understanding: Testing the ability to grasp the underlying principles of a tool's operation. (3) Tool Creation: Challenging the model to fashion a new tool from surrounding objects when conventional options are unavailable. Our comprehensive evaluation of 32 MLLMs-spanning proprietary, open-source, specialized embodied, and backbones in VLAs-reveals a significant deficiency in tool understanding. Furthermore, we provide an in-depth analysis and propose preliminary solutions. Code and dataset are publicly available.