 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentiAvatar: Towards Expressive and Interactive Digital Humans
Apr 03, 2026We present SentiAvatar, a framework for building expressive interactive 3D digital humans, and use it to create SuSu, a virtual character that speaks, gestures, and emotes in real time. Achieving such a system remains challenging, as it requires jointly addressing three key problems: the lack of large-scale, high-quality multimodal data, robust semantic-to-motion mapping, and fine-grained frame-level motion-prosody synchronization. To solve these problems, first, we build SuSuInterActs (21K clips, 37 hours), a dialogue corpus captured via optical motion capture around a single character with synchronized speech, full-body motion, and facial expressions. Second, we pre-train a Motion Foundation Model on 200K+ motion sequences, equipping it with rich action priors that go well beyond the conversation. We then propose an audio-aware plan-then-infill architecture that decouples sentence-level semantic planning from frame-level prosody-driven interpolation, so that generated motions are both semantically appropriate and rhythmically aligned with speech. Experiments show that SentiAvatar achieves state-of-the-art on both SuSuInterActs (R@1 43.64%, nearly 2 times the best baseline) and BEATv2 (FGD 4.941, BC 8.078), producing 6s of output in 0.3s with unlimited multi-turn streaming. The source code, model, and dataset are available at https://sentiavatar.github.io.
ProTracker: Probabilistic Integration for Robust and Accurate Point Tracking
Jan 06, 2025In this paper, we propose ProTracker, a novel framework for robust and accurate long-term dense tracking of arbitrary points in videos. The key idea of our method is incorporating probabilistic integration to refine multiple predictions from both optical flow and semantic features for robust short-term and long-term tracking. Specifically, we integrate optical flow estimations in a probabilistic manner, producing smooth and accurate trajectories by maximizing the likelihood of each prediction. To effectively re-localize challenging points that disappear and reappear due to occlusion, we further incorporate long-term feature correspondence into our flow predictions for continuous trajectory generation. Extensive experiments show that ProTracker achieves the state-of-the-art performance among unsupervised and self-supervised approaches, and even outperforms supervised methods on several benchmarks. Our code and model will be publicly available upon publication.
Semantic Gesticulator: Semantics-Aware Co-Speech Gesture Synthesis
May 17, 2024



In this work, we present Semantic Gesticulator, a novel framework designed to synthesize realistic gestures accompanying speech with strong semantic correspondence. Semantically meaningful gestures are crucial for effective non-verbal communication, but such gestures often fall within the long tail of the distribution of natural human motion. The sparsity of these movements makes it challenging for deep learning-based systems, trained on moderately sized datasets, to capture the relationship between the movements and the corresponding speech semantics. To address this challenge, we develop a generative retrieval framework based on a large language model. This framework efficiently retrieves suitable semantic gesture candidates from a motion library in response to the input speech. To construct this motion library, we summarize a comprehensive list of commonly used semantic gestures based on findings in linguistics, and we collect a high-quality motion dataset encompassing both body and hand movements. We also design a novel GPT-based model with strong generalization capabilities to audio, capable of generating high-quality gestures that match the rhythm of speech. Furthermore, we propose a semantic alignment mechanism to efficiently align the retrieved semantic gestures with the GPT's output, ensuring the naturalness of the final animation. Our system demonstrates robustness in generating gestures that are rhythmically coherent and semantically explicit, as evidenced by a comprehensive collection of examples. User studies confirm the quality and human-likeness of our results, and show that our system outperforms state-of-the-art systems in terms of semantic appropriateness by a clear margin.
BAGS: Building Animatable Gaussian Splatting from a Monocular Video with Diffusion Priors
Mar 18, 2024



Animatable 3D reconstruction has significant applications across various fields, primarily relying on artists' handcraft creation. Recently, some studies have successfully constructed animatable 3D models from monocular videos. However, these approaches require sufficient view coverage of the object within the input video and typically necessitate significant time and computational costs for training and rendering. This limitation restricts the practical applications. In this work, we propose a method to build animatable 3D Gaussian Splatting from monocular video with diffusion priors. The 3D Gaussian representations significantly accelerate the training and rendering process, and the diffusion priors allow the method to learn 3D models with limited viewpoints. We also present the rigid regularization to enhance the utilization of the priors. We perform an extensive evaluation across various real-world videos, demonstrating its superior performance compared to the current state-of-the-art methods.
Learning Controllable 3D Diffusion Models from Single-view Images
Apr 13, 2023



Diffusion models have recently become the de-facto approach for generative modeling in the 2D domain. However, extending diffusion models to 3D is challenging due to the difficulties in acquiring 3D ground truth data for training. On the other hand, 3D GANs that integrate implicit 3D representations into GANs have shown remarkable 3D-aware generation when trained only on single-view image datasets. However, 3D GANs do not provide straightforward ways to precisely control image synthesis. To address these challenges, We present Control3Diff, a 3D diffusion model that combines the strengths of diffusion models and 3D GANs for versatile, controllable 3D-aware image synthesis for single-view datasets. Control3Diff explicitly models the underlying latent distribution (optionally conditioned on external inputs), thus enabling direct control during the diffusion process. Moreover, our approach is general and applicable to any type of controlling input, allowing us to train it with the same diffusion objective without any auxiliary supervision. We validate the efficacy of Control3Diff on standard image generation benchmarks, including FFHQ, AFHQ, and ShapeNet, using various conditioning inputs such as images, sketches, and text prompts. Please see the project website (\url{https://jiataogu.me/control3diff}) for video comparisons.
Rhythmic Gesticulator: Rhythm-Aware Co-Speech Gesture Synthesis with Hierarchical Neural Embeddings
Oct 05, 2022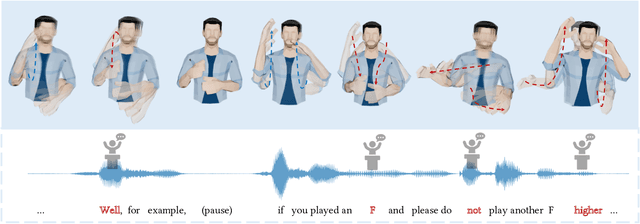
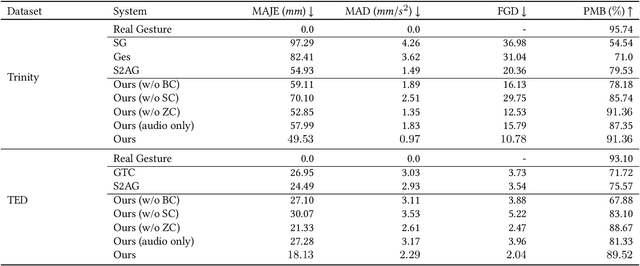
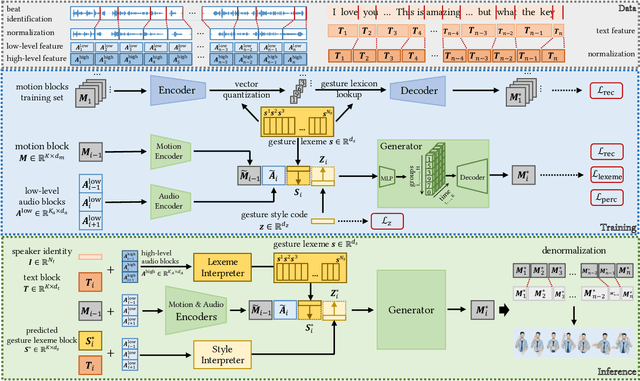

Automatic synthesis of realistic co-speech gestures is an increasingly important yet challenging task in artificial embodied agent creation. Previous systems mainly focus on generating gestures in an end-to-end manner, which leads to difficulties in mining the clear rhythm and semantics due to the complex yet subtle harmony between speech and gestures. We present a novel co-speech gesture synthesis method that achieves convincing results both on the rhythm and semantics. For the rhythm, our system contains a robust rhythm-based segmentation pipeline to ensure the temporal coherence between the vocalization and gestures explicitly. For the gesture semantics, we devise a mechanism to effectively disentangle both low- and high-level neural embeddings of speech and motion based on linguistic theory. The high-level embedding corresponds to semantics, while the low-level embedding relates to subtle variations. Lastly, we build correspondence between the hierarchical embeddings of the speech and the motion, resulting in rhythm- and semantics-aware gesture synthesis. Evaluations with existing objective metrics, a newly proposed rhythmic metric, and human feedback show that our method outperforms state-of-the-art systems by a clear margin.
Neural Novel Actor: Learning a Generalized Animatable Neural Representation for Human Actors
Aug 25, 2022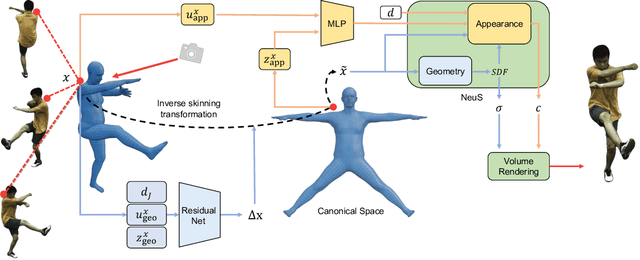

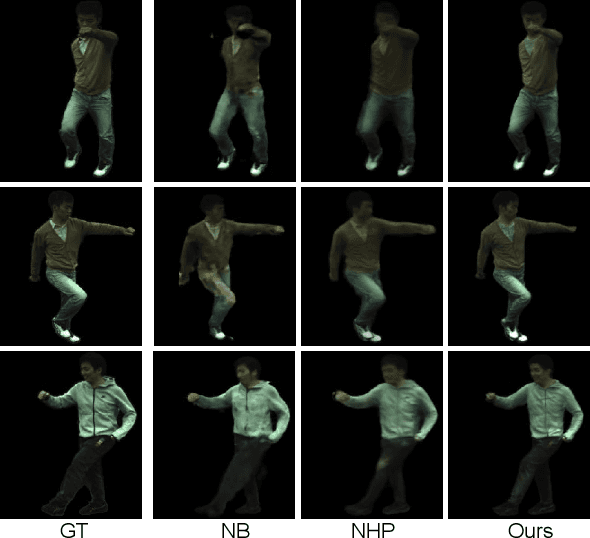

We propose a new method for learning a generalized animatable neural human representation from a sparse set of multi-view imagery of multiple persons. The learned representation can be used to synthesize novel view images of an arbitrary person from a sparse set of cameras, and further animate them with the user's pose control. While existing methods can either generalize to new persons or synthesize animations with user control, none of them can achieve both at the same time. We attribute this accomplishment to the employment of a 3D proxy for a shared multi-person human model, and further the warping of the spaces of different poses to a shared canonical pose space, in which we learn a neural field and predict the person- and pose-dependent deformations, as well as appearance with the features extracted from input images. To cope with the complexity of the large variations in body shapes, poses, and clothing deformations, we design our neural human model with disentangled geometry and appearance. Furthermore, we utilize the image features both at the spatial point and on the surface points of the 3D proxy for predicting person- and pose-dependent properties. Experiments show that our method significantly outperforms the state-of-the-arts on both tasks. The video and code are available at https://talegqz.github.io/neural_novel_actor.
Unsupervised Co-part Segmentation through Assembly
Jun 10, 2021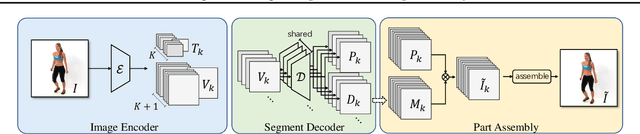
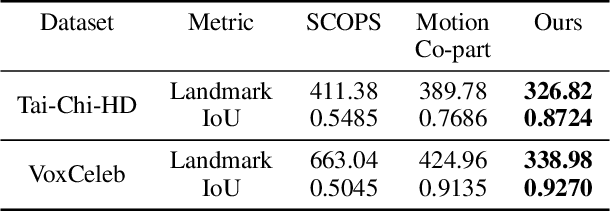
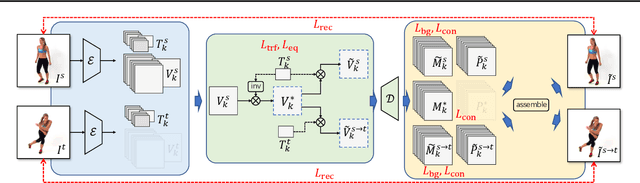
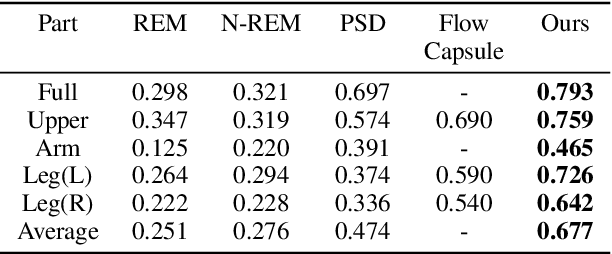
Co-part segmentation is an important problem in computer vision for its rich applications. We propose an unsupervised learning approach for co-part segmentation from images. For the training stage, we leverage motion information embedded in videos and explicitly extract latent representations to segment meaningful object parts. More importantly, we introduce a dual procedure of part-assembly to form a closed loop with part-segmentation, enabling an effective self-supervision. We demonstrate the effectiveness of our approach with a host of extensive experiments, ranging from human bodies, hands, quadruped, and robot arms. We show that our approach can achieve meaningful and compact part segmentation, outperforming state-of-the-art approaches on diverse benchmarks.