 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVSpeech: An Integrated and Scalable Pipeline for Human-Like Speech Modeling with Paralinguistic Vocalizations
Aug 06, 2025Paralinguistic vocalizations-including non-verbal sounds like laughter and breathing, as well as lexicalized interjections such as "uhm" and "oh"-are integral to natural spoken communication. Despite their importance in conveying affect, intent, and interactional cues, such cues remain largely overlooked in conventional automatic speech recognition (ASR) and text-to-speech (TTS) systems. We present NVSpeech, an integrated and scalable pipeline that bridges the recognition and synthesis of paralinguistic vocalizations, encompassing dataset construction, ASR modeling, and controllable TTS. (1) We introduce a manually annotated dataset of 48,430 human-spoken utterances with 18 word-level paralinguistic categories. (2) We develop the paralinguistic-aware ASR model, which treats paralinguistic cues as inline decodable tokens (e.g., "You're so funny [Laughter]"), enabling joint lexical and non-verbal transcription. This model is then used to automatically annotate a large corpus, the first large-scale Chinese dataset of 174,179 utterances (573 hours) with word-level alignment and paralingustic cues. (3) We finetune zero-shot TTS models on both human- and auto-labeled data to enable explicit control over paralinguistic vocalizations, allowing context-aware insertion at arbitrary token positions for human-like speech synthesis. By unifying the recognition and generation of paralinguistic vocalizations, NVSpeech offers the first open, large-scale, word-level annotated pipeline for expressive speech modeling in Mandarin, integrating recognition and synthesis in a scalable and controllable manner. Dataset and audio demos are available at https://nvspeech170k.github.io/.
MaskGCT: Zero-Shot Text-to-Speech with Masked Generative Codec Transformer
Sep 01, 2024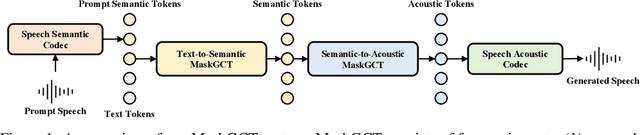



Nowadays, large-scale text-to-speech (TTS) systems are primarily divided into two types: autoregressive and non-autoregressive. The autoregressive systems have certain deficiencies in robustness and cannot control speech duration. In contrast, non-autoregressive systems require explicit prediction of phone-level duration, which may compromise their naturalness. We introduce the Masked Generative Codec Transformer (MaskGCT), a fully non-autoregressive model for TTS that does not require precise alignment information between text and speech. MaskGCT is a two-stage model: in the first stage, the model uses text to predict semantic tokens extracted from a speech self-supervised learning (SSL) model, and in the second stage, the model predicts acoustic tokens conditioned on these semantic tokens. MaskGCT follows the \textit{mask-and-predict} learning paradigm. During training, MaskGCT learns to predict masked semantic or acoustic tokens based on given conditions and prompts. During inference, the model generates tokens of a specified length in a parallel manner. We scale MaskGCT to a large-scale multilingual dataset with 100K hours of in-the-wild speech. Our experiments demonstrate that MaskGCT achieves superior or competitive performance compared to state-of-the-art zero-shot TTS systems in terms of quality, similarity, and intelligibility while offering higher generation efficiency than diffusion-based or autoregressive TTS models. Audio samples are available at https://maskgct.github.io.
Revisiting IPA-based Cross-lingual Text-to-speech
Oct 18, 2021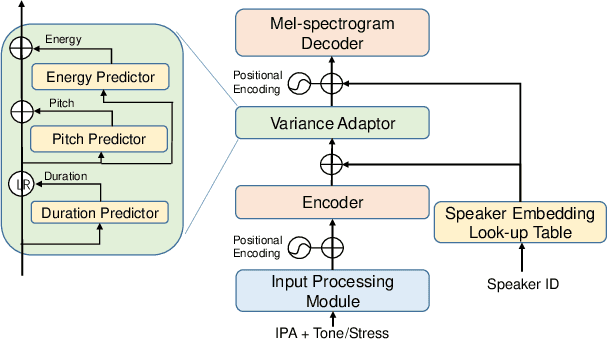
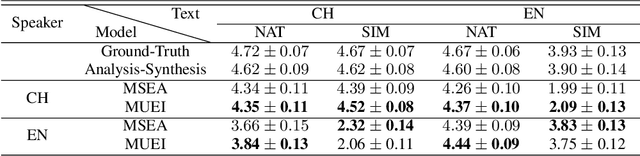
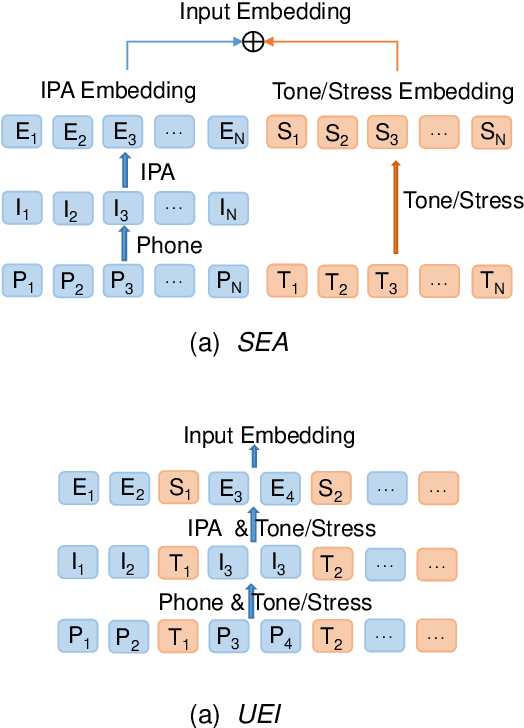
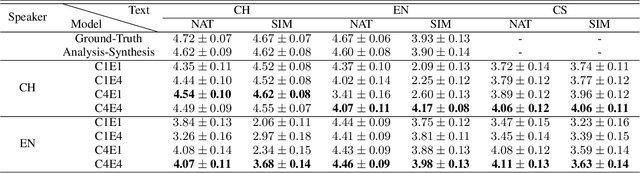
International Phonetic Alphabet (IPA) has been widely used in cross-lingual text-to-speech (TTS) to achieve cross-lingual voice cloning (CL VC). However, IPA itself has been understudied in cross-lingual TTS. In this paper, we report some empirical findings of building a cross-lingual TTS model using IPA as inputs. Experiments show that the way to process the IPA and suprasegmental sequence has a negligible impact on the CL VC performance. Furthermore, we find that using a dataset including one speaker per language to build an IPA-based TTS system would fail CL VC since the language-unique IPA and tone/stress symbols could leak the speaker information. In addition, we experiment with different combinations of speakers in the training dataset to further investigate the effect of the number of speakers on the CL VC performance.
Exploring Timbre Disentanglement in Non-Autoregressive Cross-Lingual Text-to-Speech
Oct 14, 2021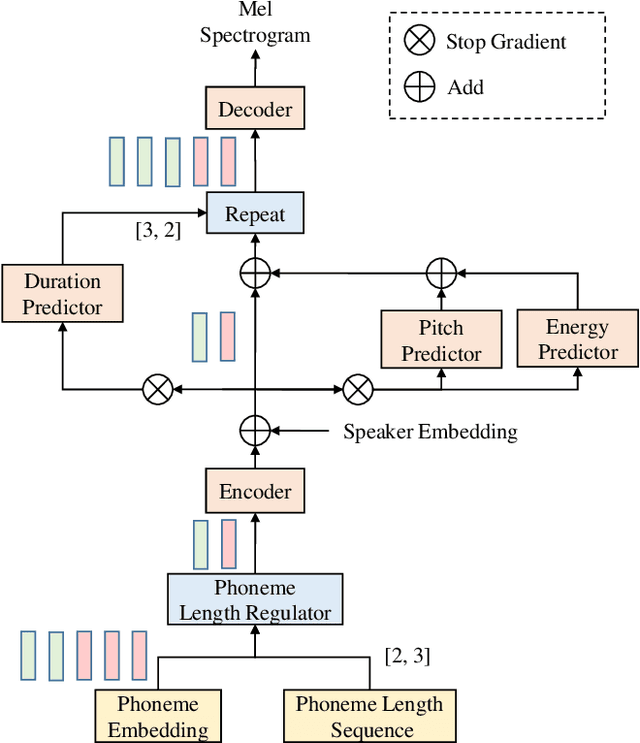

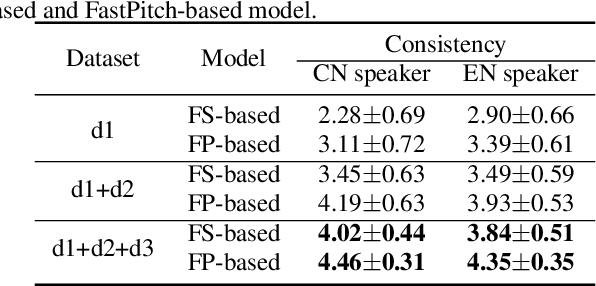
In this paper, we present a FastPitch-based non-autoregressive cross-lingual Text-to-Speech (TTS) model built with language independent input representation and monolingual force aligners. We propose a phoneme length regulator that solves the length mismatch problem between language-independent phonemes and monolingual alignment results. Our experiments show that (1) an increasing number of training speakers encourages non-autoregressive cross-lingual TTS model to disentangle speaker and language representations, and (2) variance adaptors of FastPitch model can help disentangle speaker identity from learned representations in cross-lingual TTS. The subjective evaluation shows that our proposed model is able to achieve decent speaker consistency and similarity. We further improve the naturalness of Mandarin-dominated mixed-lingual utterances by utilizing the controllability of our proposed model.