 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Diffuser Actor: Policy Diffusion with 3D Scene Representations
Feb 16, 2024We marry diffusion policies and 3D scene representations for robot manipulation. Diffusion policies learn the action distribution conditioned on the robot and environment state using conditional diffusion models. They have recently shown to outperform both deterministic and alternative state-conditioned action distribution learning methods. 3D robot policies use 3D scene feature representations aggregated from a single or multiple camera views using sensed depth. They have shown to generalize better than their 2D counterparts across camera viewpoints. We unify these two lines of work and present 3D Diffuser Actor, a neural policy architecture that, given a language instruction, builds a 3D representation of the visual scene and conditions on it to iteratively denoise 3D rotations and translations for the robot's end-effector. At each denoising iteration, our model represents end-effector pose estimates as 3D scene tokens and predicts the 3D translation and rotation error for each of them, by featurizing them using 3D relative attention to other 3D visual and language tokens. 3D Diffuser Actor sets a new state-of-the-art on RLBench with an absolute performance gain of 16.3% over the current SOTA on a multi-view setup and an absolute gain of 13.1% on a single-view setup. On the CALVIN benchmark, it outperforms the current SOTA in the setting of zero-shot unseen scene generalization by being able to successfully run 0.2 more tasks, a 7% relative increase. It also works in the real world from a handful of demonstrations. We ablate our model's architectural design choices, such as 3D scene featurization and 3D relative attentions, and show they all help generalization. Our results suggest that 3D scene representations and powerful generative modeling are keys to efficient robot learning from demonstrations.
Diffusion-ES: Gradient-free Planning with Diffusion for Autonomous Driving and Zero-Shot Instruction Following
Feb 09, 2024



Diffusion models excel at modeling complex and multimodal trajectory distributions for decision-making and control. Reward-gradient guided denoising has been recently proposed to generate trajectories that maximize both a differentiable reward function and the likelihood under the data distribution captured by a diffusion model. Reward-gradient guided denoising requires a differentiable reward function fitted to both clean and noised samples, limiting its applicability as a general trajectory optimizer. In this paper, we propose DiffusionES, a method that combines gradient-free optimization with trajectory denoising to optimize black-box non-differentiable objectives while staying in the data manifold. Diffusion-ES samples trajectories during evolutionary search from a diffusion model and scores them using a black-box reward function. It mutates high-scoring trajectories using a truncated diffusion process that applies a small number of noising and denoising steps, allowing for much more efficient exploration of the solution space. We show that DiffusionES achieves state-of-the-art performance on nuPlan, an established closed-loop planning benchmark for autonomous driving. Diffusion-ES outperforms existing sampling-based planners, reactive deterministic or diffusion-based policies, and reward-gradient guidance. Additionally, we show that unlike prior guidance methods, our method can optimize non-differentiable language-shaped reward functions generated by few-shot LLM prompting. When guided by a human teacher that issues instructions to follow, our method can generate novel, highly complex behaviors, such as aggressive lane weaving, which are not present in the training data. This allows us to solve the hardest nuPlan scenarios which are beyond the capabilities of existing trajectory optimization methods and driving policies.
ODIN: A Single Model for 2D and 3D Perception
Jan 04, 2024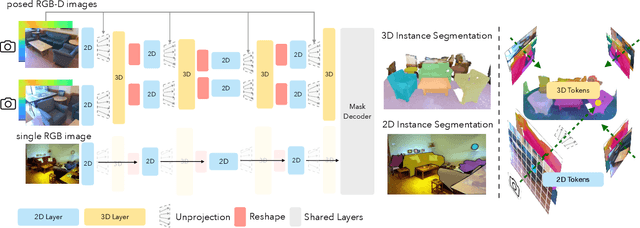
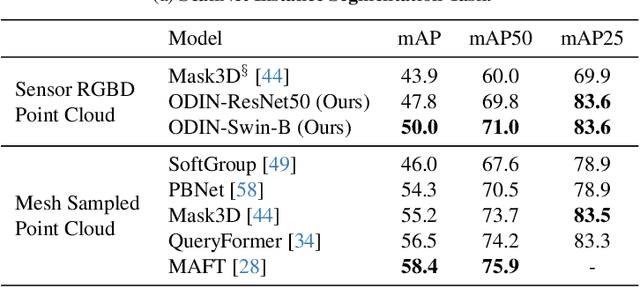
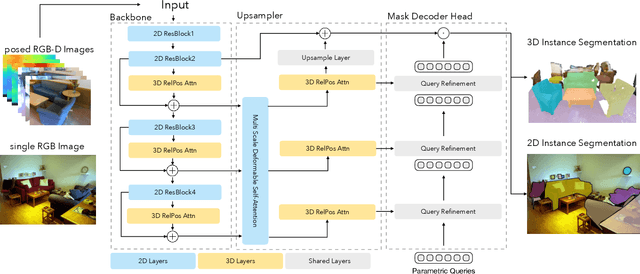
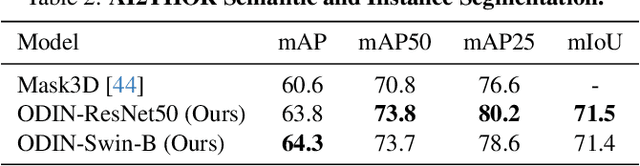
State-of-the-art models on contemporary 3D perception benchmarks like ScanNet consume and label dataset-provided 3D point clouds, obtained through post processing of sensed multiview RGB-D images. They are typically trained in-domain, forego large-scale 2D pre-training and outperform alternatives that featurize the posed RGB-D multiview images instead. The gap in performance between methods that consume posed images versus post-processed 3D point clouds has fueled the belief that 2D and 3D perception require distinct model architectures. In this paper, we challenge this view and propose ODIN (Omni-Dimensional INstance segmentation), a model that can segment and label both 2D RGB images and 3D point clouds, using a transformer architecture that alternates between 2D within-view and 3D cross-view information fusion. Our model differentiates 2D and 3D feature operations through the positional encodings of the tokens involved, which capture pixel coordinates for 2D patch tokens and 3D coordinates for 3D feature tokens. ODIN achieves state-of-the-art performance on ScanNet200, Matterport3D and AI2THOR 3D instance segmentation benchmarks, and competitive performance on ScanNet, S3DIS and COCO. It outperforms all previous works by a wide margin when the sensed 3D point cloud is used in place of the point cloud sampled from 3D mesh. When used as the 3D perception engine in an instructable embodied agent architecture, it sets a new state-of-the-art on the TEACh action-from-dialogue benchmark. Our code and checkpoints can be found at the project website: https://odin-seg.github.io.
Act3D: Infinite Resolution Action Detection Transformer for Robotic Manipulation
Jun 30, 2023



3D perceptual representations are well suited for robot manipulation as they easily encode occlusions and simplify spatial reasoning. Many manipulation tasks require high spatial precision in end-effector pose prediction, typically demanding high-resolution 3D perceptual grids that are computationally expensive to process. As a result, most manipulation policies operate directly in 2D, foregoing 3D inductive biases. In this paper, we propose Act3D, a manipulation policy Transformer that casts 6-DoF keypose prediction as 3D detection with adaptive spatial computation. It takes as input 3D feature clouds unprojected from one or more camera views, iteratively samples 3D point grids in free space in a coarse-to-fine manner, featurizes them using relative spatial attention to the physical feature cloud, and selects the best feature point for end-effector pose prediction. Act3D sets a new state-of-the-art in RLbench, an established manipulation benchmark. Our model achieves 10% absolute improvement over the previous SOTA 2D multi-view policy on 74 RLbench tasks and 22% absolute improvement with 3x less compute over the previous SOTA 3D policy. In thorough ablations, we show the importance of relative spatial attention, large-scale vision-language pre-trained 2D backbones, and weight tying across coarse-to-fine attentions. Code and videos are available at our project site: https://act3d.github.io/.
Energy-based Models are Zero-Shot Planners for Compositional Scene Rearrangement
May 06, 2023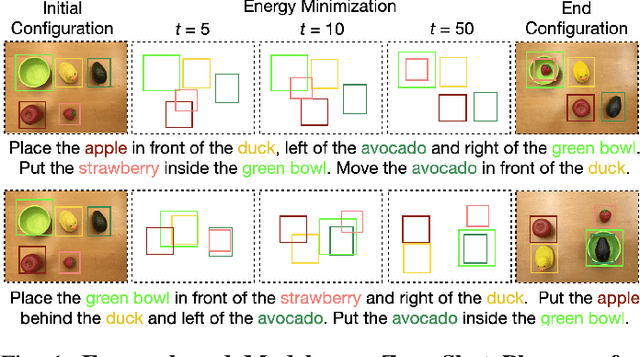
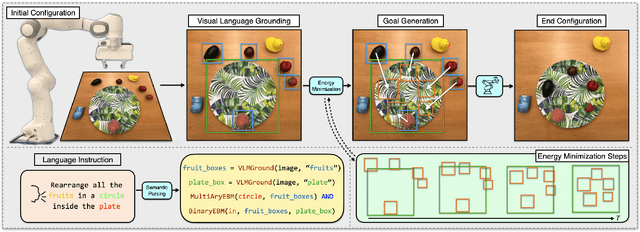


Language is compositional; an instruction can express multiple relation constraints to hold among objects in a scene that a robot is tasked to rearrange. Our focus in this work is an instructable scene-rearranging framework that generalizes to longer instructions and to spatial concept compositions never seen at training time. We propose to represent language-instructed spatial concepts with energy functions over relative object arrangements. A language parser maps instructions to corresponding energy functions and an open-vocabulary visual-language model grounds their arguments to relevant objects in the scene. We generate goal scene configurations by gradient descent on the sum of energy functions, one per language predicate in the instruction. Local vision-based policies then re-locate objects to the inferred goal locations. We test our model on established instruction-guided manipulation benchmarks, as well as benchmarks of compositional instructions we introduce. We show our model can execute highly compositional instructions zero-shot in simulation and in the real world. It outperforms language-to-action reactive policies and Large Language Model planners by a large margin, especially for long instructions that involve compositions of multiple spatial concepts. Simulation and real-world robot execution videos, as well as our code and datasets are publicly available on our website: https://ebmplanner.github.io.
Analogy-Forming Transformers for Few-Shot 3D Parsing
Apr 27, 2023We present Analogical Networks, a model that encodes domain knowledge explicitly, in a collection of structured labelled 3D scenes, in addition to implicitly, as model parameters, and segments 3D object scenes with analogical reasoning: instead of mapping a scene to part segments directly, our model first retrieves related scenes from memory and their corresponding part structures, and then predicts analogous part structures for the input scene, via an end-to-end learnable modulation mechanism. By conditioning on more than one retrieved memories, compositions of structures are predicted, that mix and match parts across the retrieved memories. One-shot, few-shot or many-shot learning are treated uniformly in Analogical Networks, by conditioning on the appropriate set of memories, whether taken from a single, few or many memory exemplars, and inferring analogous parses. We show Analogical Networks are competitive with state-of-the-art 3D segmentation transformers in many-shot settings, and outperform them, as well as existing paradigms of meta-learning and few-shot learning, in few-shot settings. Analogical Networks successfully segment instances of novel object categories simply by expanding their memory, without any weight updates. Our code and models are publicly available in the project webpage: http://analogicalnets.github.io/.
Looking Outside the Box to Ground Language in 3D Scenes
Dec 19, 2021
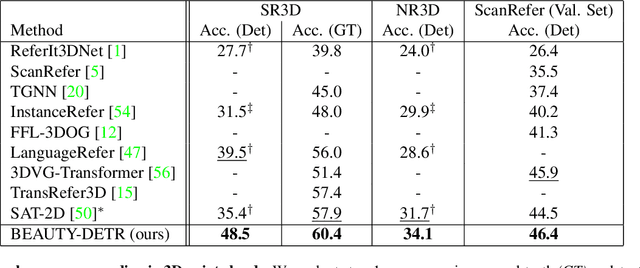
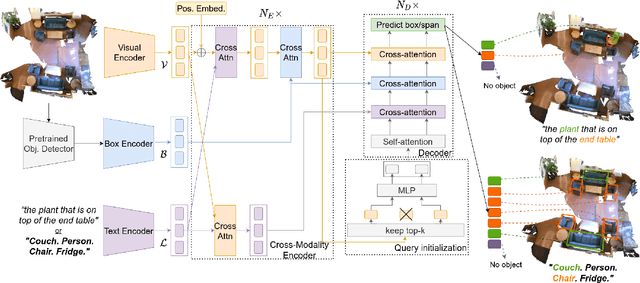

Existing language grounding models often use object proposal bottlenecks: a pre-trained detector proposes objects in the scene and the model learns to select the answer from these box proposals, without attending to the original image or 3D point cloud. Object detectors are typically trained on a fixed vocabulary of objects and attributes that is often too restrictive for open-domain language grounding, where an utterance may refer to visual entities at various levels of abstraction, such as a chair, the leg of a chair, or the tip of the front leg of a chair. We propose a model for grounding language in 3D scenes that bypasses box proposal bottlenecks with three main innovations: i) Iterative attention across the language stream, the point cloud feature stream and 3D box proposals. ii) Transformer decoders with non-parametric entity queries that decode 3D boxes for object and part referentials. iii) Joint supervision from 3D object annotations and language grounding annotations, by treating object detection as grounding of referential utterances comprised of a list of candidate category labels. These innovations result in significant quantitative gains (up to +9% absolute improvement on the SR3D benchmark) over previous approaches on popular 3D language grounding benchmarks. We ablate each of our innovations to show its contribution to the performance of the model. When applied on language grounding on 2D images with minor changes, it performs on par with the state-of-the-art while converges in half of the GPU time. The code and checkpoints will be made available at https://github.com/nickgkan/beauty_detr
Orientation Attentive Robot Grasp Synthesis
Jun 09, 2020



Physical neighborhoods of grasping points in common objects may offer a wide variety of plausible grasping configurations. For a fixed center of a simple spherical object, for example, there is an infinite number of valid grasping orientations. Such structures create ambiguous and discontinuous grasp maps that confuse neural regressors. We perform a thorough investigation of the challenging Jacquard dataset to show that the existing pixel-wise learning approaches are prone to box overlaps of drastically different orientations. We then introduce a novel augmented map representation that partitions the angle space into bins to allow for the co-occurrence of such orientations and observe larger accuracy margins on the ground truth grasp map reconstructions. On top of that, we build the ORientation AtteNtive Grasp synthEsis (ORANGE) framework that jointly solves a bin classification problem and a real-value regression. The grasp synthesis is attentively supervised by combining discrete and continuous estimations into a single map. We provide experimental evidence by appending ORANGE to two existing unimodal architectures and boost their performance to state-of-the-art levels on Jacquard, specifically 94.71\%, over all related works, even multimodal. Code is available at \url{https://github.com/nickgkan/orange}.
Deeply Supervised Multimodal Attentional Translation Embeddings for Visual Relationship Detection
Feb 15, 2019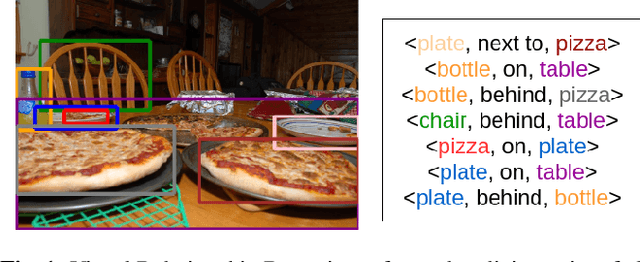
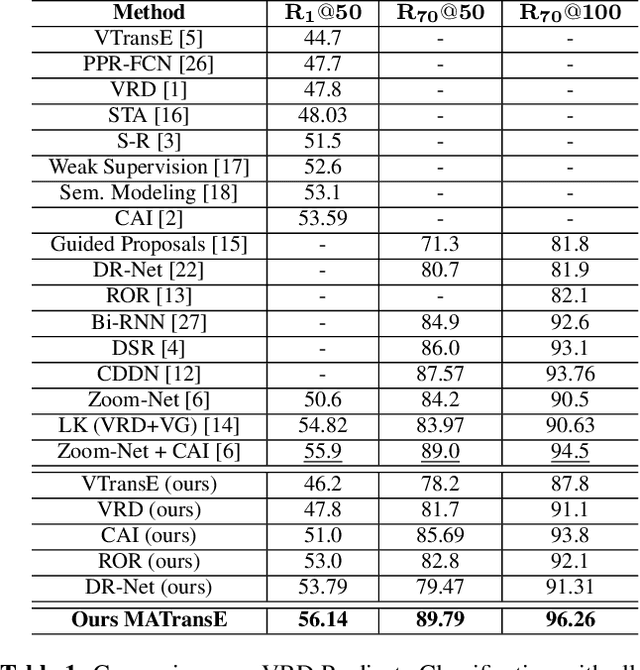
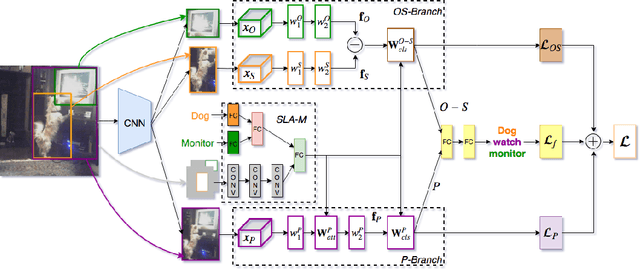
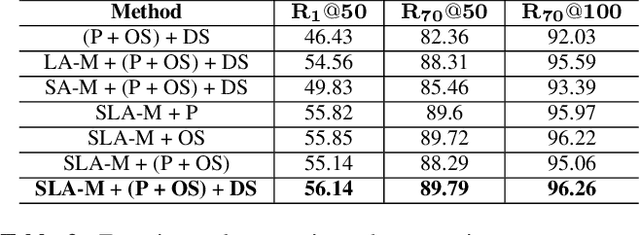
Detecting visual relationships, i.e. <Subject, Predicate, Object> triplets, is a challenging Scene Understanding task approached in the past via linguistic priors or spatial information in a single feature branch. We introduce a new deeply supervised two-branch architecture, the Multimodal Attentional Translation Embeddings, where the visual features of each branch are driven by a multimodal attentional mechanism that exploits spatio-linguistic similarities in a low-dimensional space. We present a variety of experiments comparing against all related approaches in the literature, as well as by re-implementing and fine-tuning several of them. Results on the commonly employed VRD dataset [1] show that the proposed method clearly outperforms all others, while we also justify our claims both quantitatively and qualitatively.