 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIRS-Bench: a Suite of Tasks for Frontier AI Research Science Agents
Feb 09, 2026LLM agents hold significant promise for advancing scientific research. To accelerate this progress, we introduce AIRS-Bench (the AI Research Science Benchmark), a suite of 20 tasks sourced from state-of-the-art machine learning papers. These tasks span diverse domains, including language modeling, mathematics, bioinformatics, and time series forecasting. AIRS-Bench tasks assess agentic capabilities over the full research lifecycle -- including idea generation, experiment analysis and iterative refinement -- without providing baseline code. The AIRS-Bench task format is versatile, enabling easy integration of new tasks and rigorous comparison across different agentic frameworks. We establish baselines using frontier models paired with both sequential and parallel scaffolds. Our results show that agents exceed human SOTA in four tasks but fail to match it in sixteen others. Even when agents surpass human benchmarks, they do not reach the theoretical performance ceiling for the underlying tasks. These findings indicate that AIRS-Bench is far from saturated and offers substantial room for improvement. We open-source the AIRS-Bench task definitions and evaluation code to catalyze further development in autonomous scientific research.
A Scalable Measure of Loss Landscape Curvature for Analyzing the Training Dynamics of LLMs
Jan 23, 2026Understanding the curvature evolution of the loss landscape is fundamental to analyzing the training dynamics of neural networks. The most commonly studied measure, Hessian sharpness ($λ_{\max}^H$) -- the largest eigenvalue of the loss Hessian -- determines local training stability and interacts with the learning rate throughout training. Despite its significance in analyzing training dynamics, direct measurement of Hessian sharpness remains prohibitive for Large Language Models (LLMs) due to high computational cost. We analyze $\textit{critical sharpness}$ ($λ_c$), a computationally efficient measure requiring fewer than $10$ forward passes given the update direction $Δ\mathbfθ$. Critically, this measure captures well-documented Hessian sharpness phenomena, including progressive sharpening and Edge of Stability. Using this measure, we provide the first demonstration of these sharpness phenomena at scale, up to $7$B parameters, spanning both pre-training and mid-training of OLMo-2 models. We further introduce $\textit{relative critical sharpness}$ ($λ_c^{1\to 2}$), which quantifies the curvature of one loss landscape while optimizing another, to analyze the transition from pre-training to fine-tuning and guide data mixing strategies. Critical sharpness provides practitioners with a practical tool for diagnosing curvature dynamics and informing data composition choices at scale. More broadly, our work shows that scalable curvature measures can provide actionable insights for large-scale training.
The Generalization Gap in Offline Reinforcement Learning
Dec 10, 2023



Despite recent progress in offline learning, these methods are still trained and tested on the same environment. In this paper, we compare the generalization abilities of widely used online and offline learning methods such as online reinforcement learning (RL), offline RL, sequence modeling, and behavioral cloning. Our experiments show that offline learning algorithms perform worse on new environments than online learning ones. We also introduce the first benchmark for evaluating generalization in offline learning, collecting datasets of varying sizes and skill-levels from Procgen (2D video games) and WebShop (e-commerce websites). The datasets contain trajectories for a limited number of game levels or natural language instructions and at test time, the agent has to generalize to new levels or instructions. Our experiments reveal that existing offline learning algorithms struggle to match the performance of online RL on both train and test environments. Behavioral cloning is a strong baseline, outperforming state-of-the-art offline RL and sequence modeling approaches when trained on data from multiple environments and tested on new ones. Finally, we find that increasing the diversity of the data, rather than its size, improves performance on new environments for all offline learning algorithms. Our study demonstrates the limited generalization of current offline learning algorithms highlighting the need for more research in this area.
Understanding the Effects of RLHF on LLM Generalisation and Diversity
Oct 10, 2023Large language models (LLMs) fine-tuned with reinforcement learning from human feedback (RLHF) have been used in some of the most widely deployed AI models to date, such as OpenAI's ChatGPT, Anthropic's Claude, or Meta's LLaMA-2. While there has been significant work developing these methods, our understanding of the benefits and downsides of each stage in RLHF is still limited. To fill this gap, we present an extensive analysis of how each stage of the process (i.e. supervised fine-tuning (SFT), reward modelling, and RLHF) affects two key properties: out-of-distribution (OOD) generalisation and output diversity. OOD generalisation is crucial given the wide range of real-world scenarios in which these models are being used, while output diversity refers to the model's ability to generate varied outputs and is important for a variety of use cases. We perform our analysis across two base models on both summarisation and instruction following tasks, the latter being highly relevant for current LLM use cases. We find that RLHF generalises better than SFT to new inputs, particularly as the distribution shift between train and test becomes larger. However, RLHF significantly reduces output diversity compared to SFT across a variety of measures, implying a tradeoff in current LLM fine-tuning methods between generalisation and diversity. Our results provide guidance on which fine-tuning method should be used depending on the application, and show that more research is needed to improve the trade-off between generalisation and diversity.
Stabilizing Unsupervised Environment Design with a Learned Adversary
Aug 22, 2023



A key challenge in training generally-capable agents is the design of training tasks that facilitate broad generalization and robustness to environment variations. This challenge motivates the problem setting of Unsupervised Environment Design (UED), whereby a student agent trains on an adaptive distribution of tasks proposed by a teacher agent. A pioneering approach for UED is PAIRED, which uses reinforcement learning (RL) to train a teacher policy to design tasks from scratch, making it possible to directly generate tasks that are adapted to the agent's current capabilities. Despite its strong theoretical backing, PAIRED suffers from a variety of challenges that hinder its practical performance. Thus, state-of-the-art methods currently rely on curation and mutation rather than generation of new tasks. In this work, we investigate several key shortcomings of PAIRED and propose solutions for each shortcoming. As a result, we make it possible for PAIRED to match or exceed state-of-the-art methods, producing robust agents in several established challenging procedurally-generated environments, including a partially-observed maze navigation task and a continuous-control car racing environment. We believe this work motivates a renewed emphasis on UED methods based on learned models that directly generate challenging environments, potentially unlocking more open-ended RL training and, as a result, more general agents.
Looking Outside the Box to Ground Language in 3D Scenes
Dec 19, 2021
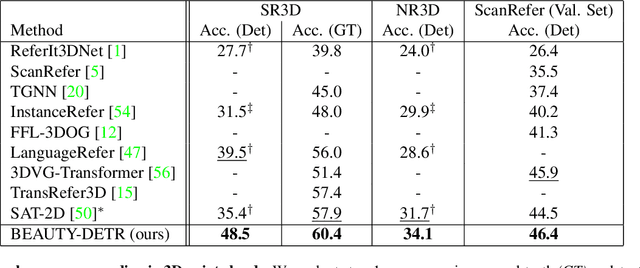
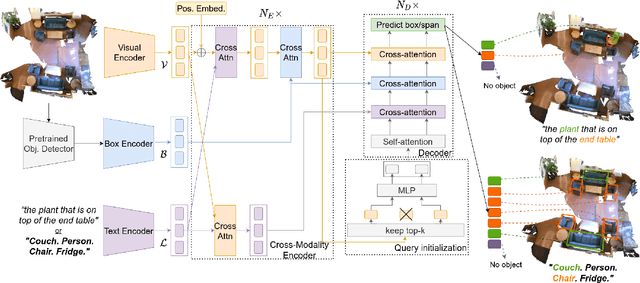

Existing language grounding models often use object proposal bottlenecks: a pre-trained detector proposes objects in the scene and the model learns to select the answer from these box proposals, without attending to the original image or 3D point cloud. Object detectors are typically trained on a fixed vocabulary of objects and attributes that is often too restrictive for open-domain language grounding, where an utterance may refer to visual entities at various levels of abstraction, such as a chair, the leg of a chair, or the tip of the front leg of a chair. We propose a model for grounding language in 3D scenes that bypasses box proposal bottlenecks with three main innovations: i) Iterative attention across the language stream, the point cloud feature stream and 3D box proposals. ii) Transformer decoders with non-parametric entity queries that decode 3D boxes for object and part referentials. iii) Joint supervision from 3D object annotations and language grounding annotations, by treating object detection as grounding of referential utterances comprised of a list of candidate category labels. These innovations result in significant quantitative gains (up to +9% absolute improvement on the SR3D benchmark) over previous approaches on popular 3D language grounding benchmarks. We ablate each of our innovations to show its contribution to the performance of the model. When applied on language grounding on 2D images with minor changes, it performs on par with the state-of-the-art while converges in half of the GPU time. The code and checkpoints will be made available at https://github.com/nickgkan/beauty_detr
CoCoNets: Continuous Contrastive 3D Scene Representations
Apr 08, 2021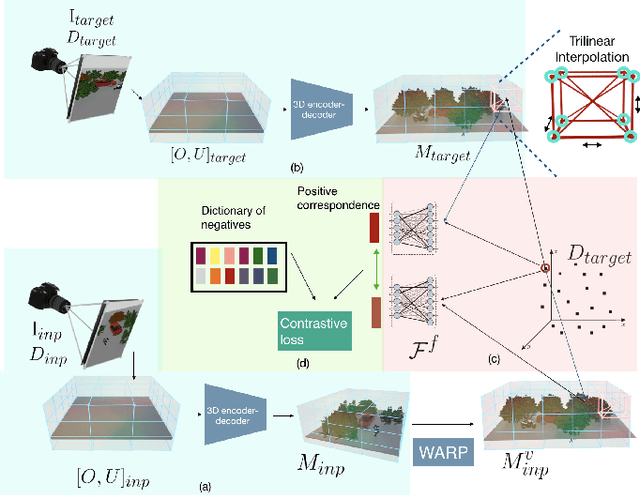
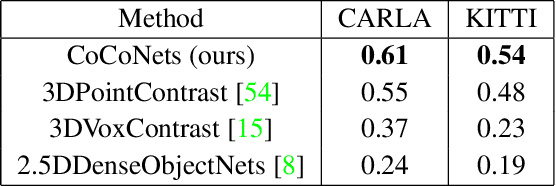
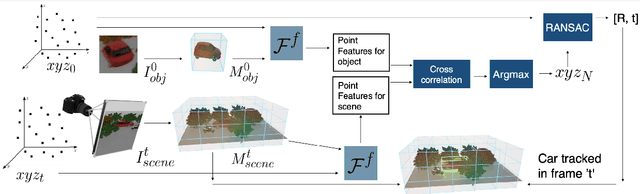

This paper explores self-supervised learning of amodal 3D feature representations from RGB and RGB-D posed images and videos, agnostic to object and scene semantic content, and evaluates the resulting scene representations in the downstream tasks of visual correspondence, object tracking, and object detection. The model infers a latent3D representation of the scene in the form of 3D feature points, where each continuous world 3D point is mapped to its corresponding feature vector. The model is trained for contrastive view prediction by rendering 3D feature clouds in queried viewpoints and matching against the 3D feature point cloud predicted from the query view. Notably, the representation can be queried for any 3D location, even if it is not visible from the input view. Our model brings together three powerful ideas of recent exciting research work: 3D feature grids as a neural bottleneck for view prediction, implicit functions for handling resolution limitations of 3D grids, and contrastive learning for unsupervised training of feature representations. We show the resulting 3D visual feature representations effectively scale across objects and scenes, imagine information occluded or missing from the input viewpoints, track objects over time, align semantically related objects in 3D, and improve 3D object detection. We outperform many existing state-of-the-art methods for 3D feature learning and view prediction, which are either limited by 3D grid spatial resolution, do not attempt to build amodal 3D representations, or do not handle combinatorial scene variability due to their non-convolutional bottlenecks.