 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing high-fidelity 3D and Texture Generation with 2.5D latents
May 28, 2025Despite the availability of large-scale 3D datasets and advancements in 3D generative models, the complexity and uneven quality of 3D geometry and texture data continue to hinder the performance of 3D generation techniques. In most existing approaches, 3D geometry and texture are generated in separate stages using different models and non-unified representations, frequently leading to unsatisfactory coherence between geometry and texture. To address these challenges, we propose a novel framework for joint generation of 3D geometry and texture. Specifically, we focus in generate a versatile 2.5D representations that can be seamlessly transformed between 2D and 3D. Our approach begins by integrating multiview RGB, normal, and coordinate images into a unified representation, termed as 2.5D latents. Next, we adapt pre-trained 2D foundation models for high-fidelity 2.5D generation, utilizing both text and image conditions. Finally, we introduce a lightweight 2.5D-to-3D refiner-decoder framework that efficiently generates detailed 3D representations from 2.5D images. Extensive experiments demonstrate that our model not only excels in generating high-quality 3D objects with coherent structure and color from text and image inputs but also significantly outperforms existing methods in geometry-conditioned texture generation.
ComfyMind: Toward General-Purpose Generation via Tree-Based Planning and Reactive Feedback
May 23, 2025With the rapid advancement of generative models, general-purpose generation has gained increasing attention as a promising approach to unify diverse tasks across modalities within a single system. Despite this progress, existing open-source frameworks often remain fragile and struggle to support complex real-world applications due to the lack of structured workflow planning and execution-level feedback. To address these limitations, we present ComfyMind, a collaborative AI system designed to enable robust and scalable general-purpose generation, built on the ComfyUI platform. ComfyMind introduces two core innovations: Semantic Workflow Interface (SWI) that abstracts low-level node graphs into callable functional modules described in natural language, enabling high-level composition and reducing structural errors; Search Tree Planning mechanism with localized feedback execution, which models generation as a hierarchical decision process and allows adaptive correction at each stage. Together, these components improve the stability and flexibility of complex generative workflows. We evaluate ComfyMind on three public benchmarks: ComfyBench, GenEval, and Reason-Edit, which span generation, editing, and reasoning tasks. Results show that ComfyMind consistently outperforms existing open-source baselines and achieves performance comparable to GPT-Image-1. ComfyMind paves a promising path for the development of open-source general-purpose generative AI systems. Project page: https://github.com/LitaoGuo/ComfyMind
DiMeR: Disentangled Mesh Reconstruction Model
Apr 24, 2025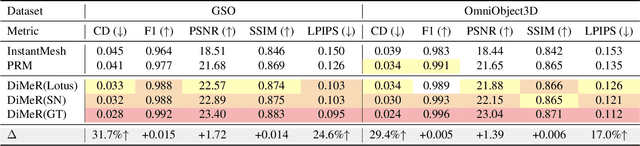

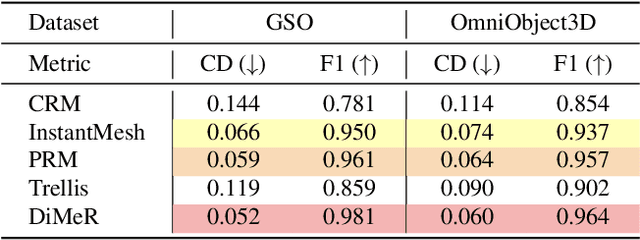
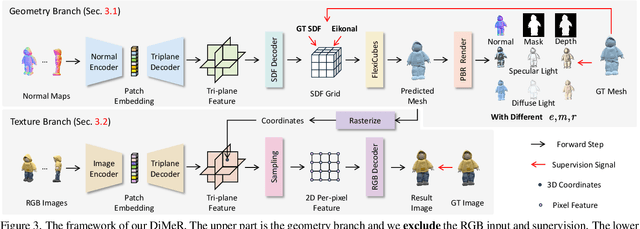
With the advent of large-scale 3D datasets, feed-forward 3D generative models, such as the Large Reconstruction Model (LRM), have gained significant attention and achieved remarkable success. However, we observe that RGB images often lead to conflicting training objectives and lack the necessary clarity for geometry reconstruction. In this paper, we revisit the inductive biases associated with mesh reconstruction and introduce DiMeR, a novel disentangled dual-stream feed-forward model for sparse-view mesh reconstruction. The key idea is to disentangle both the input and framework into geometry and texture parts, thereby reducing the training difficulty for each part according to the Principle of Occam's Razor. Given that normal maps are strictly consistent with geometry and accurately capture surface variations, we utilize normal maps as exclusive input for the geometry branch to reduce the complexity between the network's input and output. Moreover, we improve the mesh extraction algorithm to introduce 3D ground truth supervision. As for texture branch, we use RGB images as input to obtain the textured mesh. Overall, DiMeR demonstrates robust capabilities across various tasks, including sparse-view reconstruction, single-image-to-3D, and text-to-3D. Numerous experiments show that DiMeR significantly outperforms previous methods, achieving over 30% improvement in Chamfer Distance on the GSO and OmniObject3D dataset.
Kiss3DGen: Repurposing Image Diffusion Models for 3D Asset Generation
Mar 03, 2025Diffusion models have achieved great success in generating 2D images. However, the quality and generalizability of 3D content generation remain limited. State-of-the-art methods often require large-scale 3D assets for training, which are challenging to collect. In this work, we introduce Kiss3DGen (Keep It Simple and Straightforward in 3D Generation), an efficient framework for generating, editing, and enhancing 3D objects by repurposing a well-trained 2D image diffusion model for 3D generation. Specifically, we fine-tune a diffusion model to generate ''3D Bundle Image'', a tiled representation composed of multi-view images and their corresponding normal maps. The normal maps are then used to reconstruct a 3D mesh, and the multi-view images provide texture mapping, resulting in a complete 3D model. This simple method effectively transforms the 3D generation problem into a 2D image generation task, maximizing the utilization of knowledge in pretrained diffusion models. Furthermore, we demonstrate that our Kiss3DGen model is compatible with various diffusion model techniques, enabling advanced features such as 3D editing, mesh and texture enhancement, etc. Through extensive experiments, we demonstrate the effectiveness of our approach, showcasing its ability to produce high-quality 3D models efficiently.
PRM: Photometric Stereo based Large Reconstruction Model
Dec 10, 2024We propose PRM, a novel photometric stereo based large reconstruction model to reconstruct high-quality meshes with fine-grained local details. Unlike previous large reconstruction models that prepare images under fixed and simple lighting as both input and supervision, PRM renders photometric stereo images by varying materials and lighting for the purposes, which not only improves the precise local details by providing rich photometric cues but also increases the model robustness to variations in the appearance of input images. To offer enhanced flexibility of images rendering, we incorporate a real-time physically-based rendering (PBR) method and mesh rasterization for online images rendering. Moreover, in employing an explicit mesh as our 3D representation, PRM ensures the application of differentiable PBR, which supports the utilization of multiple photometric supervisions and better models the specular color for high-quality geometry optimization. Our PRM leverages photometric stereo images to achieve high-quality reconstructions with fine-grained local details, even amidst sophisticated image appearances. Extensive experiments demonstrate that PRM significantly outperforms other models.
FlexGen: Flexible Multi-View Generation from Text and Image Inputs
Oct 14, 2024In this work, we introduce FlexGen, a flexible framework designed to generate controllable and consistent multi-view images, conditioned on a single-view image, or a text prompt, or both. FlexGen tackles the challenges of controllable multi-view synthesis through additional conditioning on 3D-aware text annotations. We utilize the strong reasoning capabilities of GPT-4V to generate 3D-aware text annotations. By analyzing four orthogonal views of an object arranged as tiled multi-view images, GPT-4V can produce text annotations that include 3D-aware information with spatial relationship. By integrating the control signal with proposed adaptive dual-control module, our model can generate multi-view images that correspond to the specified text. FlexGen supports multiple controllable capabilities, allowing users to modify text prompts to generate reasonable and corresponding unseen parts. Additionally, users can influence attributes such as appearance and material properties, including metallic and roughness. Extensive experiments demonstrate that our approach offers enhanced multiple controllability, marking a significant advancement over existing multi-view diffusion models. This work has substantial implications for fields requiring rapid and flexible 3D content creation, including game development, animation, and virtual reality. Project page: https://xxu068.github.io/flexgen.github.io/.
SG-Adapter: Enhancing Text-to-Image Generation with Scene Graph Guidance
May 24, 2024
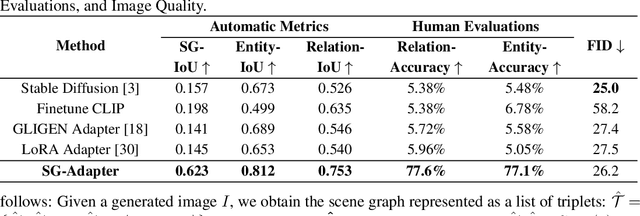
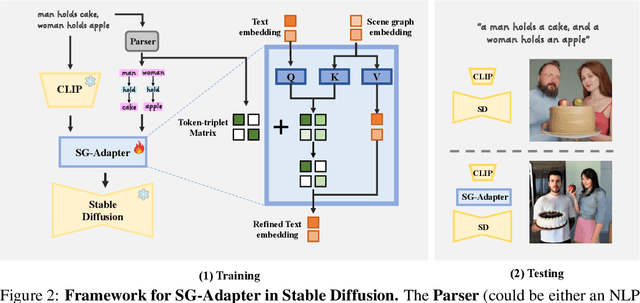
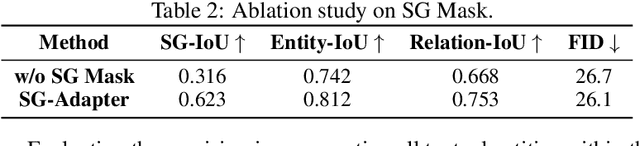
Recent advancements in text-to-image generation have been propelled by the development of diffusion models and multi-modality learning. However, since text is typically represented sequentially in these models, it often falls short in providing accurate contextualization and structural control. So the generated images do not consistently align with human expectations, especially in complex scenarios involving multiple objects and relationships. In this paper, we introduce the Scene Graph Adapter(SG-Adapter), leveraging the structured representation of scene graphs to rectify inaccuracies in the original text embeddings. The SG-Adapter's explicit and non-fully connected graph representation greatly improves the fully connected, transformer-based text representations. This enhancement is particularly notable in maintaining precise correspondence in scenarios involving multiple relationships. To address the challenges posed by low-quality annotated datasets like Visual Genome, we have manually curated a highly clean, multi-relational scene graph-image paired dataset MultiRels. Furthermore, we design three metrics derived from GPT-4V to effectively and thoroughly measure the correspondence between images and scene graphs. Both qualitative and quantitative results validate the efficacy of our approach in controlling the correspondence in multiple relationships.
LucidDreamer: Towards High-Fidelity Text-to-3D Generation via Interval Score Matching
Dec 02, 2023The recent advancements in text-to-3D generation mark a significant milestone in generative models, unlocking new possibilities for creating imaginative 3D assets across various real-world scenarios. While recent advancements in text-to-3D generation have shown promise, they often fall short in rendering detailed and high-quality 3D models. This problem is especially prevalent as many methods base themselves on Score Distillation Sampling (SDS). This paper identifies a notable deficiency in SDS, that it brings inconsistent and low-quality updating direction for the 3D model, causing the over-smoothing effect. To address this, we propose a novel approach called Interval Score Matching (ISM). ISM employs deterministic diffusing trajectories and utilizes interval-based score matching to counteract over-smoothing. Furthermore, we incorporate 3D Gaussian Splatting into our text-to-3D generation pipeline. Extensive experiments show that our model largely outperforms the state-of-the-art in quality and training efficiency.