 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassical Guitar Duet Separation using GuitarDuets -- a Dataset of Real and Synthesized Guitar Recordings
Jul 01, 2025Recent advancements in music source separation (MSS) have focused in the multi-timbral case, with existing architectures tailored for the separation of distinct instruments, overlooking thus the challenge of separating instruments with similar timbral characteristics. Addressing this gap, our work focuses on monotimbral MSS, specifically within the context of classical guitar duets. To this end, we introduce the GuitarDuets dataset, featuring a combined total of approximately three hours of real and synthesized classical guitar duet recordings, as well as note-level annotations of the synthesized duets. We perform an extensive cross-dataset evaluation by adapting Demucs, a state-of-the-art MSS architecture, to monotimbral source separation. Furthermore, we develop a joint permutation-invariant transcription and separation framework, to exploit note event predictions as auxiliary information. Our results indicate that utilizing both the real and synthesized subsets of GuitarDuets leads to improved separation performance in an independently recorded test set compared to utilizing solely one subset. We also find that while the availability of ground-truth note labels greatly helps the performance of the separation network, the predicted note estimates result only in marginal improvement. Finally, we discuss the behavior of commonly utilized metrics, such as SDR and SI-SDR, in the context of monotimbral MSS.
* In Proceedings of the 25th International Society for Music Information Retrieval Conference (ISMIR 2024), San Francisco, USA, November 2024. The dataset is available at: https://zenodo.org/records/12802440
Sparse Hybrid Linear-Morphological Networks
Apr 12, 2025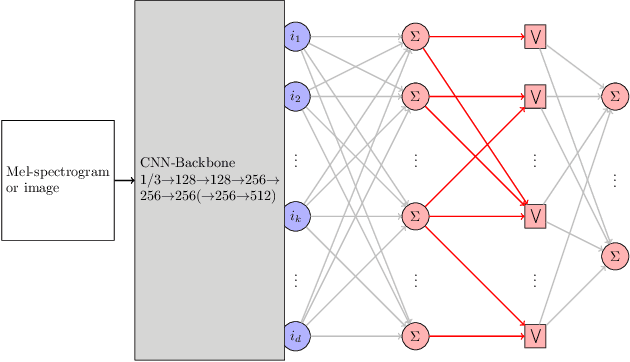
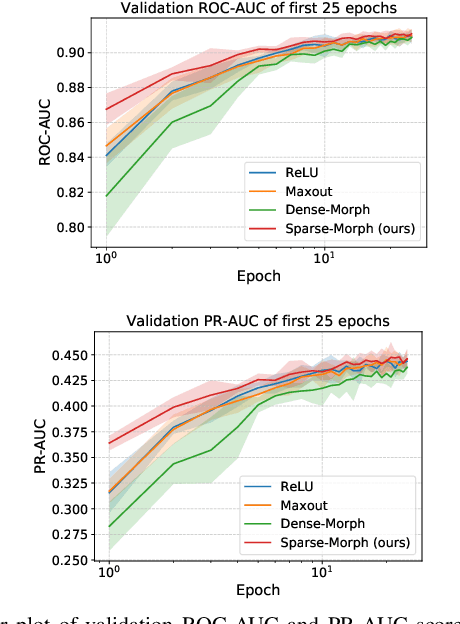
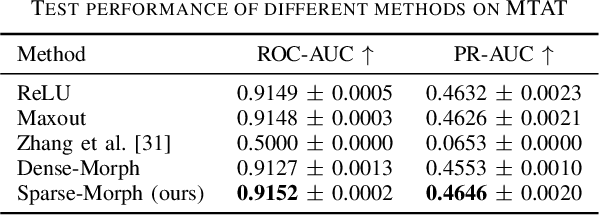

We investigate hybrid linear-morphological networks. Recent studies highlight the inherent affinity of morphological layers to pruning, but also their difficulty in training. We propose a hybrid network structure, wherein morphological layers are inserted between the linear layers of the network, in place of activation functions. We experiment with the following morphological layers: 1) maxout pooling layers (as a special case of a morphological layer), 2) fully connected dense morphological layers, and 3) a novel, sparsely initialized variant of (2). We conduct experiments on the Magna-Tag-A-Tune (music auto-tagging) and CIFAR-10 (image classification) datasets, replacing the linear classification heads of state-of-the-art convolutional network architectures with our proposed network structure for the various morphological layers. We demonstrate that these networks induce sparsity to their linear layers, making them more prunable under L1 unstructured pruning. We also show that on MTAT our proposed sparsely initialized layer achieves slightly better performance than ReLU, maxout, and densely initialized max-plus layers, and exhibits faster initial convergence.
Pre-training Music Classification Models via Music Source Separation
Oct 24, 2023



In this paper, we study whether music source separation can be used as a pre-training strategy for music representation learning, targeted at music classification tasks. To this end, we first pre-train U-Net networks under various music source separation objectives, such as the isolation of vocal or instrumental sources from a musical piece; afterwards, we attach a convolutional tail network to the pre-trained U-Net and jointly finetune the whole network. The features learned by the separation network are also propagated to the tail network through skip connections. Experimental results in two widely used and publicly available datasets indicate that pre-training the U-Nets with a music source separation objective can improve performance compared to both training the whole network from scratch and using the tail network as a standalone in two music classification tasks: music auto-tagging, when vocal separation is used, and music genre classification for the case of multi-source separation.
Multi-Source Contrastive Learning from Musical Audio
Feb 14, 2023Contrastive learning constitutes an emerging branch of self-supervised learning that leverages large amounts of unlabeled data, by learning a latent space, where pairs of different views of the same sample are associated. In this paper, we propose musical source association as a pair generation strategy in the context of contrastive music representation learning. To this end, we modify COLA, a widely used contrastive learning audio framework, to learn to associate a song excerpt with a stochastically selected and automatically extracted vocal or instrumental source. We further introduce a novel modification to the contrastive loss to incorporate information about the existence or absence of specific sources. Our experimental evaluation in three different downstream tasks (music auto-tagging, instrument classification and music genre classification) using the publicly available Magna-Tag-A-Tune (MTAT) as a source dataset yields competitive results to existing literature methods, as well as faster network convergence. The results also show that this pre-training method can be steered towards specific features, according to the selected musical source, while also being dependent on the quality of the separated sources.
Enhancing Affective Representations of Music-Induced EEG through Multimodal Supervision and latent Domain Adaptation
Feb 20, 2022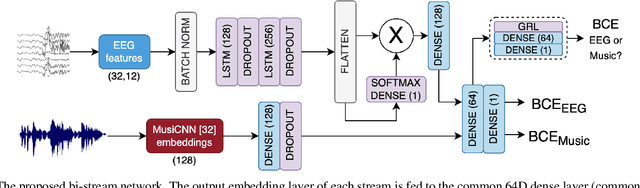

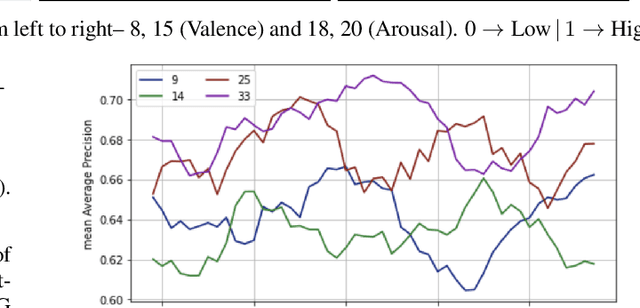
The study of Music Cognition and neural responses to music has been invaluable in understanding human emotions. Brain signals, though, manifest a highly complex structure that makes processing and retrieving meaningful features challenging, particularly of abstract constructs like affect. Moreover, the performance of learning models is undermined by the limited amount of available neuronal data and their severe inter-subject variability. In this paper we extract efficient, personalized affective representations from EEG signals during music listening. To this end, we employ music signals as a supervisory modality to EEG, aiming to project their semantic correspondence onto a common representation space. We utilize a bi-modal framework by combining an LSTM-based attention model to process EEG and a pre-trained model for music tagging, along with a reverse domain discriminator to align the distributions of the two modalities, further constraining the learning process with emotion tags. The resulting framework can be utilized for emotion recognition both directly, by performing supervised predictions from either modality, and indirectly, by providing relevant music samples to EEG input queries. The experimental findings show the potential of enhancing neuronal data through stimulus information for recognition purposes and yield insights into the distribution and temporal variance of music-induced affective features.
HTMD-Net: A Hybrid Masking-Denoising Approach to Time-Domain Monaural Singing Voice Separation
Mar 07, 2021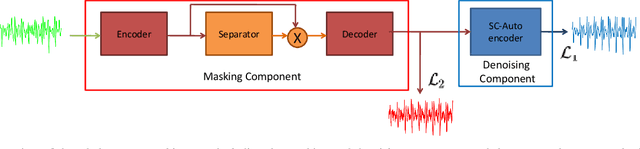
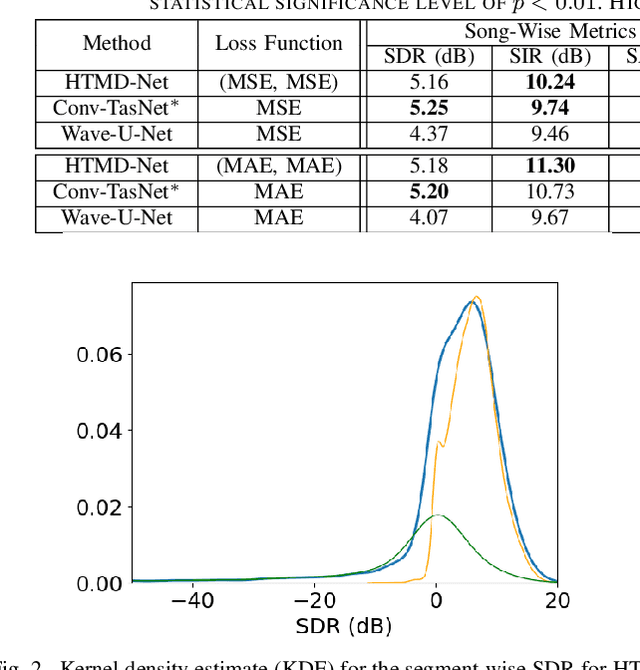
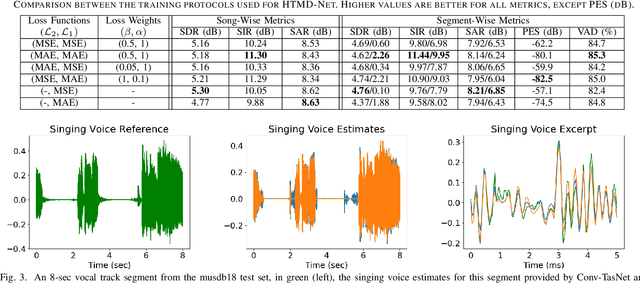

The advent of deep learning has led to the prevalence of deep neural network architectures for monaural music source separation, with end-to-end approaches that operate directly on the waveform level increasingly receiving research attention. Among these approaches, transformation of the input mixture to a learned latent space, and multiplicative application of a soft mask to the latent mixture, achieves the best performance, but is prone to the introduction of artifacts to the source estimate. To alleviate this problem, in this paper we propose a hybrid time-domain approach, termed the HTMD-Net, combining a lightweight masking component and a denoising module, based on skip connections, in order to refine the source estimated by the masking procedure. Evaluation of our approach in the task of monaural singing voice separation in the musdb18 dataset indicates that our proposed method achieves competitive performance compared to methods based purely on masking when trained under the same conditions, especially regarding the behavior during silent segments, while achieving higher computational efficiency.
Deep Convolutional and Recurrent Networks for Polyphonic Instrument Classification from Monophonic Raw Audio Waveforms
Feb 13, 2021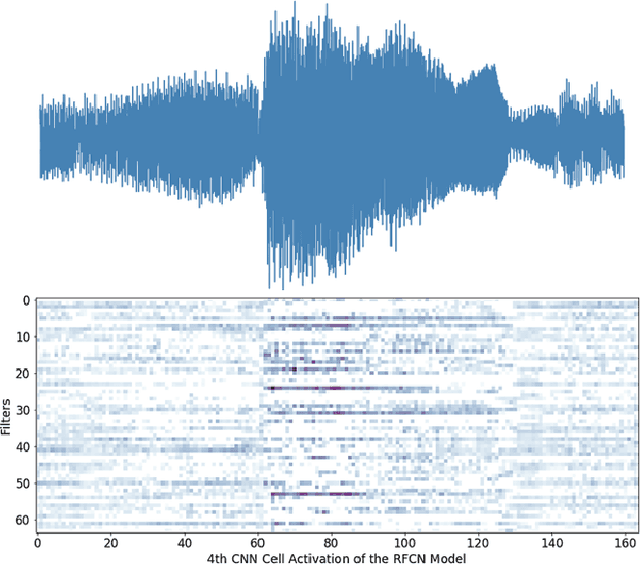
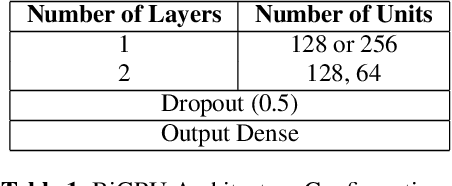
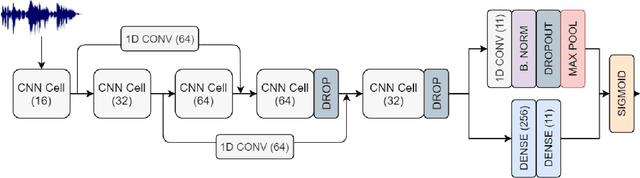

Sound Event Detection and Audio Classification tasks are traditionally addressed through time-frequency representations of audio signals such as spectrograms. However, the emergence of deep neural networks as efficient feature extractors has enabled the direct use of audio signals for classification purposes. In this paper, we attempt to recognize musical instruments in polyphonic audio by only feeding their raw waveforms into deep learning models. Various recurrent and convolutional architectures incorporating residual connections are examined and parameterized in order to build end-to-end classi-fiers with low computational cost and only minimal preprocessing. We obtain competitive classification scores and useful instrument-wise insight through the IRMAS test set, utilizing a parallel CNN-BiGRU model with multiple residual connections, while maintaining a significantly reduced number of trainable parameters.
Multiscale Fractal Analysis of Stimulated EEG Signals with Application to Emotion Classification
Oct 30, 2020



Emotion Recognition from EEG signals has long been researched as it can assist numerous medical and rehabilitative applications. However, their complex and noisy structure has proven to be a serious barrier for traditional modeling methods. In this paper we employ multifractal analysis to examine the behavior of EEG signals in terms of presence of fluctuations and the degree of fragmentation along their major frequency bands, for the task of emotion recognition. In order to extract emotion-related features we utilize two novel algorithms for EEG analysis, based on Multiscale Fractal Dimension and Multifractal Detrended Fluctuation Analysis. The proposed feature extraction methods perform efficiently, surpassing some widely used baseline features on the competitive DEAP dataset, indicating that multifractal analysis could serve as basis for the development of robust models for affective state recognition.
Augmentation Methods on Monophonic Audio for Instrument Classification in Polyphonic Music
Nov 28, 2019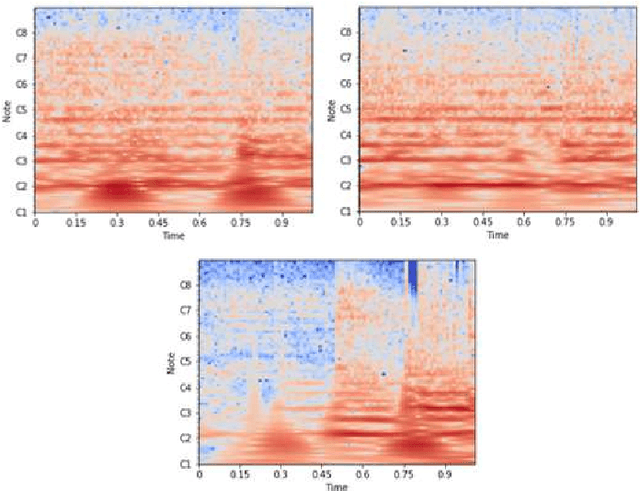

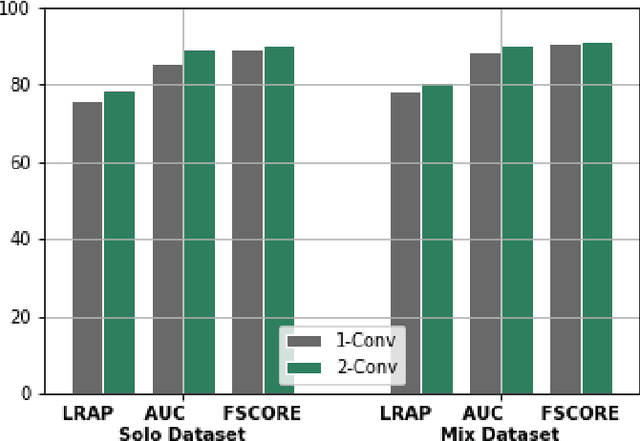

Instrument classification is one of the fields in Music Information Retrieval (MIR) that has attracted a lot of research interest. However, the majority of that is dealing with monophonic music, while efforts on polyphonic material mainly focus on predominant instrument recognition or multi-instrument recognition for entire tracks. We present an approach for instrument classification in polyphonic music using monophonic training data that involves mixing-augmentation methods. Specifically, we experiment with pitch and tempo-based synchronization, as well as mixes of tracks with similar music genres. Further, a custom CNN model is proposed, that uses the augmented training data efficiently and a plethora of suitable evaluation metrics are discussed as well. The tempo-sync and genre techniques stand out, achieving an 81% label ranking average precision accuracy, detecting up to 9 instruments in over 2300 testing tracks.