 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive-avg-pooling based Attention Vision Transformer for Face Anti-spoofing
Jan 10, 2024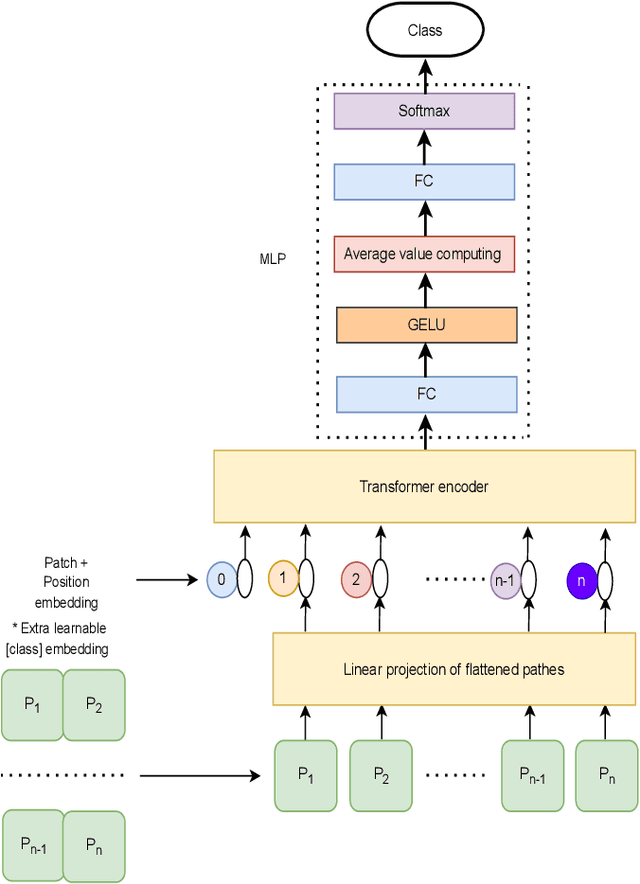
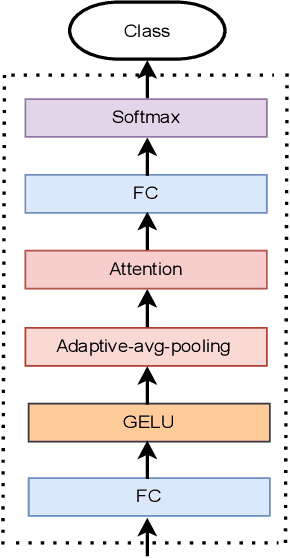

Traditional vision transformer consists of two parts: transformer encoder and multi-layer perception (MLP). The former plays the role of feature learning to obtain better representation, while the latter plays the role of classification. Here, the MLP is constituted of two fully connected (FC) layers, average value computing, FC layer and softmax layer. However, due to the use of average value computing module, some useful information may get lost, which we plan to preserve by the use of alternative framework. In this work, we propose a novel vision transformer referred to as adaptive-avg-pooling based attention vision transformer (AAViT) that uses modules of adaptive average pooling and attention to replace the module of average value computing. We explore the proposed AAViT for the studies on face anti-spoofing using Replay-Attack database. The experiments show that the AAViT outperforms vision transformer in face anti-spoofing by producing a reduced equal error rate. In addition, we found that the proposed AAViT can perform much better than some commonly used neural networks such as ResNet and some other known systems on the Replay-Attack corpus.