 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Robot Platform for Robotic Triage Combining Onboard Sensing and Foundation Models
Dec 09, 2025
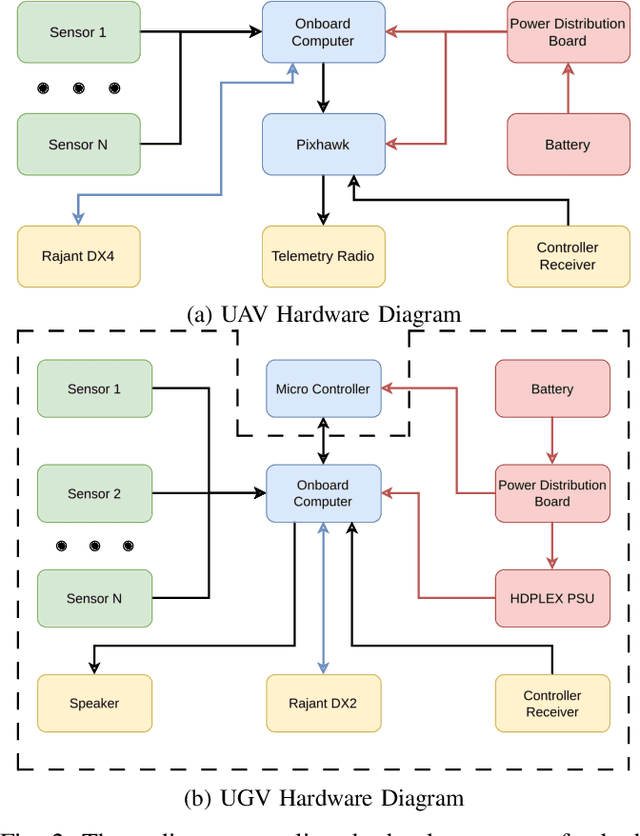
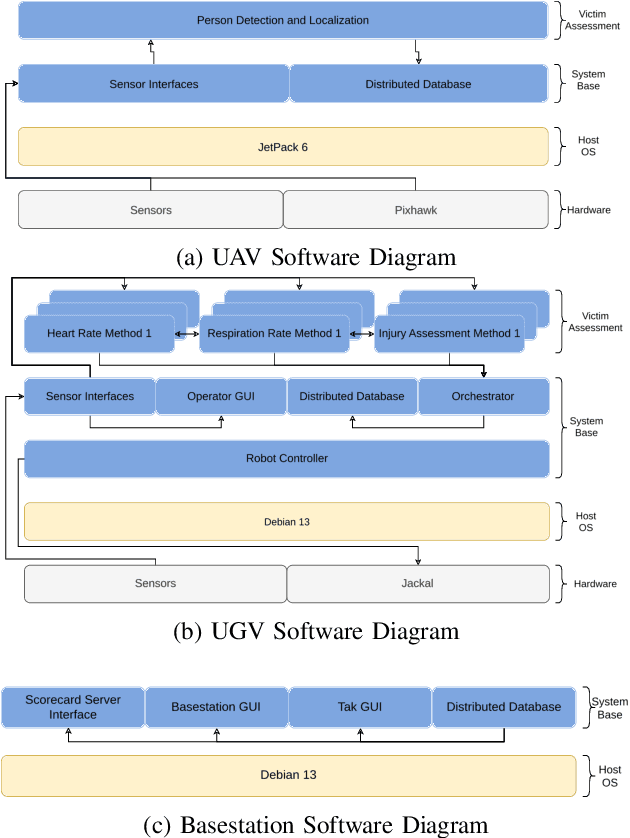
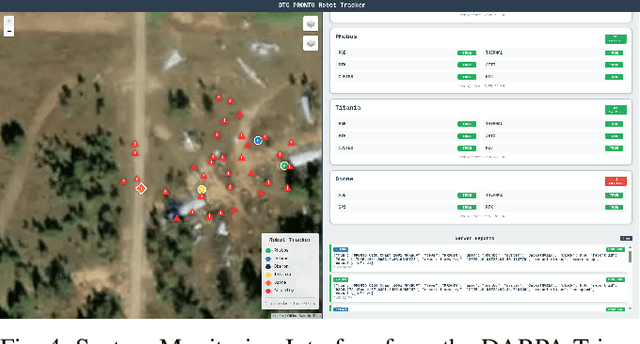
This report presents a heterogeneous robotic system designed for remote primary triage in mass-casualty incidents (MCIs). The system employs a coordinated air-ground team of unmanned aerial vehicles (UAVs) and unmanned ground vehicles (UGVs) to locate victims, assess their injuries, and prioritize medical assistance without risking the lives of first responders. The UAV identify and provide overhead views of casualties, while UGVs equipped with specialized sensors measure vital signs and detect and localize physical injuries. Unlike previous work that focused on exploration or limited medical evaluation, this system addresses the complete triage process: victim localization, vital sign measurement, injury severity classification, mental status assessment, and data consolidation for first responders. Developed as part of the DARPA Triage Challenge, this approach demonstrates how multi-robot systems can augment human capabilities in disaster response scenarios to maximize lives saved.
DynMF: Neural Motion Factorization for Real-time Dynamic View Synthesis with 3D Gaussian Splatting
Nov 30, 2023Accurately and efficiently modeling dynamic scenes and motions is considered so challenging a task due to temporal dynamics and motion complexity. To address these challenges, we propose DynMF, a compact and efficient representation that decomposes a dynamic scene into a few neural trajectories. We argue that the per-point motions of a dynamic scene can be decomposed into a small set of explicit or learned trajectories. Our carefully designed neural framework consisting of a tiny set of learned basis queried only in time allows for rendering speed similar to 3D Gaussian Splatting, surpassing 120 FPS, while at the same time, requiring only double the storage compared to static scenes. Our neural representation adequately constrains the inherently underconstrained motion field of a dynamic scene leading to effective and fast optimization. This is done by biding each point to motion coefficients that enforce the per-point sharing of basis trajectories. By carefully applying a sparsity loss to the motion coefficients, we are able to disentangle the motions that comprise the scene, independently control them, and generate novel motion combinations that have never been seen before. We can reach state-of-the-art render quality within just 5 minutes of training and in less than half an hour, we can synthesize novel views of dynamic scenes with superior photorealistic quality. Our representation is interpretable, efficient, and expressive enough to offer real-time view synthesis of complex dynamic scene motions, in monocular and multi-view scenarios.
Deep Convolutional and Recurrent Networks for Polyphonic Instrument Classification from Monophonic Raw Audio Waveforms
Feb 13, 2021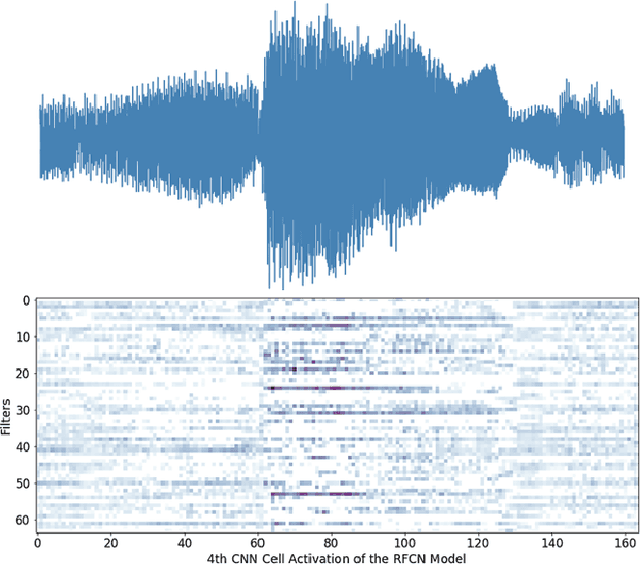
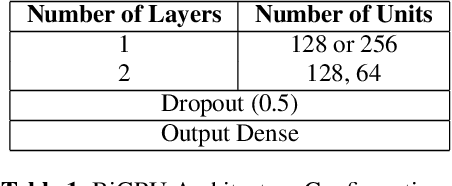
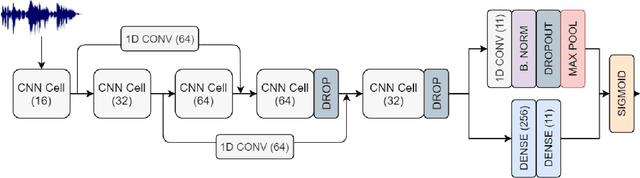

Sound Event Detection and Audio Classification tasks are traditionally addressed through time-frequency representations of audio signals such as spectrograms. However, the emergence of deep neural networks as efficient feature extractors has enabled the direct use of audio signals for classification purposes. In this paper, we attempt to recognize musical instruments in polyphonic audio by only feeding their raw waveforms into deep learning models. Various recurrent and convolutional architectures incorporating residual connections are examined and parameterized in order to build end-to-end classi-fiers with low computational cost and only minimal preprocessing. We obtain competitive classification scores and useful instrument-wise insight through the IRMAS test set, utilizing a parallel CNN-BiGRU model with multiple residual connections, while maintaining a significantly reduced number of trainable parameters.
Independent Sign Language Recognition with 3D Body, Hands, and Face Reconstruction
Nov 24, 2020
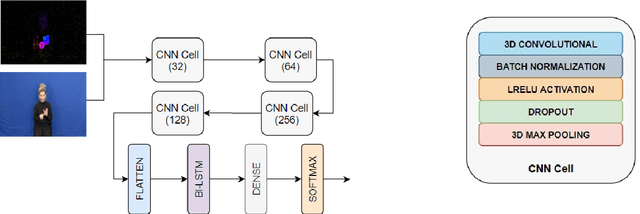

Independent Sign Language Recognition is a complex visual recognition problem that combines several challenging tasks of Computer Vision due to the necessity to exploit and fuse information from hand gestures, body features and facial expressions. While many state-of-the-art works have managed to deeply elaborate on these features independently, to the best of our knowledge, no work has adequately combined all three information channels to efficiently recognize Sign Language. In this work, we employ SMPL-X, a contemporary parametric model that enables joint extraction of 3D body shape, face and hands information from a single image. We use this holistic 3D reconstruction for SLR, demonstrating that it leads to higher accuracy than recognition from raw RGB images and their optical flow fed into the state-of-the-art I3D-type network for 3D action recognition and from 2D Openpose skeletons fed into a Recurrent Neural Network. Finally, a set of experiments on the body, face and hand features showed that neglecting any of these, significantly reduces the classification accuracy, proving the importance of jointly modeling body shape, facial expression and hand pose for Sign Language Recognition.
Augmentation Methods on Monophonic Audio for Instrument Classification in Polyphonic Music
Nov 28, 2019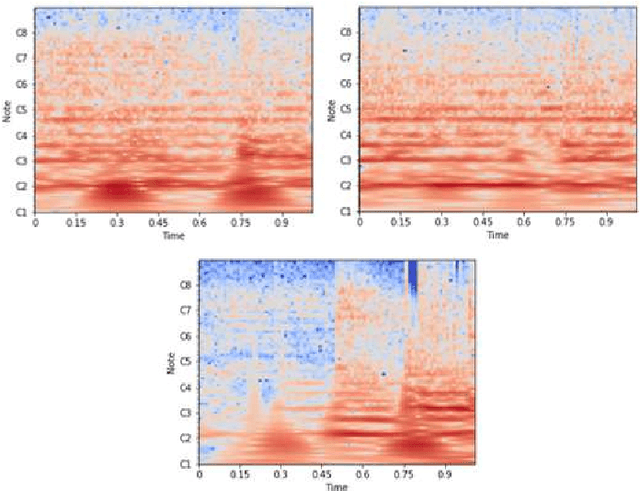

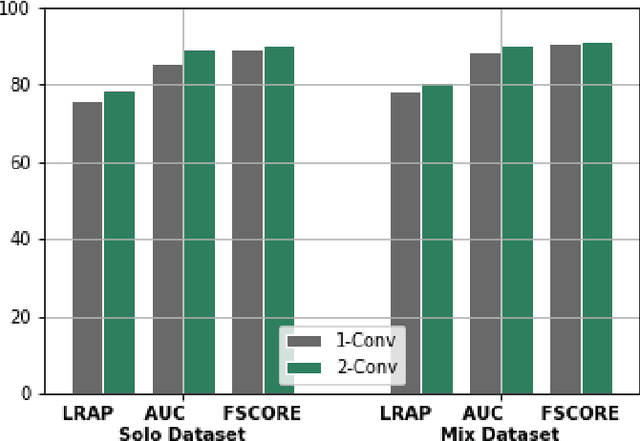

Instrument classification is one of the fields in Music Information Retrieval (MIR) that has attracted a lot of research interest. However, the majority of that is dealing with monophonic music, while efforts on polyphonic material mainly focus on predominant instrument recognition or multi-instrument recognition for entire tracks. We present an approach for instrument classification in polyphonic music using monophonic training data that involves mixing-augmentation methods. Specifically, we experiment with pitch and tempo-based synchronization, as well as mixes of tracks with similar music genres. Further, a custom CNN model is proposed, that uses the augmented training data efficiently and a plethora of suitable evaluation metrics are discussed as well. The tempo-sync and genre techniques stand out, achieving an 81% label ranking average precision accuracy, detecting up to 9 instruments in over 2300 testing tracks.