 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Shape Gap: A Benchmark and Baseline for Deformation-Aware 6D Pose Estimation of Agricultural Produce
Mar 28, 2026Accurate 6D pose estimation for robotic harvesting is fundamentally hindered by the biological deformability and high intra-class shape variability of agricultural produce. Instance-level methods fail in this setting, as obtaining exact 3D models for every unique piece of produce is practically infeasible, while category-level approaches that rely on a fixed template suffer significant accuracy degradation when the prior deviates from the true instance geometry. To bridge such lack of robustness to deformation, we introduce PEAR (Pose and dEformation of Agricultural pRoduce), the first benchmark providing joint 6D pose and per-instance 3D deformation ground truth across 8 produce categories, acquired via a robotic manipulator for high annotation accuracy. Using PEAR, we show that state-of-the-art methods suffer up to 6x performance degradation when faced with the inherent geometric deviations of real-world produce. Motivated by this finding, we propose SEED (Simultaneous Estimation of posE and Deformation), a unified RGB-only framework that jointly predicts 6D pose and explicit lattice deformations from a single image across multiple produce categories. Trained entirely on synthetic data with generative texture augmentation applied at the UV level, SEED outperforms MegaPose on 6 out of 8 categories under identical RGB-only conditions, demonstrating that explicit shape modeling is a critical step toward reliable pose estimation in agricultural robotics.
Baby Sophia: A Developmental Approach to Self-Exploration through Self-Touch and Hand Regard
Nov 12, 2025Inspired by infant development, we propose a Reinforcement Learning (RL) framework for autonomous self-exploration in a robotic agent, Baby Sophia, using the BabyBench simulation environment. The agent learns self-touch and hand regard behaviors through intrinsic rewards that mimic an infant's curiosity-driven exploration of its own body. For self-touch, high-dimensional tactile inputs are transformed into compact, meaningful representations, enabling efficient learning. The agent then discovers new tactile contacts through intrinsic rewards and curriculum learning that encourage broad body coverage, balance, and generalization. For hand regard, visual features of the hands, such as skin-color and shape, are learned through motor babbling. Then, intrinsic rewards encourage the agent to perform novel hand motions, and follow its hands with its gaze. A curriculum learning setup from single-hand to dual-hand training allows the agent to reach complex visual-motor coordination. The results of this work demonstrate that purely curiosity-based signals, with no external supervision, can drive coordinated multimodal learning, imitating an infant's progression from random motor babbling to purposeful behaviors.
Diffusion-Based Scenario Tree Generation for Multivariate Time Series Prediction and Multistage Stochastic Optimization
Sep 18, 2025Stochastic forecasting is critical for efficient decision-making in uncertain systems, such as energy markets and finance, where estimating the full distribution of future scenarios is essential. We propose Diffusion Scenario Tree (DST), a general framework for constructing scenario trees for multivariate prediction tasks using diffusion-based probabilistic forecasting models. DST recursively samples future trajectories and organizes them into a tree via clustering, ensuring non-anticipativity (decisions depending only on observed history) at each stage. We evaluate the framework on the optimization task of energy arbitrage in New York State's day-ahead electricity market. Experimental results show that our approach consistently outperforms the same optimization algorithms that use scenario trees from more conventional models and Model-Free Reinforcement Learning baselines. Furthermore, using DST for stochastic optimization yields more efficient decision policies, achieving higher performance by better handling uncertainty than deterministic and stochastic MPC variants using the same diffusion-based forecaster.
Classical Guitar Duet Separation using GuitarDuets -- a Dataset of Real and Synthesized Guitar Recordings
Jul 01, 2025Recent advancements in music source separation (MSS) have focused in the multi-timbral case, with existing architectures tailored for the separation of distinct instruments, overlooking thus the challenge of separating instruments with similar timbral characteristics. Addressing this gap, our work focuses on monotimbral MSS, specifically within the context of classical guitar duets. To this end, we introduce the GuitarDuets dataset, featuring a combined total of approximately three hours of real and synthesized classical guitar duet recordings, as well as note-level annotations of the synthesized duets. We perform an extensive cross-dataset evaluation by adapting Demucs, a state-of-the-art MSS architecture, to monotimbral source separation. Furthermore, we develop a joint permutation-invariant transcription and separation framework, to exploit note event predictions as auxiliary information. Our results indicate that utilizing both the real and synthesized subsets of GuitarDuets leads to improved separation performance in an independently recorded test set compared to utilizing solely one subset. We also find that while the availability of ground-truth note labels greatly helps the performance of the separation network, the predicted note estimates result only in marginal improvement. Finally, we discuss the behavior of commonly utilized metrics, such as SDR and SI-SDR, in the context of monotimbral MSS.
* In Proceedings of the 25th International Society for Music Information Retrieval Conference (ISMIR 2024), San Francisco, USA, November 2024. The dataset is available at: https://zenodo.org/records/12802440
Only-Style: Stylistic Consistency in Image Generation without Content Leakage
Jun 11, 2025Generating images in a consistent reference visual style remains a challenging computer vision task. State-of-the-art methods aiming for style-consistent generation struggle to effectively separate semantic content from stylistic elements, leading to content leakage from the image provided as a reference to the targets. To address this challenge, we propose Only-Style: a method designed to mitigate content leakage in a semantically coherent manner while preserving stylistic consistency. Only-Style works by localizing content leakage during inference, allowing the adaptive tuning of a parameter that controls the style alignment process, specifically within the image patches containing the subject in the reference image. This adaptive process best balances stylistic consistency with leakage elimination. Moreover, the localization of content leakage can function as a standalone component, given a reference-target image pair, allowing the adaptive tuning of any method-specific parameter that provides control over the impact of the stylistic reference. In addition, we propose a novel evaluation framework to quantify the success of style-consistent generations in avoiding undesired content leakage. Our approach demonstrates a significant improvement over state-of-the-art methods through extensive evaluation across diverse instances, consistently achieving robust stylistic consistency without undesired content leakage.
Object-Centric Action-Enhanced Representations for Robot Visuo-Motor Policy Learning
May 27, 2025Learning visual representations from observing actions to benefit robot visuo-motor policy generation is a promising direction that closely resembles human cognitive function and perception. Motivated by this, and further inspired by psychological theories suggesting that humans process scenes in an object-based fashion, we propose an object-centric encoder that performs semantic segmentation and visual representation generation in a coupled manner, unlike other works, which treat these as separate processes. To achieve this, we leverage the Slot Attention mechanism and use the SOLV model, pretrained in large out-of-domain datasets, to bootstrap fine-tuning on human action video data. Through simulated robotic tasks, we demonstrate that visual representations can enhance reinforcement and imitation learning training, highlighting the effectiveness of our integrated approach for semantic segmentation and encoding. Furthermore, we show that exploiting models pretrained on out-of-domain datasets can benefit this process, and that fine-tuning on datasets depicting human actions -- although still out-of-domain -- , can significantly improve performance due to close alignment with robotic tasks. These findings show the capability to reduce reliance on annotated or robot-specific action datasets and the potential to build on existing visual encoders to accelerate training and improve generalizability.
Multi-task Learning For Joint Action and Gesture Recognition
May 23, 2025In practical applications, computer vision tasks often need to be addressed simultaneously. Multitask learning typically achieves this by jointly training a single deep neural network to learn shared representations, providing efficiency and improving generalization. Although action and gesture recognition are closely related tasks, since they focus on body and hand movements, current state-of-the-art methods handle them separately. In this paper, we show that employing a multi-task learning paradigm for action and gesture recognition results in more efficient, robust and generalizable visual representations, by leveraging the synergies between these tasks. Extensive experiments on multiple action and gesture datasets demonstrate that handling actions and gestures in a single architecture can achieve better performance for both tasks in comparison to their single-task learning variants.
Proactive tactile exploration for object-agnostic shape reconstruction from minimal visual priors
May 17, 2025



The perception of an object's surface is important for robotic applications enabling robust object manipulation. The level of accuracy in such a representation affects the outcome of the action planning, especially during tasks that require physical contact, e.g. grasping. In this paper, we propose a novel iterative method for 3D shape reconstruction consisting of two steps. At first, a mesh is fitted on data points acquired from the object's surface, based on a single primitive template. Subsequently, the mesh is properly adjusted to adequately represent local deformities. Moreover, a novel proactive tactile exploration strategy aims at minimizing the total uncertainty with the least number of contacts, while reducing the risk of contact failure in case the estimated surface differs significantly from the real one. The performance of the methodology is evaluated both in 3D simulation and on a real setup.
Training Deep Morphological Neural Networks as Universal Approximators
May 14, 2025We investigate deep morphological neural networks (DMNNs). We demonstrate that despite their inherent non-linearity, activations between layers are essential for DMNNs. We then propose several new architectures for DMNNs, each with a different constraint on their parameters. For the first (resp. second) architecture, we work under the constraint that the majority of parameters (resp. learnable parameters) should be part of morphological operations. We empirically show that our proposed networks can be successfully trained, and are more prunable than linear networks. To the best of our knowledge, we are the first to successfully train DMNNs under such constraints, although the generalization capabilities of our networks remain limited. Finally, we propose a hybrid network architecture combining linear and morphological layers, showing empirically that the inclusion of morphological layers significantly accelerates the convergence of gradient descent with large batches.
Sparse Hybrid Linear-Morphological Networks
Apr 12, 2025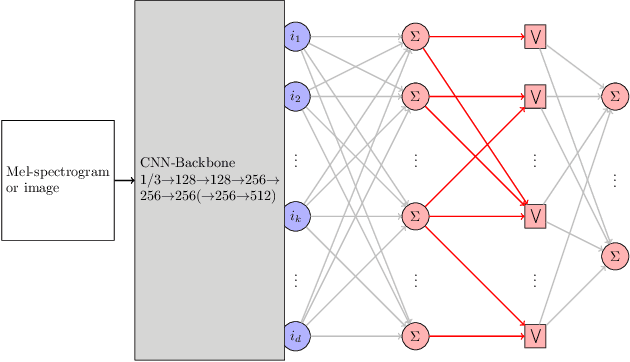
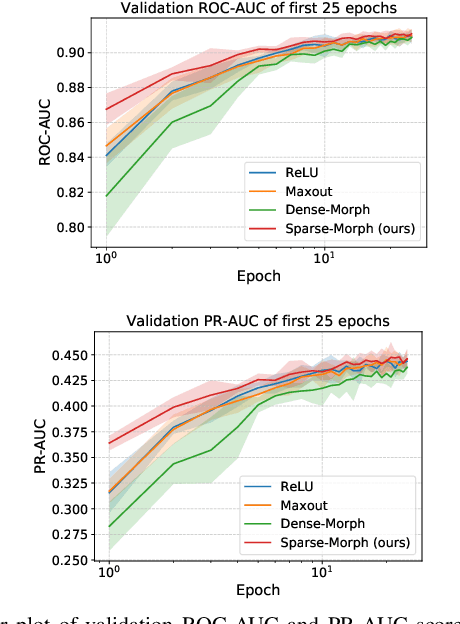
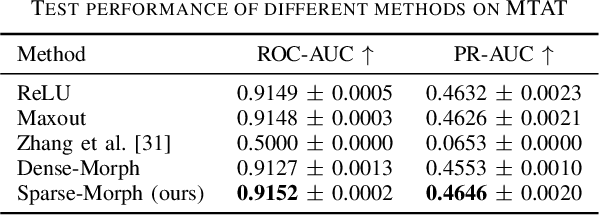

We investigate hybrid linear-morphological networks. Recent studies highlight the inherent affinity of morphological layers to pruning, but also their difficulty in training. We propose a hybrid network structure, wherein morphological layers are inserted between the linear layers of the network, in place of activation functions. We experiment with the following morphological layers: 1) maxout pooling layers (as a special case of a morphological layer), 2) fully connected dense morphological layers, and 3) a novel, sparsely initialized variant of (2). We conduct experiments on the Magna-Tag-A-Tune (music auto-tagging) and CIFAR-10 (image classification) datasets, replacing the linear classification heads of state-of-the-art convolutional network architectures with our proposed network structure for the various morphological layers. We demonstrate that these networks induce sparsity to their linear layers, making them more prunable under L1 unstructured pruning. We also show that on MTAT our proposed sparsely initialized layer achieves slightly better performance than ReLU, maxout, and densely initialized max-plus layers, and exhibits faster initial convergence.