 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNV-Bench: Benchmark of Nonverbal Vocalization Synthesis for Expressive Text-to-Speech Generation
Mar 16, 2026While recent text-to-speech (TTS) systems increasingly integrate nonverbal vocalizations (NVs), their evaluations lack standardized metrics and reliable ground-truth references. To bridge this gap, we propose NV-Bench, the first benchmark grounded in a functional taxonomy that treats NVs as communicative acts rather than acoustic artifacts. NV-Bench comprises 1,651 multi-lingual, in-the-wild utterances with paired human reference audio, balanced across 14 NV categories. We introduce a dual-dimensional evaluation protocol: (1) Instruction Alignment, utilizing the proposed paralinguistic character error rate (PCER) to assess controllability, (2) Acoustic Fidelity, measuring the distributional gap to real recordings to assess acoustic realism. We evaluate diverse TTS models and develop two baselines. Experimental results demonstrate a strong correlation between our objective metrics and human perception, establishing NV-Bench as a standardized evaluation framework.
SpeechJudge: Towards Human-Level Judgment for Speech Naturalness
Nov 11, 2025

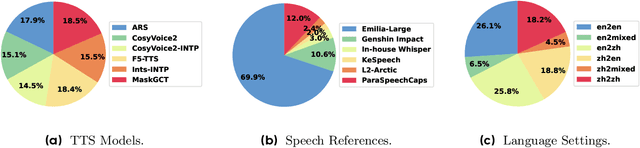
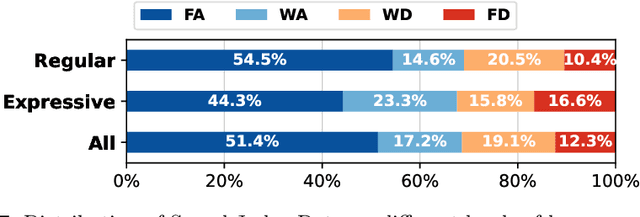
Aligning large generative models with human feedback is a critical challenge. In speech synthesis, this is particularly pronounced due to the lack of a large-scale human preference dataset, which hinders the development of models that truly align with human perception. To address this, we introduce SpeechJudge, a comprehensive suite comprising a dataset, a benchmark, and a reward model centered on naturalness--one of the most fundamental subjective metrics for speech synthesis. First, we present SpeechJudge-Data, a large-scale human feedback corpus of 99K speech pairs. The dataset is constructed using a diverse set of advanced zero-shot text-to-speech (TTS) models across diverse speech styles and multiple languages, with human annotations for both intelligibility and naturalness preference. From this, we establish SpeechJudge-Eval, a challenging benchmark for speech naturalness judgment. Our evaluation reveals that existing metrics and AudioLLMs struggle with this task; the leading model, Gemini-2.5-Flash, achieves less than 70% agreement with human judgment, highlighting a significant gap for improvement. To bridge this gap, we develop SpeechJudge-GRM, a generative reward model (GRM) based on Qwen2.5-Omni-7B. It is trained on SpeechJudge-Data via a two-stage post-training process: Supervised Fine-Tuning (SFT) with Chain-of-Thought rationales followed by Reinforcement Learning (RL) with GRPO on challenging cases. On the SpeechJudge-Eval benchmark, the proposed SpeechJudge-GRM demonstrates superior performance, achieving 77.2% accuracy (and 79.4% after inference-time scaling @10) compared to a classic Bradley-Terry reward model (72.7%). Furthermore, SpeechJudge-GRM can be also employed as a reward function during the post-training of speech generation models to facilitate their alignment with human preferences.
NVSpeech: An Integrated and Scalable Pipeline for Human-Like Speech Modeling with Paralinguistic Vocalizations
Aug 06, 2025Paralinguistic vocalizations-including non-verbal sounds like laughter and breathing, as well as lexicalized interjections such as "uhm" and "oh"-are integral to natural spoken communication. Despite their importance in conveying affect, intent, and interactional cues, such cues remain largely overlooked in conventional automatic speech recognition (ASR) and text-to-speech (TTS) systems. We present NVSpeech, an integrated and scalable pipeline that bridges the recognition and synthesis of paralinguistic vocalizations, encompassing dataset construction, ASR modeling, and controllable TTS. (1) We introduce a manually annotated dataset of 48,430 human-spoken utterances with 18 word-level paralinguistic categories. (2) We develop the paralinguistic-aware ASR model, which treats paralinguistic cues as inline decodable tokens (e.g., "You're so funny [Laughter]"), enabling joint lexical and non-verbal transcription. This model is then used to automatically annotate a large corpus, the first large-scale Chinese dataset of 174,179 utterances (573 hours) with word-level alignment and paralingustic cues. (3) We finetune zero-shot TTS models on both human- and auto-labeled data to enable explicit control over paralinguistic vocalizations, allowing context-aware insertion at arbitrary token positions for human-like speech synthesis. By unifying the recognition and generation of paralinguistic vocalizations, NVSpeech offers the first open, large-scale, word-level annotated pipeline for expressive speech modeling in Mandarin, integrating recognition and synthesis in a scalable and controllable manner. Dataset and audio demos are available at https://nvspeech170k.github.io/.
Metis: A Foundation Speech Generation Model with Masked Generative Pre-training
Feb 05, 2025We introduce Metis, a foundation model for unified speech generation. Unlike previous task-specific or multi-task models, Metis follows a pre-training and fine-tuning paradigm. It is pre-trained on large-scale unlabeled speech data using masked generative modeling and then fine-tuned to adapt to diverse speech generation tasks. Specifically, 1) Metis utilizes two discrete speech representations: SSL tokens derived from speech self-supervised learning (SSL) features, and acoustic tokens directly quantized from waveforms. 2) Metis performs masked generative pre-training on SSL tokens, utilizing 300K hours of diverse speech data, without any additional condition. 3) Through fine-tuning with task-specific conditions, Metis achieves efficient adaptation to various speech generation tasks while supporting multimodal input, even when using limited data and trainable parameters. Experiments demonstrate that Metis can serve as a foundation model for unified speech generation: Metis outperforms state-of-the-art task-specific or multi-task systems across five speech generation tasks, including zero-shot text-to-speech, voice conversion, target speaker extraction, speech enhancement, and lip-to-speech, even with fewer than 20M trainable parameters or 300 times less training data. Audio samples are are available at https://metis-demo.github.io/.
Overview of the Amphion Toolkit (v0.2)
Jan 26, 2025



Amphion is an open-source toolkit for Audio, Music, and Speech Generation, designed to lower the entry barrier for junior researchers and engineers in these fields. It provides a versatile framework that supports a variety of generation tasks and models. In this report, we introduce Amphion v0.2, the second major release developed in 2024. This release features a 100K-hour open-source multilingual dataset, a robust data preparation pipeline, and novel models for tasks such as text-to-speech, audio coding, and voice conversion. Furthermore, the report includes multiple tutorials that guide users through the functionalities and usage of the newly released models.
AToM: Aligning Text-to-Motion Model at Event-Level with GPT-4Vision Reward
Nov 27, 2024



Recently, text-to-motion models have opened new possibilities for creating realistic human motion with greater efficiency and flexibility. However, aligning motion generation with event-level textual descriptions presents unique challenges due to the complex relationship between textual prompts and desired motion outcomes. To address this, we introduce AToM, a framework that enhances the alignment between generated motion and text prompts by leveraging reward from GPT-4Vision. AToM comprises three main stages: Firstly, we construct a dataset MotionPrefer that pairs three types of event-level textual prompts with generated motions, which cover the integrity, temporal relationship and frequency of motion. Secondly, we design a paradigm that utilizes GPT-4Vision for detailed motion annotation, including visual data formatting, task-specific instructions and scoring rules for each sub-task. Finally, we fine-tune an existing text-to-motion model using reinforcement learning guided by this paradigm. Experimental results demonstrate that AToM significantly improves the event-level alignment quality of text-to-motion generation.
Rhythmic Foley: A Framework For Seamless Audio-Visual Alignment In Video-to-Audio Synthesis
Sep 13, 2024



Our research introduces an innovative framework for video-to-audio synthesis, which solves the problems of audio-video desynchronization and semantic loss in the audio. By incorporating a semantic alignment adapter and a temporal synchronization adapter, our method significantly improves semantic integrity and the precision of beat point synchronization, particularly in fast-paced action sequences. Utilizing a contrastive audio-visual pre-trained encoder, our model is trained with video and high-quality audio data, improving the quality of the generated audio. This dual-adapter approach empowers users with enhanced control over audio semantics and beat effects, allowing the adjustment of the controller to achieve better results. Extensive experiments substantiate the effectiveness of our framework in achieving seamless audio-visual alignment.
REPARO: Compositional 3D Assets Generation with Differentiable 3D Layout Alignment
May 28, 2024



Traditional image-to-3D models often struggle with scenes containing multiple objects due to biases and occlusion complexities. To address this challenge, we present REPARO, a novel approach for compositional 3D asset generation from single images. REPARO employs a two-step process: first, it extracts individual objects from the scene and reconstructs their 3D meshes using off-the-shelf image-to-3D models; then, it optimizes the layout of these meshes through differentiable rendering techniques, ensuring coherent scene composition. By integrating optimal transport-based long-range appearance loss term and high-level semantic loss term in the differentiable rendering, REPARO can effectively recover the layout of 3D assets. The proposed method can significantly enhance object independence, detail accuracy, and overall scene coherence. Extensive evaluation of multi-object scenes demonstrates that our REPARO offers a comprehensive approach to address the complexities of multi-object 3D scene generation from single images.
BATON: Aligning Text-to-Audio Model with Human Preference Feedback
Feb 01, 2024



With the development of AI-Generated Content (AIGC), text-to-audio models are gaining widespread attention. However, it is challenging for these models to generate audio aligned with human preference due to the inherent information density of natural language and limited model understanding ability. To alleviate this issue, we formulate the BATON, a framework designed to enhance the alignment between generated audio and text prompt using human preference feedback. Our BATON comprises three key stages: Firstly, we curated a dataset containing both prompts and the corresponding generated audio, which was then annotated based on human feedback. Secondly, we introduced a reward model using the constructed dataset, which can mimic human preference by assigning rewards to input text-audio pairs. Finally, we employed the reward model to fine-tune an off-the-shelf text-to-audio model. The experiment results demonstrate that our BATON can significantly improve the generation quality of the original text-to-audio models, concerning audio integrity, temporal relationship, and alignment with human preference.