 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUSiNet: See, Understand and Summarize it
Paper and Code
Dec 03, 2018


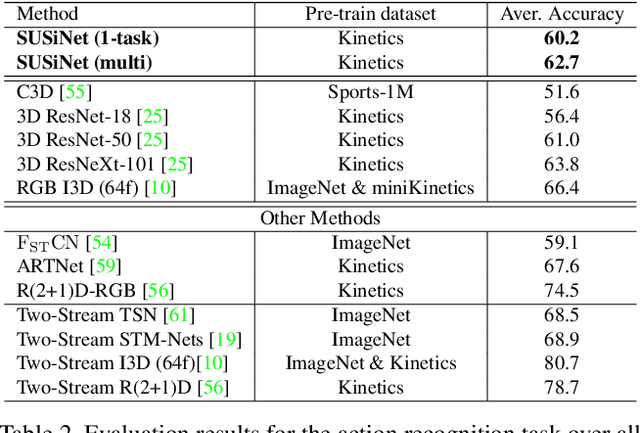
In this work we propose a multi-task spatio-temporal network, called SUSiNet, that can jointly tackle the spatio-temporal problems of saliency estimation, action recognition and video summarization. Our approach employs a single network that is jointly end-to-end trained for all tasks with multiple and diverse datasets related to the exploring tasks. The proposed network uses a unified architecture that includes global and task specific layer and produces multiple output types, i.e., saliency maps or classification labels, by employing the same video input. Moreover, one additional contribution is that the proposed network can be deeply supervised through an attention module that is related to human attention as it is expressed by eye-tracking data. From the extensive evaluation, on seven different datasets, we have observed that the multi-task network performs as well as the state-of-the-art single-task methods (or in some cases better), while it requires less computational budget than having one independent network per each task.