 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeshPose: Unifying DensePose and 3D Body Mesh reconstruction
Jun 14, 2024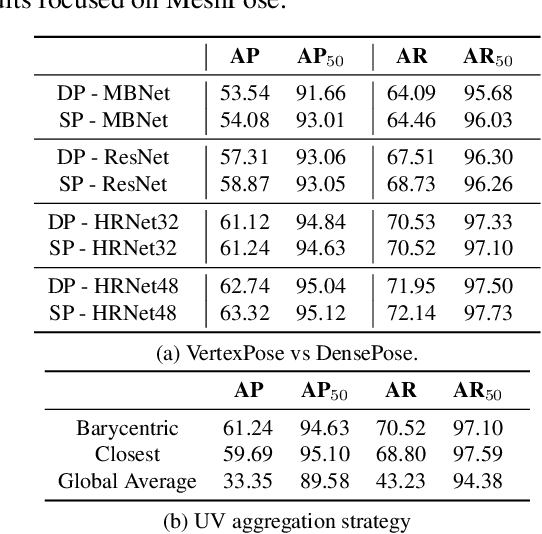
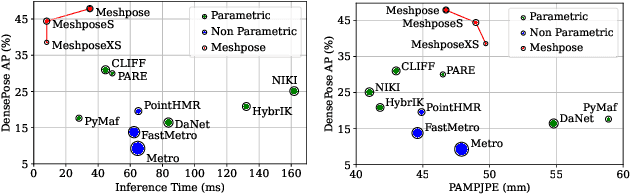

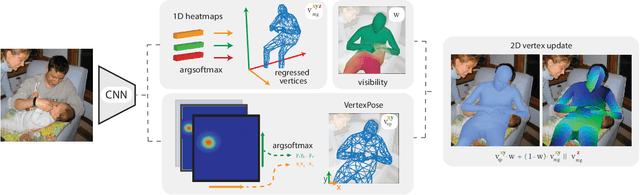
DensePose provides a pixel-accurate association of images with 3D mesh coordinates, but does not provide a 3D mesh, while Human Mesh Reconstruction (HMR) systems have high 2D reprojection error, as measured by DensePose localization metrics. In this work we introduce MeshPose to jointly tackle DensePose and HMR. For this we first introduce new losses that allow us to use weak DensePose supervision to accurately localize in 2D a subset of the mesh vertices ('VertexPose'). We then lift these vertices to 3D, yielding a low-poly body mesh ('MeshPose'). Our system is trained in an end-to-end manner and is the first HMR method to attain competitive DensePose accuracy, while also being lightweight and amenable to efficient inference, making it suitable for real-time AR applications.
* IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
ViDaS Video Depth-aware Saliency Network
May 19, 2023
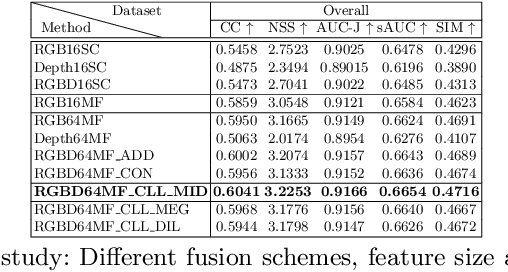
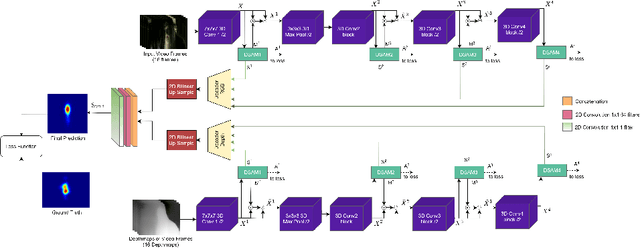

We introduce ViDaS, a two-stream, fully convolutional Video, Depth-Aware Saliency network to address the problem of attention modeling ``in-the-wild", via saliency prediction in videos. Contrary to existing visual saliency approaches using only RGB frames as input, our network employs also depth as an additional modality. The network consists of two visual streams, one for the RGB frames, and one for the depth frames. Both streams follow an encoder-decoder approach and are fused to obtain a final saliency map. The network is trained end-to-end and is evaluated in a variety of different databases with eye-tracking data, containing a wide range of video content. Although the publicly available datasets do not contain depth, we estimate it using three different state-of-the-art methods, to enable comparisons and a deeper insight. Our method outperforms in most cases state-of-the-art models and our RGB-only variant, which indicates that depth can be beneficial to accurately estimating saliency in videos displayed on a 2D screen. Depth has been widely used to assist salient object detection problems, where it has been proven to be very beneficial. Our problem though differs significantly from salient object detection, since it is not restricted to specific salient objects, but predicts human attention in a more general aspect. These two problems not only have different objectives, but also different ground truth data and evaluation metrics. To our best knowledge, this is the first competitive deep learning video saliency estimation approach that combines both RGB and Depth features to address the general problem of saliency estimation ``in-the-wild". The code will be publicly released.
ChildBot: Multi-Robot Perception and Interaction with Children
Aug 28, 2020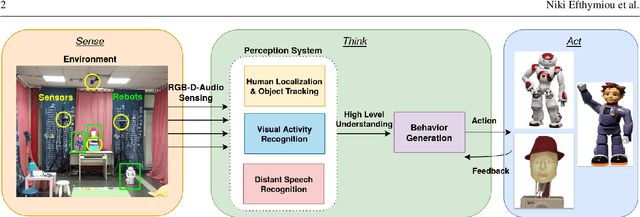

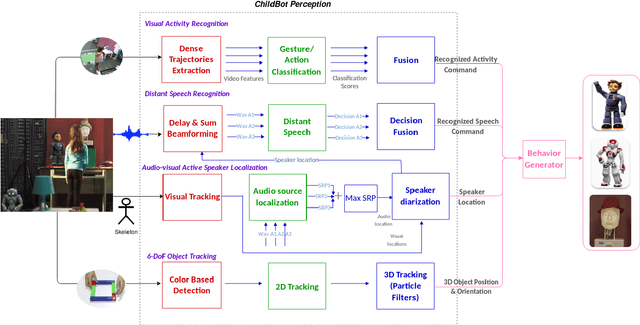
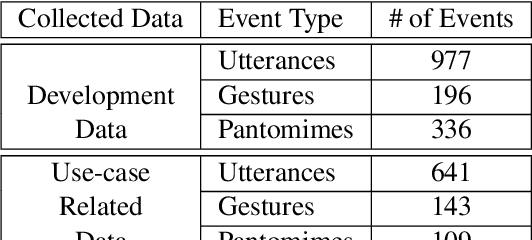
In this paper we present an integrated robotic system capable of participating in and performing a wide range of educational and entertainment tasks, in collaboration with one or more children. The system, called ChildBot, features multimodal perception modules and multiple robotic agents that monitor the interaction environment, and can robustly coordinate complex Child-Robot Interaction use-cases. In order to validate the effectiveness of the system and its integrated modules, we have conducted multiple experiments with a total of 52 children. Our results show improved perception capabilities in comparison to our earlier works that ChildBot was based on. In addition, we have conducted a preliminary user experience study, employing some educational/entertainment tasks, that yields encouraging results regarding the technical validity of our system and initial insights on the user experience with it.
How to track your dragon: A Multi-Attentional Framework for real-time RGB-D 6-DOF Object Pose Tracking
Apr 21, 2020


We present a novel multi-attentional convolutional architecture to tackle the problem of real-time RGB-D 6D object pose tracking of single, known objects. Such a problem poses multiple challenges originating both from the objects' nature and their interaction with their environment, which previous approaches have failed to fully address. The proposed framework encapsulates methods for background clutter and occlusion handling by integrating multiple parallel soft spatial attention modules into a multitask Convolutional Neural Network (CNN) architecture. Moreover, we consider the special geometrical properties of both the object's 3D model and the pose space, and we use a more sophisticated approach for data augmentation for training. The provided experimental results confirm the effectiveness of the proposed multi-attentional architecture, as it improves the State-of-the-Art (SoA) tracking performance by an average score of 40.5% for translation and 57.5% for rotation, when testing on the dataset presented in [1], the most complete dataset designed, up to date, for the problem of RGB-D object tracking.
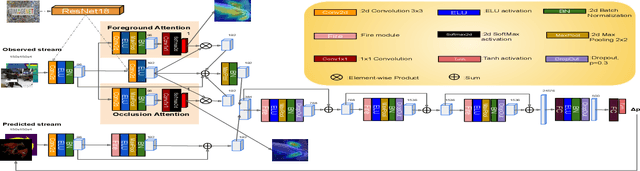
STAViS: Spatio-Temporal AudioVisual Saliency Network
Jan 09, 2020


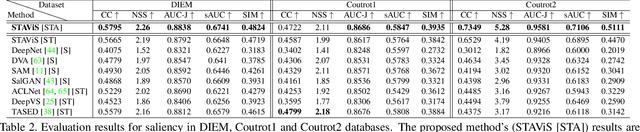
We introduce STAViS, a spatio-temporal audiovisual saliency network that combines spatio-temporal visual and auditory information in order to efficiently address the problem of saliency estimation in videos. Our approach employs a single network that combines visual saliency and auditory features and learns to appropriately localize sound sources and to fuse the two saliencies in order to obtain a final saliency map. The network has been designed, trained end-to-end, and evaluated on six different databases that contain audiovisual eye-tracking data of a large variety of videos. We compare our method against 8 different state-of-the-art visual saliency models. Evaluation results across databases indicate that our STAViS model outperforms our visual only variant as well as the other state-of-the-art models in the majority of cases. Also, the consistently good performance it achieves for all databases indicates that it is appropriate for estimating saliency "in-the-wild".
LSTM-based Network for Human Gait Stability Prediction in an Intelligent Robotic Rollator
Mar 05, 2019
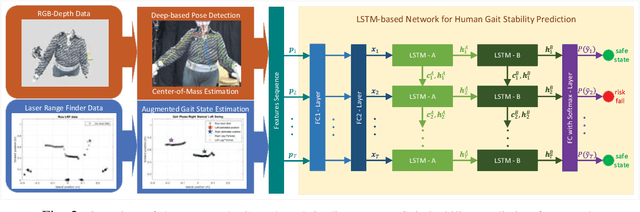
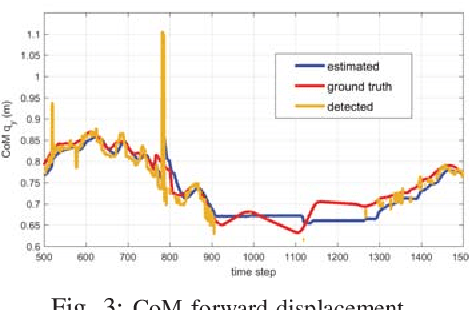

In this work, we present a novel framework for on-line human gait stability prediction of the elderly users of an intelligent robotic rollator using Long Short Term Memory (LSTM) networks, fusing multimodal RGB-D and Laser Range Finder (LRF) data from non-wearable sensors. A Deep Learning (DL) based approach is used for the upper body pose estimation. The detected pose is used for estimating the body Center of Mass (CoM) using Unscented Kalman Filter (UKF). An Augmented Gait State Estimation framework exploits the LRF data to estimate the legs' positions and the respective gait phase. These estimates are the inputs of an encoder-decoder sequence to sequence model which predicts the gait stability state as Safe or Fall Risk walking. It is validated with data from real patients, by exploring different network architectures, hyperparameter settings and by comparing the proposed method with other baselines. The presented LSTM-based human gait stability predictor is shown to provide robust predictions of the human stability state, and thus has the potential to be integrated into a general user-adaptive control architecture as a fall-risk alarm.
Deeply Supervised Multimodal Attentional Translation Embeddings for Visual Relationship Detection
Feb 15, 2019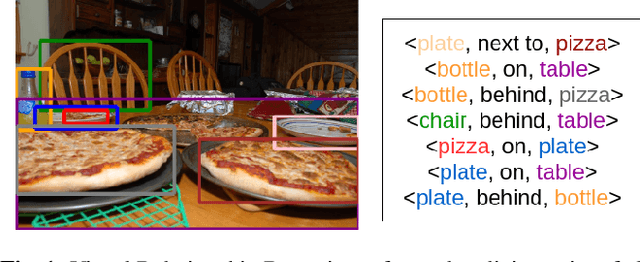
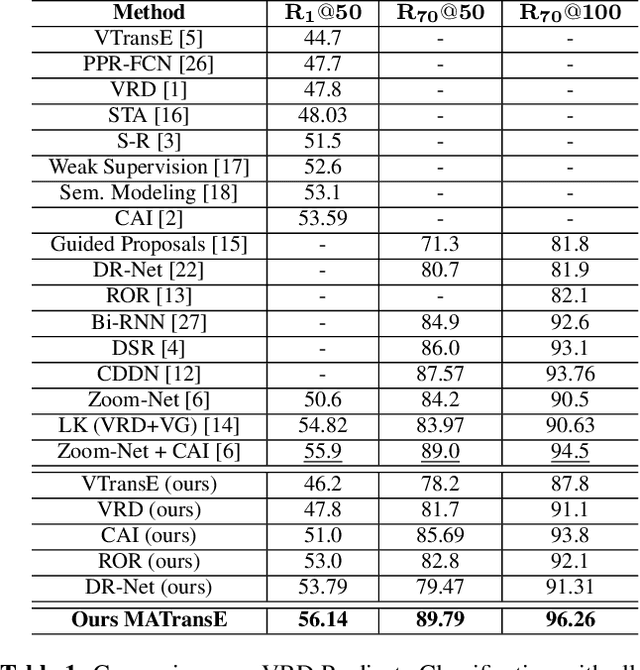
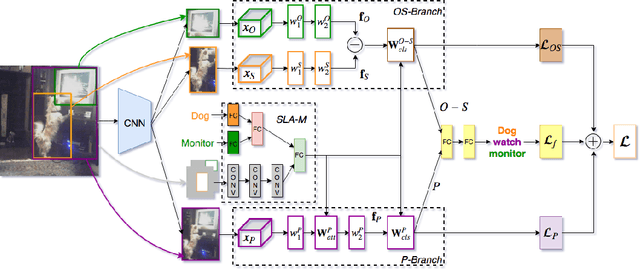
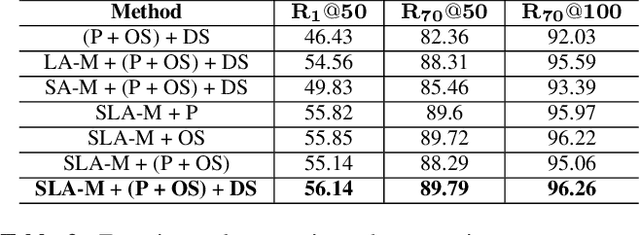
Detecting visual relationships, i.e. <Subject, Predicate, Object> triplets, is a challenging Scene Understanding task approached in the past via linguistic priors or spatial information in a single feature branch. We introduce a new deeply supervised two-branch architecture, the Multimodal Attentional Translation Embeddings, where the visual features of each branch are driven by a multimodal attentional mechanism that exploits spatio-linguistic similarities in a low-dimensional space. We present a variety of experiments comparing against all related approaches in the literature, as well as by re-implementing and fine-tuning several of them. Results on the commonly employed VRD dataset [1] show that the proposed method clearly outperforms all others, while we also justify our claims both quantitatively and qualitatively.
Fusing Body Posture with Facial Expressions for Joint Recognition of Affect in Child-Robot Interaction
Jan 07, 2019
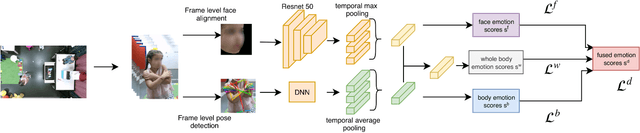

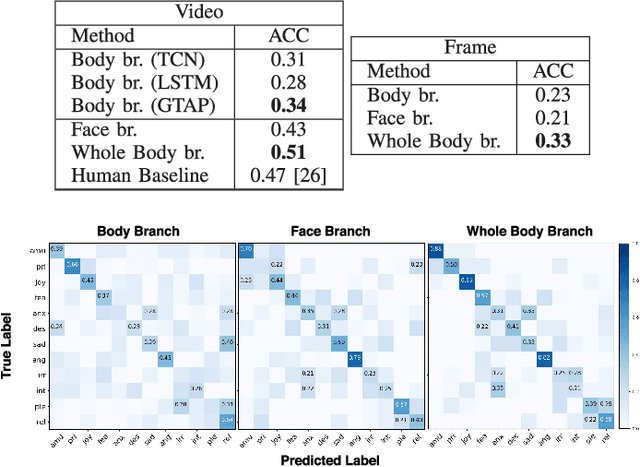
In this paper we address the problem of multi-cue affect recognition in challenging environments such as child-robot interaction. Towards this goal we propose a method for automatic recognition of affect that leverages body expressions alongside facial expressions, as opposed to traditional methods that usually focus only on the latter. We evaluate our methods on a challenging child-robot interaction database of emotional expressions, as well as on a database of emotional expressions by actors, and show that the proposed method achieves significantly better results when compared with the facial expression baselines, can be trained both jointly and separately, and offers us computational models for both the individual modalities, as well as for the whole body emotion.
SUSiNet: See, Understand and Summarize it
Dec 03, 2018


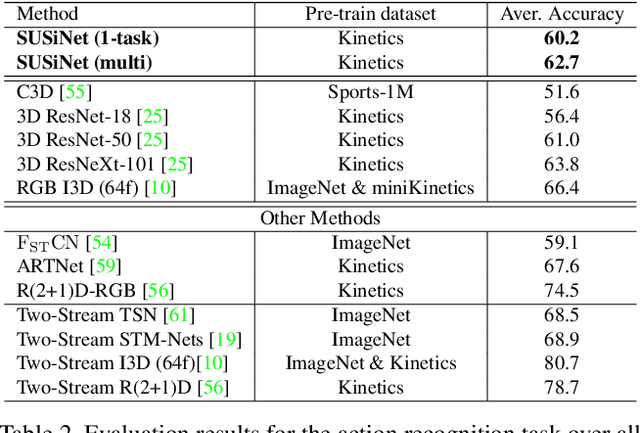
In this work we propose a multi-task spatio-temporal network, called SUSiNet, that can jointly tackle the spatio-temporal problems of saliency estimation, action recognition and video summarization. Our approach employs a single network that is jointly end-to-end trained for all tasks with multiple and diverse datasets related to the exploring tasks. The proposed network uses a unified architecture that includes global and task specific layer and produces multiple output types, i.e., saliency maps or classification labels, by employing the same video input. Moreover, one additional contribution is that the proposed network can be deeply supervised through an attention module that is related to human attention as it is expressed by eye-tracking data. From the extensive evaluation, on seven different datasets, we have observed that the multi-task network performs as well as the state-of-the-art single-task methods (or in some cases better), while it requires less computational budget than having one independent network per each task.
A Deep Learning Approach for Multi-View Engagement Estimation of Children in a Child-Robot Joint Attention task
Dec 01, 2018


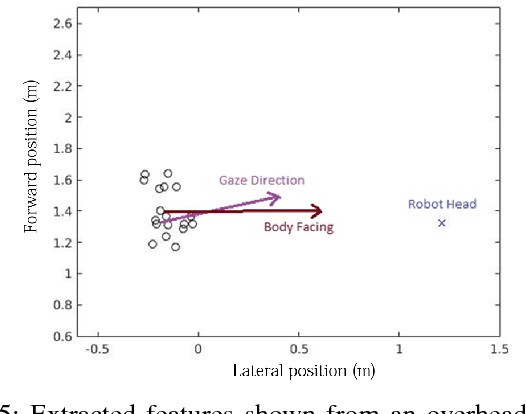
In this work we tackle the problem of child engagement estimation while children freely interact with a robot in their room. We propose a deep-based multi-view solution that takes advantage of recent developments in human pose detection. We extract the child's pose from different RGB-D cameras placed elegantly in the room, fuse the results and feed them to a deep neural network trained for classifying engagement levels. The deep network contains a recurrent layer, in order to exploit the rich temporal information contained in the pose data. The resulting method outperforms a number of baseline classifiers, and provides a promising tool for better automatic understanding of a child's attitude, interest and attention while cooperating with a robot. The goal is to integrate this model in next generation social robots as an attention monitoring tool during various CRI tasks both for Typically Developed (TD) children and children affected by autism (ASD).