 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetis: A Foundation Speech Generation Model with Masked Generative Pre-training
Feb 05, 2025We introduce Metis, a foundation model for unified speech generation. Unlike previous task-specific or multi-task models, Metis follows a pre-training and fine-tuning paradigm. It is pre-trained on large-scale unlabeled speech data using masked generative modeling and then fine-tuned to adapt to diverse speech generation tasks. Specifically, 1) Metis utilizes two discrete speech representations: SSL tokens derived from speech self-supervised learning (SSL) features, and acoustic tokens directly quantized from waveforms. 2) Metis performs masked generative pre-training on SSL tokens, utilizing 300K hours of diverse speech data, without any additional condition. 3) Through fine-tuning with task-specific conditions, Metis achieves efficient adaptation to various speech generation tasks while supporting multimodal input, even when using limited data and trainable parameters. Experiments demonstrate that Metis can serve as a foundation model for unified speech generation: Metis outperforms state-of-the-art task-specific or multi-task systems across five speech generation tasks, including zero-shot text-to-speech, voice conversion, target speaker extraction, speech enhancement, and lip-to-speech, even with fewer than 20M trainable parameters or 300 times less training data. Audio samples are are available at https://metis-demo.github.io/.
MaskGCT: Zero-Shot Text-to-Speech with Masked Generative Codec Transformer
Sep 01, 2024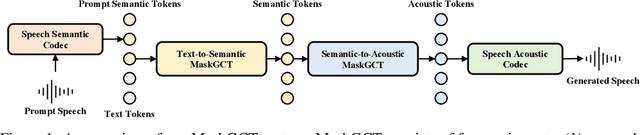



Nowadays, large-scale text-to-speech (TTS) systems are primarily divided into two types: autoregressive and non-autoregressive. The autoregressive systems have certain deficiencies in robustness and cannot control speech duration. In contrast, non-autoregressive systems require explicit prediction of phone-level duration, which may compromise their naturalness. We introduce the Masked Generative Codec Transformer (MaskGCT), a fully non-autoregressive model for TTS that does not require precise alignment information between text and speech. MaskGCT is a two-stage model: in the first stage, the model uses text to predict semantic tokens extracted from a speech self-supervised learning (SSL) model, and in the second stage, the model predicts acoustic tokens conditioned on these semantic tokens. MaskGCT follows the \textit{mask-and-predict} learning paradigm. During training, MaskGCT learns to predict masked semantic or acoustic tokens based on given conditions and prompts. During inference, the model generates tokens of a specified length in a parallel manner. We scale MaskGCT to a large-scale multilingual dataset with 100K hours of in-the-wild speech. Our experiments demonstrate that MaskGCT achieves superior or competitive performance compared to state-of-the-art zero-shot TTS systems in terms of quality, similarity, and intelligibility while offering higher generation efficiency than diffusion-based or autoregressive TTS models. Audio samples are available at https://maskgct.github.io.
On Diffusion Process in SE-invariant Space
Mar 03, 2024
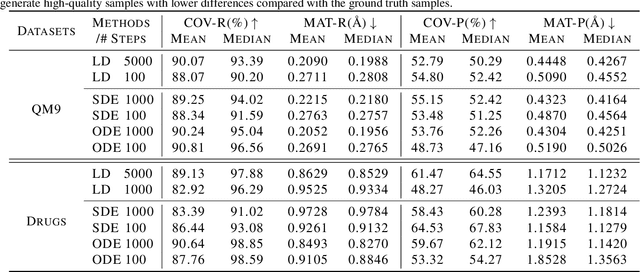
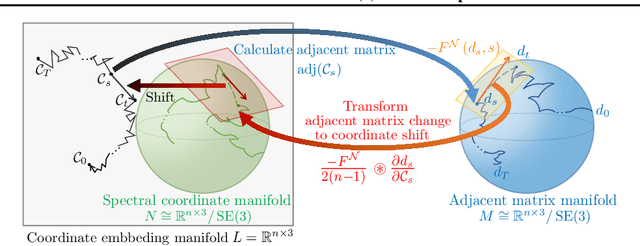
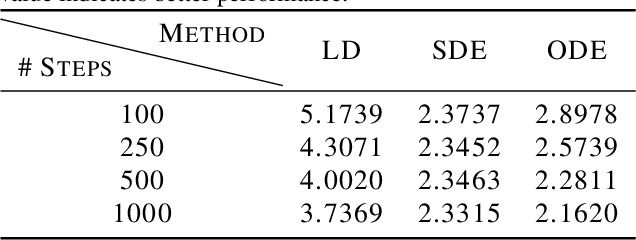
Sampling viable 3D structures (e.g., molecules and point clouds) with SE(3)-invariance using diffusion-based models proved promising in a variety of real-world applications, wherein SE(3)-invariant properties can be naturally characterized by the inter-point distance manifold. However, due to the non-trivial geometry, we still lack a comprehensive understanding of the diffusion mechanism within such SE(3)-invariant space. This study addresses this gap by mathematically delineating the diffusion mechanism under SE(3)-invariance, via zooming into the interaction behavior between coordinates and the inter-point distance manifold through the lens of differential geometry. Upon this analysis, we propose accurate and projection-free diffusion SDE and ODE accordingly. Such formulations enable enhancing the performance and the speed of generation pathways; meanwhile offering valuable insights into other systems incorporating SE(3)-invariance.