 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuGen: Multi-Skill Generative Locomotion Controller for Humanoid Robots
May 23, 2026This paper presents MuGen, a data-driven framework for learning and deploying multi-skill locomotion on humanoid robots. MuGen enables a robot to perform expressive motions like humans under the guidance of example motion sequences. To achieve this, we employ vector-quantized autoencoders (VQ-VAEs) trained with model-based reinforcement learning, resulting in a generative representation of locomotion that captures key patterns of human motion from hours of heterogeneous human performance data. We employ a teacher-student learning framework and develop a new policy distillation strategy to enable a deployable student policy learning this efficient latent representation. This policy allows the robot to track and mimic unseen human motions and further enables the robot to reuse the learned latent space for other tasks. We demonstrate the effectiveness of our framework through a diverse set of motions and accurate execution.
ProAct: A Dual-System Framework for Proactive Embodied Social Agents
Feb 15, 2026Embodied social agents have recently advanced in generating synchronized speech and gestures. However, most interactive systems remain fundamentally reactive, responding only to current sensory inputs within a short temporal window. Proactive social behavior, in contrast, requires deliberation over accumulated context and intent inference, which conflicts with the strict latency budget of real-time interaction. We present \emph{ProAct}, a dual-system framework that reconciles this time-scale conflict by decoupling a low-latency \emph{Behavioral System} for streaming multimodal interaction from a slower \emph{Cognitive System} which performs long-horizon social reasoning and produces high-level proactive intentions. To translate deliberative intentions into continuous non-verbal behaviors without disrupting fluency, we introduce a streaming flow-matching model conditioned on intentions via ControlNet. This mechanism supports asynchronous intention injection, enabling seamless transitions between reactive and proactive gestures within a single motion stream. We deploy ProAct on a physical humanoid robot and evaluate both motion quality and interactive effectiveness. In real-world interaction user studies, participants and observers consistently prefer ProAct over reactive variants in perceived proactivity, social presence, and overall engagement, demonstrating the benefits of dual-system proactive control for embodied social interaction.
DexterCap: An Affordable and Automated System for Capturing Dexterous Hand-Object Manipulation
Jan 09, 2026Capturing fine-grained hand-object interactions is challenging due to severe self-occlusion from closely spaced fingers and the subtlety of in-hand manipulation motions. Existing optical motion capture systems rely on expensive camera setups and extensive manual post-processing, while low-cost vision-based methods often suffer from reduced accuracy and reliability under occlusion. To address these challenges, we present DexterCap, a low-cost optical capture system for dexterous in-hand manipulation. DexterCap uses dense, character-coded marker patches to achieve robust tracking under severe self-occlusion, together with an automated reconstruction pipeline that requires minimal manual effort. With DexterCap, we introduce DexterHand, a dataset of fine-grained hand-object interactions covering diverse manipulation behaviors and objects, from simple primitives to complex articulated objects such as a Rubik's Cube. We release the dataset and code to support future research on dexterous hand-object interaction.
Lumine: An Open Recipe for Building Generalist Agents in 3D Open Worlds
Nov 12, 2025
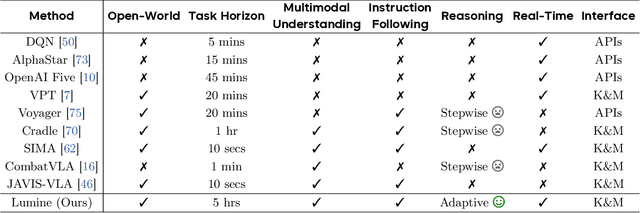


We introduce Lumine, the first open recipe for developing generalist agents capable of completing hours-long complex missions in real time within challenging 3D open-world environments. Lumine adopts a human-like interaction paradigm that unifies perception, reasoning, and action in an end-to-end manner, powered by a vision-language model. It processes raw pixels at 5 Hz to produce precise 30 Hz keyboard-mouse actions and adaptively invokes reasoning only when necessary. Trained in Genshin Impact, Lumine successfully completes the entire five-hour Mondstadt main storyline on par with human-level efficiency and follows natural language instructions to perform a broad spectrum of tasks in both 3D open-world exploration and 2D GUI manipulation across collection, combat, puzzle-solving, and NPC interaction. In addition to its in-domain performance, Lumine demonstrates strong zero-shot cross-game generalization. Without any fine-tuning, it accomplishes 100-minute missions in Wuthering Waves and the full five-hour first chapter of Honkai: Star Rail. These promising results highlight Lumine's effectiveness across distinct worlds and interaction dynamics, marking a concrete step toward generalist agents in open-ended environments.
Social Agent: Mastering Dyadic Nonverbal Behavior Generation via Conversational LLM Agents
Oct 06, 2025We present Social Agent, a novel framework for synthesizing realistic and contextually appropriate co-speech nonverbal behaviors in dyadic conversations. In this framework, we develop an agentic system driven by a Large Language Model (LLM) to direct the conversation flow and determine appropriate interactive behaviors for both participants. Additionally, we propose a novel dual-person gesture generation model based on an auto-regressive diffusion model, which synthesizes coordinated motions from speech signals. The output of the agentic system is translated into high-level guidance for the gesture generator, resulting in realistic movement at both the behavioral and motion levels. Furthermore, the agentic system periodically examines the movements of interlocutors and infers their intentions, forming a continuous feedback loop that enables dynamic and responsive interactions between the two participants. User studies and quantitative evaluations show that our model significantly improves the quality of dyadic interactions, producing natural, synchronized nonverbal behaviors.
Graph Canvas for Controllable 3D Scene Generation
Nov 27, 2024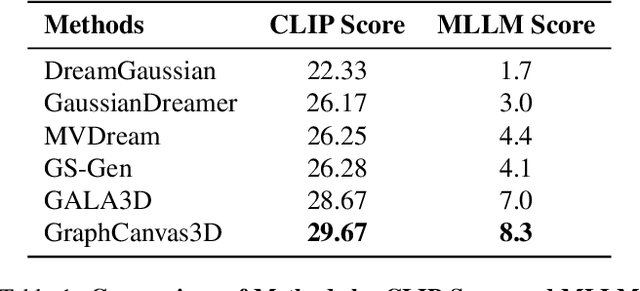
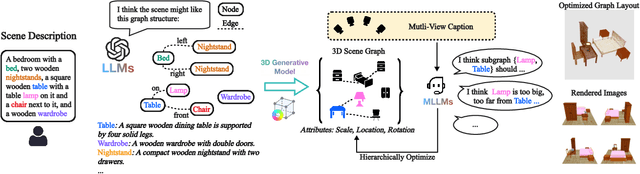
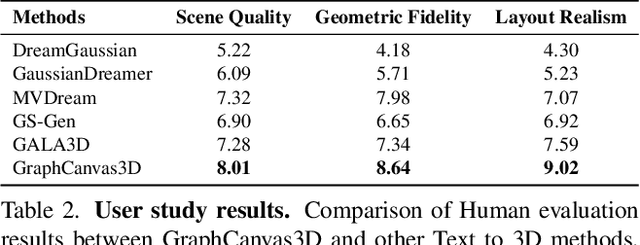
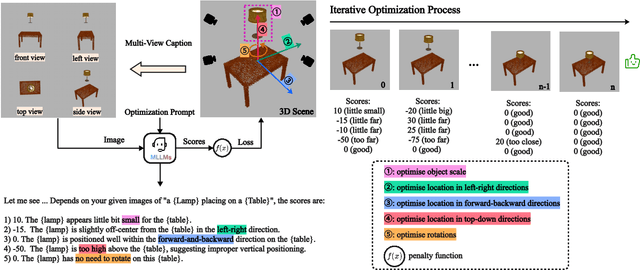
Spatial intelligence is foundational to AI systems that interact with the physical world, particularly in 3D scene generation and spatial comprehension. Current methodologies for 3D scene generation often rely heavily on predefined datasets, and struggle to adapt dynamically to changing spatial relationships. In this paper, we introduce \textbf{GraphCanvas3D}, a programmable, extensible, and adaptable framework for controllable 3D scene generation. Leveraging in-context learning, GraphCanvas3D enables dynamic adaptability without the need for retraining, supporting flexible and customizable scene creation. Our framework employs hierarchical, graph-driven scene descriptions, representing spatial elements as graph nodes and establishing coherent relationships among objects in 3D environments. Unlike conventional approaches, which are constrained in adaptability and often require predefined input masks or retraining for modifications, GraphCanvas3D allows for seamless object manipulation and scene adjustments on the fly. Additionally, GraphCanvas3D supports 4D scene generation, incorporating temporal dynamics to model changes over time. Experimental results and user studies demonstrate that GraphCanvas3D enhances usability, flexibility, and adaptability for scene generation. Our code and models are available on the project website: https://github.com/ILGLJ/Graph-Canvas.
Semantic Gesticulator: Semantics-Aware Co-Speech Gesture Synthesis
May 17, 2024



In this work, we present Semantic Gesticulator, a novel framework designed to synthesize realistic gestures accompanying speech with strong semantic correspondence. Semantically meaningful gestures are crucial for effective non-verbal communication, but such gestures often fall within the long tail of the distribution of natural human motion. The sparsity of these movements makes it challenging for deep learning-based systems, trained on moderately sized datasets, to capture the relationship between the movements and the corresponding speech semantics. To address this challenge, we develop a generative retrieval framework based on a large language model. This framework efficiently retrieves suitable semantic gesture candidates from a motion library in response to the input speech. To construct this motion library, we summarize a comprehensive list of commonly used semantic gestures based on findings in linguistics, and we collect a high-quality motion dataset encompassing both body and hand movements. We also design a novel GPT-based model with strong generalization capabilities to audio, capable of generating high-quality gestures that match the rhythm of speech. Furthermore, we propose a semantic alignment mechanism to efficiently align the retrieved semantic gestures with the GPT's output, ensuring the naturalness of the final animation. Our system demonstrates robustness in generating gestures that are rhythmically coherent and semantically explicit, as evidenced by a comprehensive collection of examples. User studies confirm the quality and human-likeness of our results, and show that our system outperforms state-of-the-art systems in terms of semantic appropriateness by a clear margin.
BAGS: Building Animatable Gaussian Splatting from a Monocular Video with Diffusion Priors
Mar 18, 2024



Animatable 3D reconstruction has significant applications across various fields, primarily relying on artists' handcraft creation. Recently, some studies have successfully constructed animatable 3D models from monocular videos. However, these approaches require sufficient view coverage of the object within the input video and typically necessitate significant time and computational costs for training and rendering. This limitation restricts the practical applications. In this work, we propose a method to build animatable 3D Gaussian Splatting from monocular video with diffusion priors. The 3D Gaussian representations significantly accelerate the training and rendering process, and the diffusion priors allow the method to learn 3D models with limited viewpoints. We also present the rigid regularization to enhance the utilization of the priors. We perform an extensive evaluation across various real-world videos, demonstrating its superior performance compared to the current state-of-the-art methods.
A Spatial-Temporal Transformer based Framework For Human Pose Assessment And Correction in Education Scenarios
Nov 01, 2023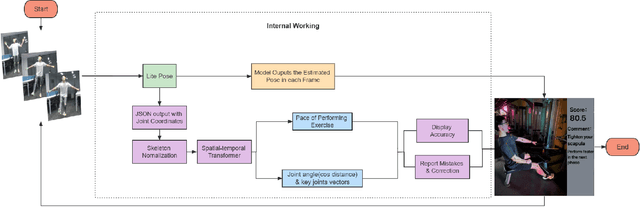
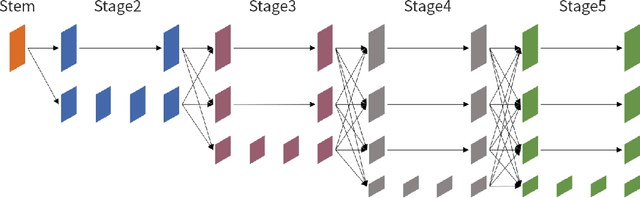
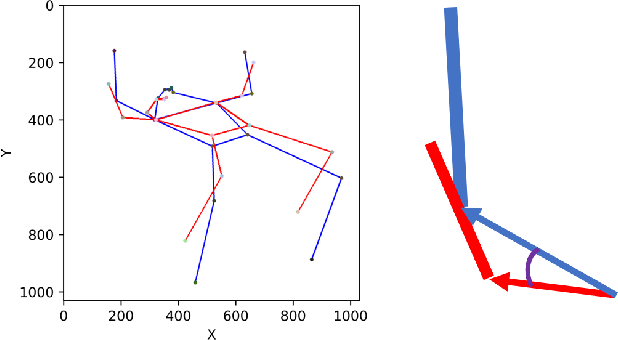

Human pose assessment and correction play a crucial role in applications across various fields, including computer vision, robotics, sports analysis, healthcare, and entertainment. In this paper, we propose a Spatial-Temporal Transformer based Framework (STTF) for human pose assessment and correction in education scenarios such as physical exercises and science experiment. The framework comprising skeletal tracking, pose estimation, posture assessment, and posture correction modules to educate students with professional, quick-to-fix feedback. We also create a pose correction method to provide corrective feedback in the form of visual aids. We test the framework with our own dataset. It comprises (a) new recordings of five exercises, (b) existing recordings found on the internet of the same exercises, and (c) corrective feedback on the recordings by professional athletes and teachers. Results show that our model can effectively measure and comment on the quality of students' actions. The STTF leverages the power of transformer models to capture spatial and temporal dependencies in human poses, enabling accurate assessment and effective correction of students' movements.
MoConVQ: Unified Physics-Based Motion Control via Scalable Discrete Representations
Oct 17, 2023In this work, we present MoConVQ, a novel unified framework for physics-based motion control leveraging scalable discrete representations. Building upon vector quantized variational autoencoders (VQ-VAE) and model-based reinforcement learning, our approach effectively learns motion embeddings from a large, unstructured dataset spanning tens of hours of motion examples. The resultant motion representation not only captures diverse motion skills but also offers a robust and intuitive interface for various applications. We demonstrate the versatility of MoConVQ through several applications: universal tracking control from various motion sources, interactive character control with latent motion representations using supervised learning, physics-based motion generation from natural language descriptions using the GPT framework, and, most interestingly, seamless integration with large language models (LLMs) with in-context learning to tackle complex and abstract tasks.