 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity and Long-Duration Human Image Animation with Diffusion Transformer
Dec 26, 2025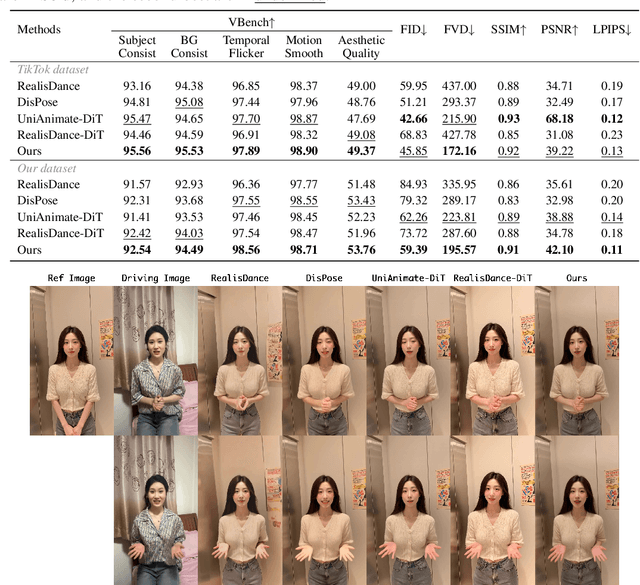

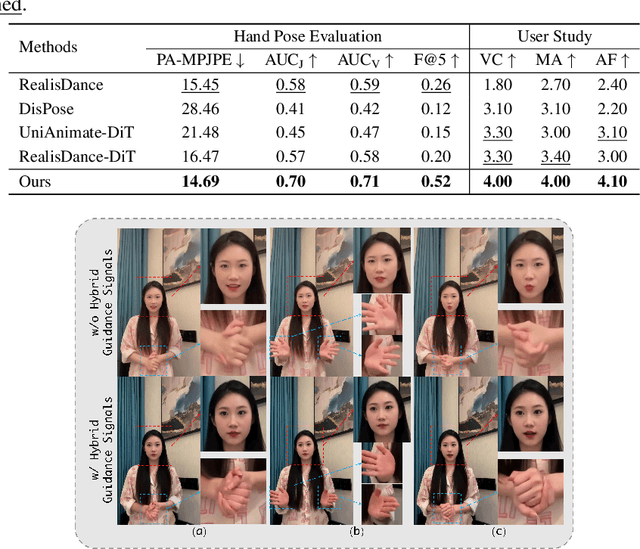
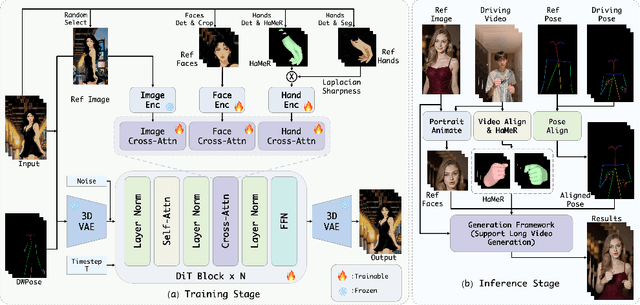
Recent progress in diffusion models has significantly advanced the field of human image animation. While existing methods can generate temporally consistent results for short or regular motions, significant challenges remain, particularly in generating long-duration videos. Furthermore, the synthesis of fine-grained facial and hand details remains under-explored, limiting the applicability of current approaches in real-world, high-quality applications. To address these limitations, we propose a diffusion transformer (DiT)-based framework which focuses on generating high-fidelity and long-duration human animation videos. First, we design a set of hybrid implicit guidance signals and a sharpness guidance factor, enabling our framework to additionally incorporate detailed facial and hand features as guidance. Next, we incorporate the time-aware position shift fusion module, modify the input format within the DiT backbone, and refer to this mechanism as the Position Shift Adaptive Module, which enables video generation of arbitrary length. Finally, we introduce a novel data augmentation strategy and a skeleton alignment model to reduce the impact of human shape variations across different identities. Experimental results demonstrate that our method outperforms existing state-of-the-art approaches, achieving superior performance in both high-fidelity and long-duration human image animation.
Kiss3DGen: Repurposing Image Diffusion Models for 3D Asset Generation
Mar 03, 2025



Diffusion models have achieved great success in generating 2D images. However, the quality and generalizability of 3D content generation remain limited. State-of-the-art methods often require large-scale 3D assets for training, which are challenging to collect. In this work, we introduce Kiss3DGen (Keep It Simple and Straightforward in 3D Generation), an efficient framework for generating, editing, and enhancing 3D objects by repurposing a well-trained 2D image diffusion model for 3D generation. Specifically, we fine-tune a diffusion model to generate ''3D Bundle Image'', a tiled representation composed of multi-view images and their corresponding normal maps. The normal maps are then used to reconstruct a 3D mesh, and the multi-view images provide texture mapping, resulting in a complete 3D model. This simple method effectively transforms the 3D generation problem into a 2D image generation task, maximizing the utilization of knowledge in pretrained diffusion models. Furthermore, we demonstrate that our Kiss3DGen model is compatible with various diffusion model techniques, enabling advanced features such as 3D editing, mesh and texture enhancement, etc. Through extensive experiments, we demonstrate the effectiveness of our approach, showcasing its ability to produce high-quality 3D models efficiently.
Playmate: Flexible Control of Portrait Animation via 3D-Implicit Space Guided Diffusion
Feb 11, 2025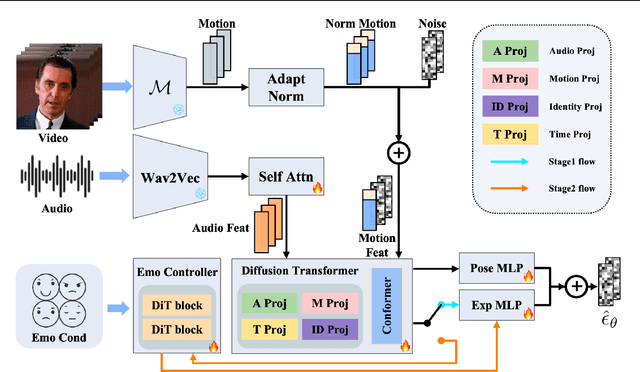



Recent diffusion-based talking face generation models have demonstrated impressive potential in synthesizing videos that accurately match a speech audio clip with a given reference identity. However, existing approaches still encounter significant challenges due to uncontrollable factors, such as inaccurate lip-sync, inappropriate head posture and the lack of fine-grained control over facial expressions. In order to introduce more face-guided conditions beyond speech audio clips, a novel two-stage training framework Playmate is proposed to generate more lifelike facial expressions and talking faces. In the first stage, we introduce a decoupled implicit 3D representation along with a meticulously designed motion-decoupled module to facilitate more accurate attribute disentanglement and generate expressive talking videos directly from audio cues. Then, in the second stage, we introduce an emotion-control module to encode emotion control information into the latent space, enabling fine-grained control over emotions and thereby achieving the ability to generate talking videos with desired emotion. Extensive experiments demonstrate that Playmate outperforms existing state-of-the-art methods in terms of video quality and lip-synchronization, and improves flexibility in controlling emotion and head pose. The code will be available at https://playmate111.github.io.
Uni-Renderer: Unifying Rendering and Inverse Rendering Via Dual Stream Diffusion
Dec 19, 2024



Rendering and inverse rendering are pivotal tasks in both computer vision and graphics. The rendering equation is the core of the two tasks, as an ideal conditional distribution transfer function from intrinsic properties to RGB images. Despite achieving promising results of existing rendering methods, they merely approximate the ideal estimation for a specific scene and come with a high computational cost. Additionally, the inverse conditional distribution transfer is intractable due to the inherent ambiguity. To address these challenges, we propose a data-driven method that jointly models rendering and inverse rendering as two conditional generation tasks within a single diffusion framework. Inspired by UniDiffuser, we utilize two distinct time schedules to model both tasks, and with a tailored dual streaming module, we achieve cross-conditioning of two pre-trained diffusion models. This unified approach, named Uni-Renderer, allows the two processes to facilitate each other through a cycle-consistent constrain, mitigating ambiguity by enforcing consistency between intrinsic properties and rendered images. Combined with a meticulously prepared dataset, our method effectively decomposition of intrinsic properties and demonstrates a strong capability to recognize changes during rendering. We will open-source our training and inference code to the public, fostering further research and development in this area.
GaussianProperty: Integrating Physical Properties to 3D Gaussians with LMMs
Dec 15, 2024Estimating physical properties for visual data is a crucial task in computer vision, graphics, and robotics, underpinning applications such as augmented reality, physical simulation, and robotic grasping. However, this area remains under-explored due to the inherent ambiguities in physical property estimation. To address these challenges, we introduce GaussianProperty, a training-free framework that assigns physical properties of materials to 3D Gaussians. Specifically, we integrate the segmentation capability of SAM with the recognition capability of GPT-4V(ision) to formulate a global-local physical property reasoning module for 2D images. Then we project the physical properties from multi-view 2D images to 3D Gaussians using a voting strategy. We demonstrate that 3D Gaussians with physical property annotations enable applications in physics-based dynamic simulation and robotic grasping. For physics-based dynamic simulation, we leverage the Material Point Method (MPM) for realistic dynamic simulation. For robot grasping, we develop a grasping force prediction strategy that estimates a safe force range required for object grasping based on the estimated physical properties. Extensive experiments on material segmentation, physics-based dynamic simulation, and robotic grasping validate the effectiveness of our proposed method, highlighting its crucial role in understanding physical properties from visual data. Online demo, code, more cases and annotated datasets are available on \href{https://Gaussian-Property.github.io}{this https URL}.
MultiGO: Towards Multi-level Geometry Learning for Monocular 3D Textured Human Reconstruction
Dec 04, 2024



This paper investigates the research task of reconstructing the 3D clothed human body from a monocular image. Due to the inherent ambiguity of single-view input, existing approaches leverage pre-trained SMPL(-X) estimation models or generative models to provide auxiliary information for human reconstruction. However, these methods capture only the general human body geometry and overlook specific geometric details, leading to inaccurate skeleton reconstruction, incorrect joint positions, and unclear cloth wrinkles. In response to these issues, we propose a multi-level geometry learning framework. Technically, we design three key components: skeleton-level enhancement, joint-level augmentation, and wrinkle-level refinement modules. Specifically, we effectively integrate the projected 3D Fourier features into a Gaussian reconstruction model, introduce perturbations to improve joint depth estimation during training, and refine the human coarse wrinkles by resembling the de-noising process of diffusion model. Extensive quantitative and qualitative experiments on two out-of-distribution test sets show the superior performance of our approach compared to state-of-the-art (SOTA) methods.
Human Multi-View Synthesis from a Single-View Model:Transferred Body and Face Representations
Dec 04, 2024



Generating multi-view human images from a single view is a complex and significant challenge. Although recent advancements in multi-view object generation have shown impressive results with diffusion models, novel view synthesis for humans remains constrained by the limited availability of 3D human datasets. Consequently, many existing models struggle to produce realistic human body shapes or capture fine-grained facial details accurately. To address these issues, we propose an innovative framework that leverages transferred body and facial representations for multi-view human synthesis. Specifically, we use a single-view model pretrained on a large-scale human dataset to develop a multi-view body representation, aiming to extend the 2D knowledge of the single-view model to a multi-view diffusion model. Additionally, to enhance the model's detail restoration capability, we integrate transferred multimodal facial features into our trained human diffusion model. Experimental evaluations on benchmark datasets demonstrate that our approach outperforms the current state-of-the-art methods, achieving superior performance in multi-view human synthesis.
Debatts: Zero-Shot Debating Text-to-Speech Synthesis
Nov 10, 2024



In debating, rebuttal is one of the most critical stages, where a speaker addresses the arguments presented by the opposing side. During this process, the speaker synthesizes their own persuasive articulation given the context from the opposing side. This work proposes a novel zero-shot text-to-speech synthesis system for rebuttal, namely Debatts. Debatts takes two speech prompts, one from the opposing side (i.e. opponent) and one from the speaker. The prompt from the opponent is supposed to provide debating style prosody, and the prompt from the speaker provides identity information. In particular, we pretrain the Debatts system from in-the-wild dataset, and integrate an additional reference encoder to take debating prompt for style. In addition, we also create a debating dataset to develop Debatts. In this setting, Debatts can generate a debating-style speech in rebuttal for any voices. Experimental results confirm the effectiveness of the proposed system in comparison with the classic zero-shot TTS systems.
FlexGen: Flexible Multi-View Generation from Text and Image Inputs
Oct 14, 2024



In this work, we introduce FlexGen, a flexible framework designed to generate controllable and consistent multi-view images, conditioned on a single-view image, or a text prompt, or both. FlexGen tackles the challenges of controllable multi-view synthesis through additional conditioning on 3D-aware text annotations. We utilize the strong reasoning capabilities of GPT-4V to generate 3D-aware text annotations. By analyzing four orthogonal views of an object arranged as tiled multi-view images, GPT-4V can produce text annotations that include 3D-aware information with spatial relationship. By integrating the control signal with proposed adaptive dual-control module, our model can generate multi-view images that correspond to the specified text. FlexGen supports multiple controllable capabilities, allowing users to modify text prompts to generate reasonable and corresponding unseen parts. Additionally, users can influence attributes such as appearance and material properties, including metallic and roughness. Extensive experiments demonstrate that our approach offers enhanced multiple controllability, marking a significant advancement over existing multi-view diffusion models. This work has substantial implications for fields requiring rapid and flexible 3D content creation, including game development, animation, and virtual reality. Project page: https://xxu068.github.io/flexgen.github.io/.
MaskGCT: Zero-Shot Text-to-Speech with Masked Generative Codec Transformer
Sep 01, 2024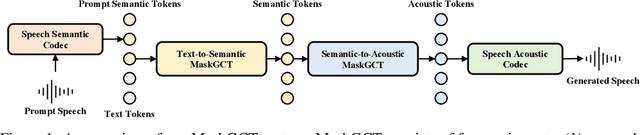



Nowadays, large-scale text-to-speech (TTS) systems are primarily divided into two types: autoregressive and non-autoregressive. The autoregressive systems have certain deficiencies in robustness and cannot control speech duration. In contrast, non-autoregressive systems require explicit prediction of phone-level duration, which may compromise their naturalness. We introduce the Masked Generative Codec Transformer (MaskGCT), a fully non-autoregressive model for TTS that does not require precise alignment information between text and speech. MaskGCT is a two-stage model: in the first stage, the model uses text to predict semantic tokens extracted from a speech self-supervised learning (SSL) model, and in the second stage, the model predicts acoustic tokens conditioned on these semantic tokens. MaskGCT follows the \textit{mask-and-predict} learning paradigm. During training, MaskGCT learns to predict masked semantic or acoustic tokens based on given conditions and prompts. During inference, the model generates tokens of a specified length in a parallel manner. We scale MaskGCT to a large-scale multilingual dataset with 100K hours of in-the-wild speech. Our experiments demonstrate that MaskGCT achieves superior or competitive performance compared to state-of-the-art zero-shot TTS systems in terms of quality, similarity, and intelligibility while offering higher generation efficiency than diffusion-based or autoregressive TTS models. Audio samples are available at https://maskgct.github.io.