 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIMO: Diverse 3D Motion Generation for Arbitrary Objects
Nov 10, 2025
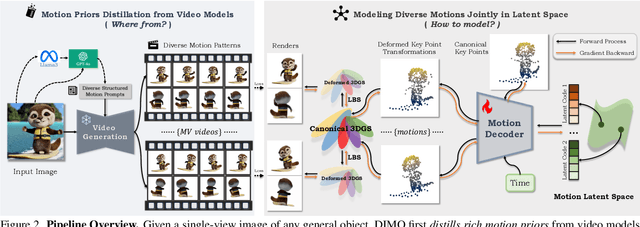
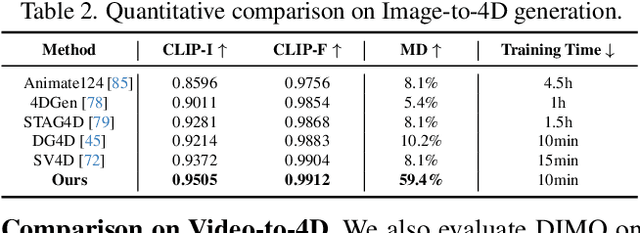

We present DIMO, a generative approach capable of generating diverse 3D motions for arbitrary objects from a single image. The core idea of our work is to leverage the rich priors in well-trained video models to extract the common motion patterns and then embed them into a shared low-dimensional latent space. Specifically, we first generate multiple videos of the same object with diverse motions. We then embed each motion into a latent vector and train a shared motion decoder to learn the distribution of motions represented by a structured and compact motion representation, i.e., neural key point trajectories. The canonical 3D Gaussians are then driven by these key points and fused to model the geometry and appearance. During inference time with learned latent space, we can instantly sample diverse 3D motions in a single-forward pass and support several interesting applications including 3D motion interpolation and language-guided motion generation. Our project page is available at https://linzhanm.github.io/dimo.
StereoDiff: Stereo-Diffusion Synergy for Video Depth Estimation
Jun 25, 2025



Recent video depth estimation methods achieve great performance by following the paradigm of image depth estimation, i.e., typically fine-tuning pre-trained video diffusion models with massive data. However, we argue that video depth estimation is not a naive extension of image depth estimation. The temporal consistency requirements for dynamic and static regions in videos are fundamentally different. Consistent video depth in static regions, typically backgrounds, can be more effectively achieved via stereo matching across all frames, which provides much stronger global 3D cues. While the consistency for dynamic regions still should be learned from large-scale video depth data to ensure smooth transitions, due to the violation of triangulation constraints. Based on these insights, we introduce StereoDiff, a two-stage video depth estimator that synergizes stereo matching for mainly the static areas with video depth diffusion for maintaining consistent depth transitions in dynamic areas. We mathematically demonstrate how stereo matching and video depth diffusion offer complementary strengths through frequency domain analysis, highlighting the effectiveness of their synergy in capturing the advantages of both. Experimental results on zero-shot, real-world, dynamic video depth benchmarks, both indoor and outdoor, demonstrate StereoDiff's SoTA performance, showcasing its superior consistency and accuracy in video depth estimation.
Zero-1-to-G: Taming Pretrained 2D Diffusion Model for Direct 3D Generation
Jan 09, 2025



Recent advances in 2D image generation have achieved remarkable quality,largely driven by the capacity of diffusion models and the availability of large-scale datasets. However, direct 3D generation is still constrained by the scarcity and lower fidelity of 3D datasets. In this paper, we introduce Zero-1-to-G, a novel approach that addresses this problem by enabling direct single-view generation on Gaussian splats using pretrained 2D diffusion models. Our key insight is that Gaussian splats, a 3D representation, can be decomposed into multi-view images encoding different attributes. This reframes the challenging task of direct 3D generation within a 2D diffusion framework, allowing us to leverage the rich priors of pretrained 2D diffusion models. To incorporate 3D awareness, we introduce cross-view and cross-attribute attention layers, which capture complex correlations and enforce 3D consistency across generated splats. This makes Zero-1-to-G the first direct image-to-3D generative model to effectively utilize pretrained 2D diffusion priors, enabling efficient training and improved generalization to unseen objects. Extensive experiments on both synthetic and in-the-wild datasets demonstrate superior performance in 3D object generation, offering a new approach to high-quality 3D generation.
ProTracker: Probabilistic Integration for Robust and Accurate Point Tracking
Jan 06, 2025In this paper, we propose ProTracker, a novel framework for robust and accurate long-term dense tracking of arbitrary points in videos. The key idea of our method is incorporating probabilistic integration to refine multiple predictions from both optical flow and semantic features for robust short-term and long-term tracking. Specifically, we integrate optical flow estimations in a probabilistic manner, producing smooth and accurate trajectories by maximizing the likelihood of each prediction. To effectively re-localize challenging points that disappear and reappear due to occlusion, we further incorporate long-term feature correspondence into our flow predictions for continuous trajectory generation. Extensive experiments show that ProTracker achieves the state-of-the-art performance among unsupervised and self-supervised approaches, and even outperforms supervised methods on several benchmarks. Our code and model will be publicly available upon publication.
VideoLifter: Lifting Videos to 3D with Fast Hierarchical Stereo Alignment
Jan 03, 2025



Efficiently reconstructing accurate 3D models from monocular video is a key challenge in computer vision, critical for advancing applications in virtual reality, robotics, and scene understanding. Existing approaches typically require pre-computed camera parameters and frame-by-frame reconstruction pipelines, which are prone to error accumulation and entail significant computational overhead. To address these limitations, we introduce VideoLifter, a novel framework that leverages geometric priors from a learnable model to incrementally optimize a globally sparse to dense 3D representation directly from video sequences. VideoLifter segments the video sequence into local windows, where it matches and registers frames, constructs consistent fragments, and aligns them hierarchically to produce a unified 3D model. By tracking and propagating sparse point correspondences across frames and fragments, VideoLifter incrementally refines camera poses and 3D structure, minimizing reprojection error for improved accuracy and robustness. This approach significantly accelerates the reconstruction process, reducing training time by over 82% while surpassing current state-of-the-art methods in visual fidelity and computational efficiency.
HDGS: Textured 2D Gaussian Splatting for Enhanced Scene Rendering
Dec 02, 2024



Recent advancements in neural rendering, particularly 2D Gaussian Splatting (2DGS), have shown promising results for jointly reconstructing fine appearance and geometry by leveraging 2D Gaussian surfels. However, current methods face significant challenges when rendering at arbitrary viewpoints, such as anti-aliasing for down-sampled rendering, and texture detail preservation for high-resolution rendering. We proposed a novel method to align the 2D surfels with texture maps and augment it with per-ray depth sorting and fisher-based pruning for rendering consistency and efficiency. With correct order, per-surfel texture maps significantly improve the capabilities to capture fine details. Additionally, to render high-fidelity details in varying viewpoints, we designed a frustum-based sampling method to mitigate the aliasing artifacts. Experimental results on benchmarks and our custom texture-rich dataset demonstrate that our method surpasses existing techniques, particularly in detail preservation and anti-aliasing.
MoSca: Dynamic Gaussian Fusion from Casual Videos via 4D Motion Scaffolds
May 27, 2024We introduce 4D Motion Scaffolds (MoSca), a neural information processing system designed to reconstruct and synthesize novel views of dynamic scenes from monocular videos captured casually in the wild. To address such a challenging and ill-posed inverse problem, we leverage prior knowledge from foundational vision models, lift the video data to a novel Motion Scaffold (MoSca) representation, which compactly and smoothly encodes the underlying motions / deformations. The scene geometry and appearance are then disentangled from the deformation field, and are encoded by globally fusing the Gaussians anchored onto the MoSca and optimized via Gaussian Splatting. Additionally, camera poses can be seamlessly initialized and refined during the dynamic rendering process, without the need for other pose estimation tools. Experiments demonstrate state-of-the-art performance on dynamic rendering benchmarks.
Track Everything Everywhere Fast and Robustly
Mar 26, 2024



We propose a novel test-time optimization approach for efficiently and robustly tracking any pixel at any time in a video. The latest state-of-the-art optimization-based tracking technique, OmniMotion, requires a prohibitively long optimization time, rendering it impractical for downstream applications. OmniMotion is sensitive to the choice of random seeds, leading to unstable convergence. To improve efficiency and robustness, we introduce a novel invertible deformation network, CaDeX++, which factorizes the function representation into a local spatial-temporal feature grid and enhances the expressivity of the coupling blocks with non-linear functions. While CaDeX++ incorporates a stronger geometric bias within its architectural design, it also takes advantage of the inductive bias provided by the vision foundation models. Our system utilizes monocular depth estimation to represent scene geometry and enhances the objective by incorporating DINOv2 long-term semantics to regulate the optimization process. Our experiments demonstrate a substantial improvement in training speed (more than \textbf{10 times} faster), robustness, and accuracy in tracking over the SoTA optimization-based method OmniMotion.
DynMF: Neural Motion Factorization for Real-time Dynamic View Synthesis with 3D Gaussian Splatting
Nov 30, 2023Accurately and efficiently modeling dynamic scenes and motions is considered so challenging a task due to temporal dynamics and motion complexity. To address these challenges, we propose DynMF, a compact and efficient representation that decomposes a dynamic scene into a few neural trajectories. We argue that the per-point motions of a dynamic scene can be decomposed into a small set of explicit or learned trajectories. Our carefully designed neural framework consisting of a tiny set of learned basis queried only in time allows for rendering speed similar to 3D Gaussian Splatting, surpassing 120 FPS, while at the same time, requiring only double the storage compared to static scenes. Our neural representation adequately constrains the inherently underconstrained motion field of a dynamic scene leading to effective and fast optimization. This is done by biding each point to motion coefficients that enforce the per-point sharing of basis trajectories. By carefully applying a sparsity loss to the motion coefficients, we are able to disentangle the motions that comprise the scene, independently control them, and generate novel motion combinations that have never been seen before. We can reach state-of-the-art render quality within just 5 minutes of training and in less than half an hour, we can synthesize novel views of dynamic scenes with superior photorealistic quality. Our representation is interpretable, efficient, and expressive enough to offer real-time view synthesis of complex dynamic scene motions, in monocular and multi-view scenarios.
GART: Gaussian Articulated Template Models
Nov 27, 2023We introduce Gaussian Articulated Template Model GART, an explicit, efficient, and expressive representation for non-rigid articulated subject capturing and rendering from monocular videos. GART utilizes a mixture of moving 3D Gaussians to explicitly approximate a deformable subject's geometry and appearance. It takes advantage of a categorical template model prior (SMPL, SMAL, etc.) with learnable forward skinning while further generalizing to more complex non-rigid deformations with novel latent bones. GART can be reconstructed via differentiable rendering from monocular videos in seconds or minutes and rendered in novel poses faster than 150fps.