 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtualMLE: A Virtual ML Engineer that Optimizes Sequential Recommenders
Jun 02, 2026Recent advancements in Large Language Models (LLMs) have demonstrated remarkable capabilities in reasoning, reflection, and tool utilization, unlocking new paradigms for automating complex engineering workflows. However, in the domain of sequential recommendation (SR), tuning models on new datasets still relies heavily on the manual trial-and-error of experienced machine learning engineers. To bridge this gap, we propose \textbf{VirtualMLE}, an LLM-agent framework that leverages the cognitive capabilities of LLMs to organize recommender optimizing into a closed loop of execution, reflection, and memory update. After each trial, the agent explicitly analyzes the observed outcomes and stores concise heuristic feedback in a hierarchical memory system. We evaluate VirtualMLE on three Amazon SR benchmarks with two representative backbones, SASRec and HSTU. VirtualMLE reaches competitive recommendation quality with substantially fewer trials. Furthermore, we observe that cognition summaries distilled from previous datasets can significantly accelerate the search process on unseen datasets, demonstrating the potential of transferring tuning heuristics. Overall, our results provide compelling evidence that LLM agents equipped with reflection and memory can serve as practical virtual engineers to automate and amortize heuristic learning in SR optimization. Our codes are available.
OmniVerifier-M1: Multimodal Meta-Verifier with Explicit Structured Recalibration
May 27, 2026Visual outcomes are increasingly central to multimodal large language models, making reliable and fine-grained verification essential for scaling generalist foundation models. In this work, we investigate multimodal meta-verification, which leverages verifier-generated rationales rather than decision-only signals, and explore how to effectively incorporate meta-verification feedback into multimodal verifier training. We identify two key findings. First, symbolic verifier outputs (e.g., bounding boxes) outperform textual explanations as meta-verification rationales, enabling efficient rule-based reinforcement learning rewards while avoiding reliance on model-based rewards from auxiliary judge models. Second, decoupling reinforcement learning objectives for binary judgment and meta-verification substantially outperforms joint reward optimization, due to intrinsic differences in output structure and learning dynamics. Based on these insights, we train OmniVerifier-M1, a generalist visual verifier leveraging symbolic meta-verification and decoupled reinforcement learning. OmniVerifier-M1 provides robust verification and fine-grained error localization, and further enables M1-TTS, a verifier-driven agentic generation system achieving dynamic region-level self-correction. This approach paves the way for more reliable, interpretable, and fine-grained multimodal verification, supporting safer and more controllable foundation model deployment.
Visual-Advantage On-Policy Distillation for Vision-Language Models
May 21, 2026On-policy knowledge distillation has proven effective for language models, yet its application to vision-language models (VLMs) remains underexplored. We observe that standard on-policy distillation can improve a student's output quality while failing to strengthen its reliance on visual input: on vision-critical tokens, the student's predictions remain largely unchanged whether or not fine-grained visual detail is present, even though the teacher's predictions depend heavily on it.To make this difference observable, we introduce visual advantage (VA), the token-level log-probability difference when the teacher scores a student-generated rollout with versus without access to fine-grained visual detail. VA is concentrated in a small minority of tokens, and these high-VA tokens are the ones that actually carry the visual supervision signal. This motivates a distillation objective that treats them differently from language scaffolding, so their contribution is not diluted by the abundant surrounding language tokens.We propose Visual-Advantage On-Policy Distillation (VA-OPD), which uses VA at two granularities: rollout-level reweighting by trajectory-averaged VA, and token-level KL averaged within high-VA and low-VA groups separately. We train on two math datasets (Geometry3K and ViRL39K) and evaluate on eight benchmarks covering both mathematical reasoning and visual understanding, across three teacher sizes (4B, 8B, and 32B) on the Qwen3-VL family. VA-OPD improves over standard on-policy distillation on every benchmark, with the gain growing monotonically along both the teacher-size and data-scale axes, suggesting that these factors compound consistently.
TwiSTAR:Think Fast, Think Slow, Then Act,Generative Recommendation with Adaptive Reasoning
May 12, 2026Generative recommendation with Semantic IDs (SIDs) has emerged as a promising paradigm, yet existing methods apply a fixed inference strategy, either fast direct generation or slow chain-of-thought reasoning, uniformly across all user histories. This approach creates a trade-off: fast recommendation model produces suboptimal accuracy on hard samples, while always invoking slow reasoning incurs prohibitive latency and wastes computation on easy cases. To address this, we propose Think Fast, Think Slow, Then Act, a framework that learns to adaptively allocate reasoning effort per user sequence. Our system equips an LLM with three complementary tools: a fast SID-based retriever, a lightweight candidate ranker, and a slow reasoning model that generates explicit rationales before recommending. Crucially, we inject collaborative commonsense into the slow model by transforming item-to-item knowledge into natural language explanations. A planner, trained through supervised warm-up followed by agentic reinforcement learning, dynamically decides which tool to invoke. Experiments on three datasets demonstrate that our method outperforms strong baselines, achieving consistent accuracy gains while reducing inference latency compared to uniform slow reasoning.
Making MLLMs Blind: Adversarial Smuggling Attacks in MLLM Content Moderation
Apr 09, 2026Multimodal Large Language Models (MLLMs) are increasingly being deployed as automated content moderators. Within this landscape, we uncover a critical threat: Adversarial Smuggling Attacks. Unlike adversarial perturbations (for misclassification) and adversarial jailbreaks (for harmful output generation), adversarial smuggling exploits the Human-AI capability gap. It encodes harmful content into human-readable visual formats that remain AI-unreadable, thereby evading automated detection and enabling the dissemination of harmful content. We classify smuggling attacks into two pathways: (1) Perceptual Blindness, disrupting text recognition; and (2) Reasoning Blockade, inhibiting semantic understanding despite successful text recognition. To evaluate this threat, we constructed SmuggleBench, the first comprehensive benchmark comprising 1,700 adversarial smuggling attack instances. Evaluations on SmuggleBench reveal that both proprietary (e.g., GPT-5) and open-source (e.g., Qwen3-VL) state-of-the-art models are vulnerable to this threat, producing Attack Success Rates (ASR) exceeding 90%. By analyzing the vulnerability through the lenses of perception and reasoning, we identify three root causes: the limited capabilities of vision encoders, the robustness gap in OCR, and the scarcity of domain-specific adversarial examples. We conduct a preliminary exploration of mitigation strategies, investigating the potential of test-time scaling (via CoT) and adversarial training (via SFT) to mitigate this threat. Our code is publicly available at https://github.com/zhihengli-casia/smugglebench.
4DRaL: Bridging 4D Radar with LiDAR for Place Recognition using Knowledge Distillation
Mar 27, 2026Place recognition is crucial for loop closure detection and global localization in robotics. Although mainstream algorithms typically rely on cameras and LiDAR, these sensors are susceptible to adverse weather conditions. Fortunately, the recently developed 4D millimeter-wave radar (4D radar) offers a promising solution for all-weather place recognition. However, the inherent noise and sparsity in 4D radar data significantly limit its performance. Thus, in this paper, we propose a novel framework called 4DRaL that leverages knowledge distillation (KD) to enhance the place recognition performance of 4D radar. Its core is to adopt a high-performance LiDAR-to-LiDAR (L2L) place recognition model as a teacher to guide the training of a 4D radar-to-4D radar (R2R) place recognition model. 4DRaL comprises three key KD modules: a local image enhancement module to handle the sparsity of raw 4D radar points, a feature distribution distillation module that ensures the student model generates more discriminative features, and a response distillation module to maintain consistency in feature space between the teacher and student models. More importantly, 4DRaL can also be trained for 4D radar-to-LiDAR (R2L) place recognition through different module configurations. Experimental results prove that 4DRaL achieves state-of-the-art performance in both R2R and R2L tasks regardless of normal or adverse weather.
GLASS: A Generative Recommender for Long-sequence Modeling via SID-Tier and Semantic Search
Feb 05, 2026Leveraging long-term user behavioral patterns is a key trajectory for enhancing the accuracy of modern recommender systems. While generative recommender systems have emerged as a transformative paradigm, they face hurdles in effectively modeling extensive historical sequences. To address this challenge, we propose GLASS, a novel framework that integrates long-term user interests into the generative process via SID-Tier and Semantic Search. We first introduce SID-Tier, a module that maps long-term interactions into a unified interest vector to enhance the prediction of the initial SID token. Unlike traditional retrieval models that struggle with massive item spaces, SID-Tier leverages the compact nature of the semantic codebook to incorporate cross features between the user's long-term history and candidate semantic codes. Furthermore, we present semantic hard search, which utilizes generated coarse-grained semantic ID as dynamic keys to extract relevant historical behaviors, which are then fused via an adaptive gated fusion module to recalibrate the trajectory of subsequent fine-grained tokens. To address the inherent data sparsity in semantic hard search, we propose two strategies: semantic neighbor augmentation and codebook resizing. Extensive experiments on two large-scale real-world datasets, TAOBAO-MM and KuaiRec, demonstrate that GLASS outperforms state-of-the-art baselines, achieving significant gains in recommendation quality. Our codes are made publicly available to facilitate further research in generative recommendation.
MIRROR: Manifold Ideal Reference ReconstructOR for Generalizable AI-Generated Image Detection
Feb 02, 2026High-fidelity generative models have narrowed the perceptual gap between synthetic and real images, posing serious threats to media security. Most existing AI-generated image (AIGI) detectors rely on artifact-based classification and struggle to generalize to evolving generative traces. In contrast, human judgment relies on stable real-world regularities, with deviations from the human cognitive manifold serving as a more generalizable signal of forgery. Motivated by this insight, we reformulate AIGI detection as a Reference-Comparison problem that verifies consistency with the real-image manifold rather than fitting specific forgery cues. We propose MIRROR (Manifold Ideal Reference ReconstructOR), a framework that explicitly encodes reality priors using a learnable discrete memory bank. MIRROR projects an input into a manifold-consistent ideal reference via sparse linear combination, and uses the resulting residuals as robust detection signals. To evaluate whether detectors reach the "superhuman crossover" required to replace human experts, we introduce the Human-AIGI benchmark, featuring a psychophysically curated human-imperceptible subset. Across 14 benchmarks, MIRROR consistently outperforms prior methods, achieving gains of 2.1% on six standard benchmarks and 8.1% on seven in-the-wild benchmarks. On Human-AIGI, MIRROR reaches 89.6% accuracy across 27 generators, surpassing both lay users and visual experts, and further approaching the human perceptual limit as pretrained backbones scale. The code is publicly available at: https://github.com/349793927/MIRROR
Super4DR: 4D Radar-centric Self-supervised Odometry and Gaussian-based Map Optimization
Dec 10, 2025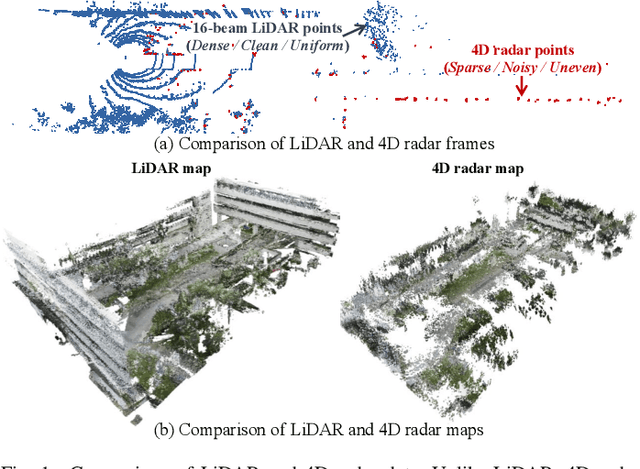
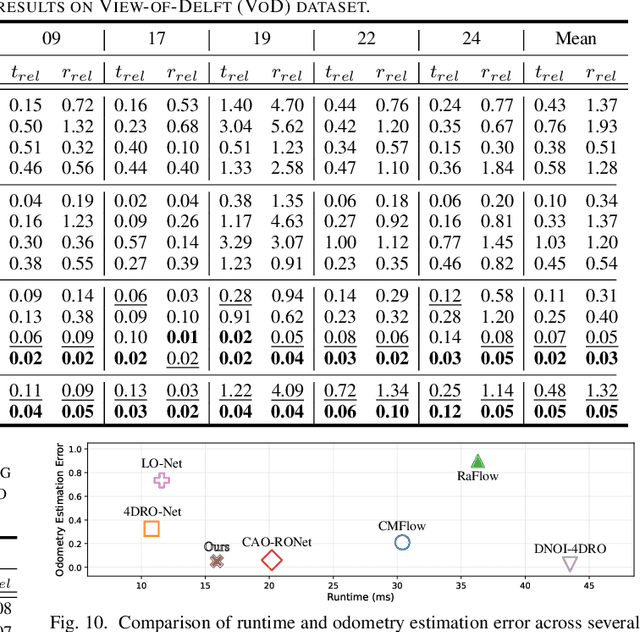
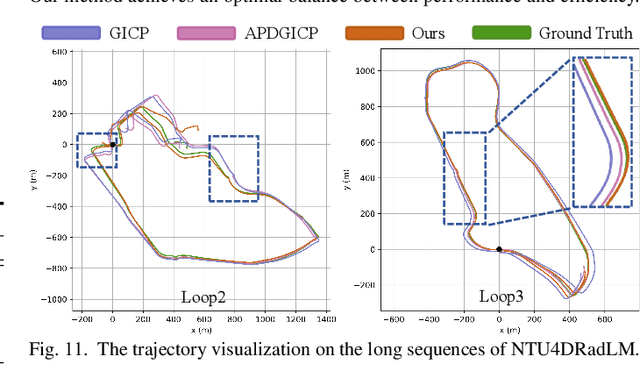

Conventional SLAM systems using visual or LiDAR data often struggle in poor lighting and severe weather. Although 4D radar is suited for such environments, its sparse and noisy point clouds hinder accurate odometry estimation, while the radar maps suffer from obscure and incomplete structures. Thus, we propose Super4DR, a 4D radar-centric framework for learning-based odometry estimation and gaussian-based map optimization. First, we design a cluster-aware odometry network that incorporates object-level cues from the clustered radar points for inter-frame matching, alongside a hierarchical self-supervision mechanism to overcome outliers through spatio-temporal consistency, knowledge transfer, and feature contrast. Second, we propose using 3D gaussians as an intermediate representation, coupled with a radar-specific growth strategy, selective separation, and multi-view regularization, to recover blurry map areas and those undetected based on image texture. Experiments show that Super4DR achieves a 67% performance gain over prior self-supervised methods, nearly matches supervised odometry, and narrows the map quality disparity with LiDAR while enabling multi-modal image rendering.
Towards 3D Object-Centric Feature Learning for Semantic Scene Completion
Nov 18, 2025Vision-based 3D Semantic Scene Completion (SSC) has received growing attention due to its potential in autonomous driving. While most existing approaches follow an ego-centric paradigm by aggregating and diffusing features over the entire scene, they often overlook fine-grained object-level details, leading to semantic and geometric ambiguities, especially in complex environments. To address this limitation, we propose Ocean, an object-centric prediction framework that decomposes the scene into individual object instances to enable more accurate semantic occupancy prediction. Specifically, we first employ a lightweight segmentation model, MobileSAM, to extract instance masks from the input image. Then, we introduce a 3D Semantic Group Attention module that leverages linear attention to aggregate object-centric features in 3D space. To handle segmentation errors and missing instances, we further design a Global Similarity-Guided Attention module that leverages segmentation features for global interaction. Finally, we propose an Instance-aware Local Diffusion module that improves instance features through a generative process and subsequently refines the scene representation in the BEV space. Extensive experiments on the SemanticKITTI and SSCBench-KITTI360 benchmarks demonstrate that Ocean achieves state-of-the-art performance, with mIoU scores of 17.40 and 20.28, respectively.