 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Scaling of Diffusion Transformers for Text-to-Image Generation
Dec 16, 2024



We empirically study the scaling properties of various Diffusion Transformers (DiTs) for text-to-image generation by performing extensive and rigorous ablations, including training scaled DiTs ranging from 0.3B upto 8B parameters on datasets up to 600M images. We find that U-ViT, a pure self-attention based DiT model provides a simpler design and scales more effectively in comparison with cross-attention based DiT variants, which allows straightforward expansion for extra conditions and other modalities. We identify a 2.3B U-ViT model can get better performance than SDXL UNet and other DiT variants in controlled setting. On the data scaling side, we investigate how increasing dataset size and enhanced long caption improve the text-image alignment performance and the learning efficiency.
Robot Localization and Mapping Final Report -- Sequential Adversarial Learning for Self-Supervised Deep Visual Odometry
Sep 08, 2023



Visual odometry (VO) and SLAM have been using multi-view geometry via local structure from motion for decades. These methods have a slight disadvantage in challenging scenarios such as low-texture images, dynamic scenarios, etc. Meanwhile, use of deep neural networks to extract high level features is ubiquitous in computer vision. For VO, we can use these deep networks to extract depth and pose estimates using these high level features. The visual odometry task then can be modeled as an image generation task where the pose estimation is the by-product. This can also be achieved in a self-supervised manner, thereby eliminating the data (supervised) intensive nature of training deep neural networks. Although some works tried the similar approach [1], the depth and pose estimation in the previous works are vague sometimes resulting in accumulation of error (drift) along the trajectory. The goal of this work is to tackle these limitations of past approaches and to develop a method that can provide better depths and pose estimates. To address this, a couple of approaches are explored: 1) Modeling: Using optical flow and recurrent neural networks (RNN) in order to exploit spatio-temporal correlations which can provide more information to estimate depth. 2) Loss function: Generative adversarial network (GAN) [2] is deployed to improve the depth estimation (and thereby pose too), as shown in Figure 1. This additional loss term improves the realism in generated images and reduces artifacts.
CoCoNets: Continuous Contrastive 3D Scene Representations
Apr 08, 2021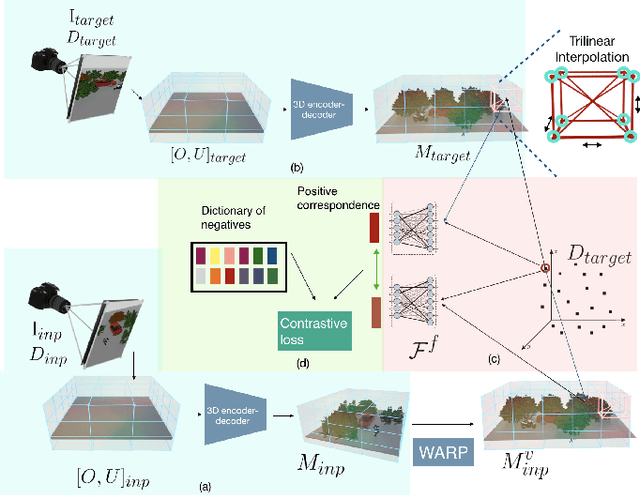
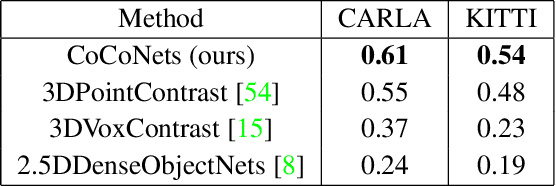
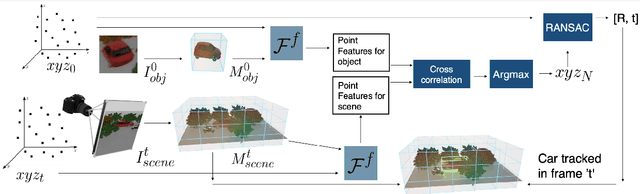

This paper explores self-supervised learning of amodal 3D feature representations from RGB and RGB-D posed images and videos, agnostic to object and scene semantic content, and evaluates the resulting scene representations in the downstream tasks of visual correspondence, object tracking, and object detection. The model infers a latent3D representation of the scene in the form of 3D feature points, where each continuous world 3D point is mapped to its corresponding feature vector. The model is trained for contrastive view prediction by rendering 3D feature clouds in queried viewpoints and matching against the 3D feature point cloud predicted from the query view. Notably, the representation can be queried for any 3D location, even if it is not visible from the input view. Our model brings together three powerful ideas of recent exciting research work: 3D feature grids as a neural bottleneck for view prediction, implicit functions for handling resolution limitations of 3D grids, and contrastive learning for unsupervised training of feature representations. We show the resulting 3D visual feature representations effectively scale across objects and scenes, imagine information occluded or missing from the input viewpoints, track objects over time, align semantically related objects in 3D, and improve 3D object detection. We outperform many existing state-of-the-art methods for 3D feature learning and view prediction, which are either limited by 3D grid spatial resolution, do not attempt to build amodal 3D representations, or do not handle combinatorial scene variability due to their non-convolutional bottlenecks.
HyperDynamics: Meta-Learning Object and Agent Dynamics with Hypernetworks
Mar 17, 2021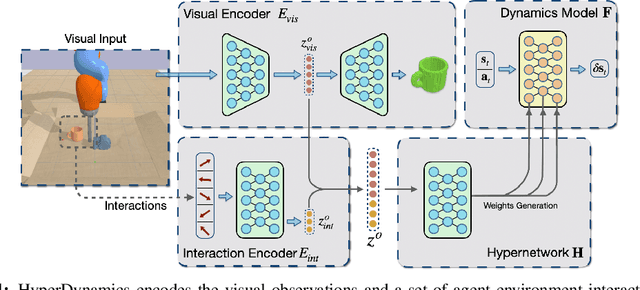
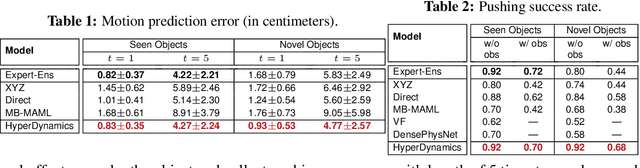

We propose HyperDynamics, a dynamics meta-learning framework that conditions on an agent's interactions with the environment and optionally its visual observations, and generates the parameters of neural dynamics models based on inferred properties of the dynamical system. Physical and visual properties of the environment that are not part of the low-dimensional state yet affect its temporal dynamics are inferred from the interaction history and visual observations, and are implicitly captured in the generated parameters. We test HyperDynamics on a set of object pushing and locomotion tasks. It outperforms existing dynamics models in the literature that adapt to environment variations by learning dynamics over high dimensional visual observations, capturing the interactions of the agent in recurrent state representations, or using gradient-based meta-optimization. We also show our method matches the performance of an ensemble of separately trained experts, while also being able to generalize well to unseen environment variations at test time. We attribute its good performance to the multiplicative interactions between the inferred system properties -- captured in the generated parameters -- and the low-dimensional state representation of the dynamical system.
3D-OES: Viewpoint-Invariant Object-Factorized Environment Simulators
Nov 12, 2020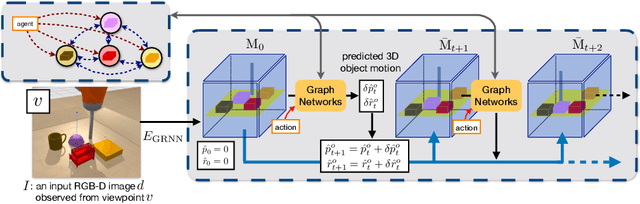


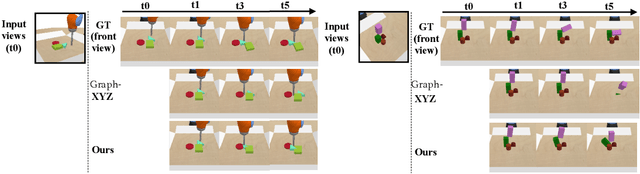
We propose an action-conditioned dynamics model that predicts scene changes caused by object and agent interactions in a viewpoint-invariant 3D neural scene representation space, inferred from RGB-D videos. In this 3D feature space, objects do not interfere with one another and their appearance persists over time and across viewpoints. This permits our model to predict future scenes long in the future by simply "moving" 3D object features based on cumulative object motion predictions. Object motion predictions are computed by a graph neural network that operates over the object features extracted from the 3D neural scene representation. Our model's simulations can be decoded by a neural renderer into2D image views from any desired viewpoint, which aids the interpretability of our latent 3D simulation space. We show our model generalizes well its predictions across varying number and appearances of interacting objects as well as across camera viewpoints, outperforming existing 2D and 3D dynamics models. We further demonstrate sim-to-real transfer of the learnt dynamics by applying our model trained solely in simulation to model-based control for pushing objects to desired locations under clutter on a real robotic setup
Disentangling 3D Prototypical Networks For Few-Shot Concept Learning
Nov 06, 2020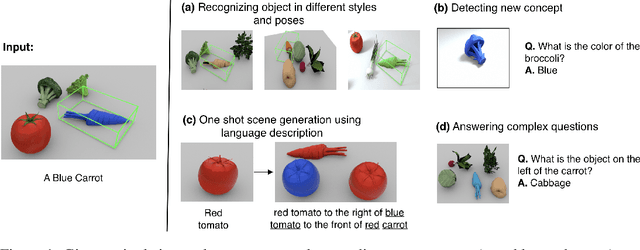
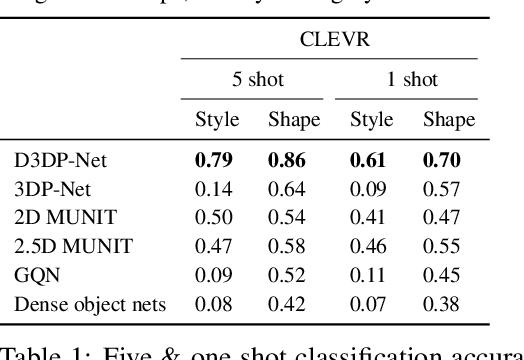
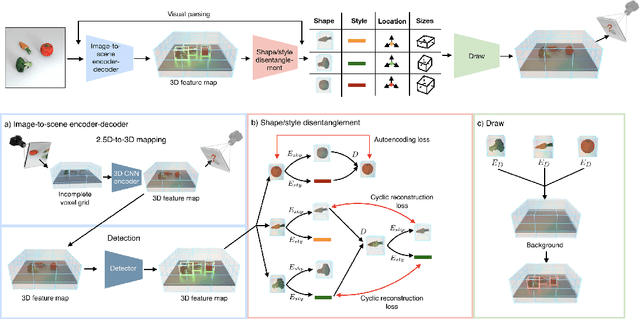
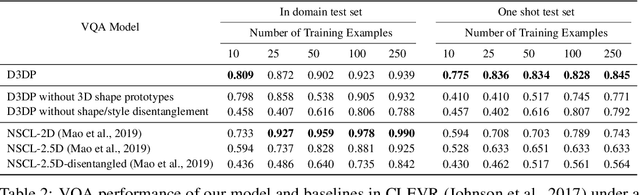
We present neural architectures that disentangle RGB-D images into objects' shapes and styles and a map of the background scene, and explore their applications for few-shot 3D object detection and few-shot concept classification. Our networks incorporate architectural biases that reflect the image formation process, 3D geometry of the world scene, and shape-style interplay. They are trained end-to-end self-supervised by predicting views in static scenes, alongside a small number of 3D object boxes. Objects and scenes are represented in terms of 3D feature grids in the bottleneck of the network. We show that the proposed 3D neural representations are compositional: they can generate novel 3D scene feature maps by mixing object shapes and styles, resizing and adding the resulting object 3D feature maps over background scene feature maps. We show that classifiers for object categories, color, materials, and spatial relationships trained over the disentangled 3D feature sub-spaces generalize better with dramatically fewer examples than the current state-of-the-art, and enable a visual question answering system that uses them as its modules to generalize one-shot to novel objects in the scene.
3D Object Recognition By Corresponding and Quantizing Neural 3D Scene Representations
Oct 30, 2020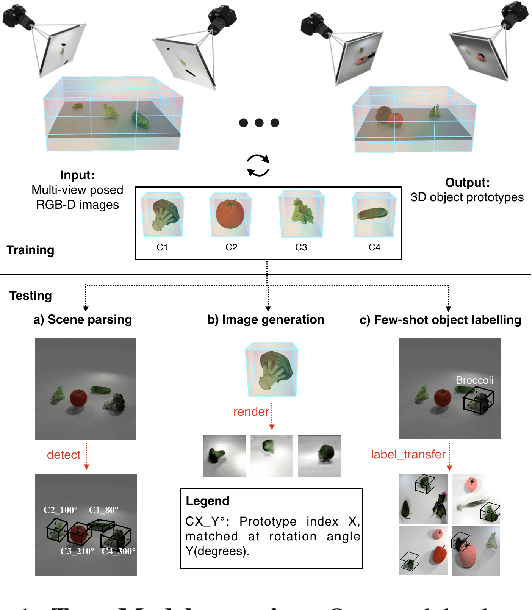
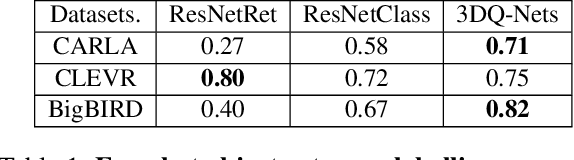
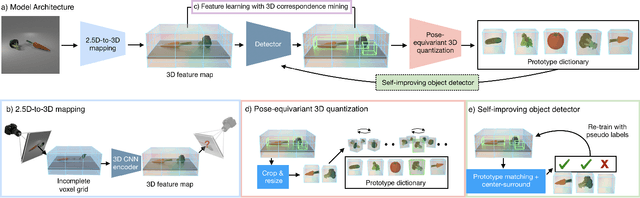
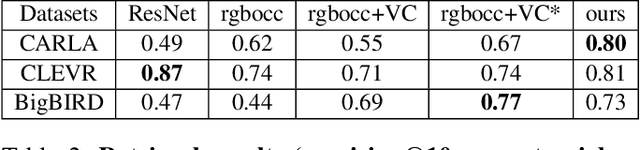
We propose a system that learns to detect objects and infer their 3D poses in RGB-D images. Many existing systems can identify objects and infer 3D poses, but they heavily rely on human labels and 3D annotations. The challenge here is to achieve this without relying on strong supervision signals. To address this challenge, we propose a model that maps RGB-D images to a set of 3D visual feature maps in a differentiable fully-convolutional manner, supervised by predicting views. The 3D feature maps correspond to a featurization of the 3D world scene depicted in the images. The object 3D feature representations are invariant to camera viewpoint changes or zooms, which means feature matching can identify similar objects under different camera viewpoints. We can compare the 3D feature maps of two objects by searching alignment across scales and 3D rotations, and, as a result of the operation, we can estimate pose and scale changes without the need for 3D pose annotations. We cluster object feature maps into a set of 3D prototypes that represent familiar objects in canonical scales and orientations. We then parse images by inferring the prototype identity and 3D pose for each detected object. We compare our method to numerous baselines that do not learn 3D feature visual representations or do not attempt to correspond features across scenes, and outperform them by a large margin in the tasks of object retrieval and object pose estimation. Thanks to the 3D nature of the object-centric feature maps, the visual similarity cues are invariant to 3D pose changes or small scale changes, which gives our method an advantage over 2D and 1D methods.