 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-AUV Cooperative Target Tracking Based on Supervised Diffusion-Aided Multi-Agent Reinforcement Learning
Mar 31, 2026In recent years, advances in underwater networking and multi-agent reinforcement learning (MARL) have significantly expanded multi-autonomous underwater vehicle (AUV) applications in marine exploration and target tracking. However, current MARL-driven cooperative tracking faces three critical challenges: 1) non-stationarity in decentralized coordination, where local policy updates destabilize teammates' observation spaces, preventing convergence; 2) sparse-reward exploration inefficiency from limited underwater visibility and constrained sensor ranges, causing high-variance learning; and 3) water disturbance fragility combined with handcrafted reward dependency that degrades real-world robustness under unmodeled hydrodynamic conditions. To address these challenges, this paper proposes a hierarchical MARL architecture comprising four layers: global training scheduling, multi-agent coordination, local decision-making, and real-time execution. This architecture optimizes task allocation and inter-AUV coordination through hierarchical decomposition. Building on this foundation, we propose the Supervised Diffusion-Aided MARL (SDA-MARL) algorithm featuring three innovations: 1) a dual-decision architecture with segregated experience pools mitigating nonstationarity through structured experience replay; 2) a supervised learning mechanism guiding the diffusion model's reverse denoising process to generate high-fidelity training samples that accelerate convergence; and 3) disturbance-robust policy learning incorporating behavioral cloning loss to guide the Deep Deterministic Policy Gradient network update using high-quality replay actions, eliminating handcrafted reward dependency. The tracking algorithm based on SDA-MARL proposed in this paper achieves superior precision compared to state-of-the-art methods in comprehensive underwater simulations.
Multi-AUV Ad-hoc Networks-Based Multi-Target Tracking Based on Scene-Adaptive Embodied Intelligence
Mar 28, 2026With the rapid advancement of underwater net-working and multi-agent coordination technologies, autonomous underwater vehicle (AUV) ad-hoc networks have emerged as a pivotal framework for executing complex maritime missions, such as multi-target tracking. However, traditional data-centricarchitectures struggle to maintain operational consistency under highly dynamic topological fluctuations and severely constrained acoustic communication bandwidth. This article proposes a scene-adaptive embodied intelligence (EI) architecture for multi-AUV ad-hoc networks, which re-envisions AUVs as embodied entities by integrating perception, decision-making, and physical execution into a unified cognitive loop. To materialize the functional interaction between these layers, we define a beacon-based communication and control model that treats the communication link as a dynamic constraint-aware channel, effectively bridging the gap between high-level policy inference and decentralized physical actuation. Specifically, the proposed architecture employs a three-layer functional framework and introduces a Scene-Adaptive MARL (SA-MARL) algorithm featuring a dual-path critic mechanism. By integrating a scene critic network and a general critic network through a weight-based dynamic fusion process, SA-MARL effectively decouples specialized tracking tasks from global safety constraints, facilitating autonomous policy evolution. Evaluation results demonstrate that the proposedscheme significantly accelerates policy convergence and achieves superior tracking accuracy compared to mainstream MARL approaches, maintaining robust performance even under intense environmental interference and fluid topological shifts.
A Reasoning Paradigm for Named Entity Recognition
Nov 15, 2025



Generative LLMs typically improve Named Entity Recognition (NER) performance through instruction tuning. They excel at generating entities by semantic pattern matching but lack an explicit, verifiable reasoning mechanism. This "cognitive shortcutting" leads to suboptimal performance and brittle generalization, especially in zero-shot and lowresource scenarios where reasoning from limited contextual cues is crucial. To address this issue, a reasoning framework is proposed for NER, which shifts the extraction paradigm from implicit pattern matching to explicit reasoning. This framework consists of three stages: Chain of Thought (CoT) generation, CoT tuning, and reasoning enhancement. First, a dataset annotated with NER-oriented CoTs is generated, which contain task-relevant reasoning chains. Then, they are used to tune the NER model to generate coherent rationales before deriving the final answer. Finally, a reasoning enhancement stage is implemented to optimize the reasoning process using a comprehensive reward signal. This stage ensures explicit and verifiable extractions. Experiments show that ReasoningNER demonstrates impressive cognitive ability in the NER task, achieving competitive performance. In zero-shot settings, it achieves state-of-the-art (SOTA) performance, outperforming GPT-4 by 12.3 percentage points on the F1 score. Analytical results also demonstrate its great potential to advance research in reasoningoriented information extraction. Our codes are available at https://github.com/HuiResearch/ReasoningIE.
UHNet: An Ultra-Lightweight and High-Speed Edge Detection Network
Aug 08, 2024

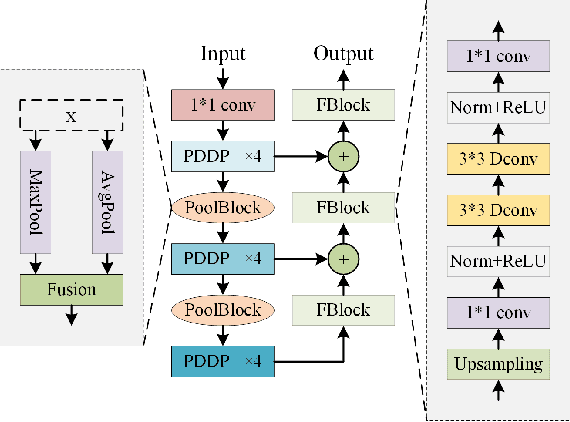

Edge detection is crucial in medical image processing, enabling precise extraction of structural information to support lesion identification and image analysis. Traditional edge detection models typically rely on complex Convolutional Neural Networks and Vision Transformer architectures. Due to their numerous parameters and high computational demands, these models are limited in their application on resource-constrained devices. This paper presents an ultra-lightweight edge detection model (UHNet), characterized by its minimal parameter count, rapid computation speed, negligible of pre-training costs, and commendable performance. UHNet boasts impressive performance metrics with 42.3k parameters, 166 FPS, and 0.79G FLOPs. By employing an innovative feature extraction module and optimized residual connection method, UHNet significantly reduces model complexity and computational requirements. Additionally, a lightweight feature fusion strategy is explored, enhancing detection accuracy. Experimental results on the BSDS500, NYUD, and BIPED datasets validate that UHNet achieves remarkable edge detection performance while maintaining high efficiency. This work not only provides new insights into the design of lightweight edge detection models but also demonstrates the potential and application prospects of the UHNet model in engineering applications such as medical image processing. The codes are available at https://github.com/stoneLi20cv/UHNet
Benchmarking General Purpose In-Context Learning
May 29, 2024



In-context learning (ICL) capabilities are becoming increasingly appealing for building general intelligence due to their sample efficiency and independence from artificial optimization skills. To enhance generalization, biological neural systems primarily inherit learning capabilities and subsequently refine their memory, acquiring diverse skills and knowledge through extensive lifelong experiences. This process gives rise to the concept of general-purpose in-context learning (GPICL). Compared to standard ICL, GPICL addresses a broader range of tasks, extends learning horizons, and starts at a lower zero-shot baseline. We introduce two lightweight but insightful benchmarks specifically crafted to train and evaluate GPICL functionalities. Each benchmark includes a vast number of tasks characterized by significant task variance and minimal transferable knowledge among tasks, facilitating lifelong in-context learning through continuous generation and interaction. These features pose significant challenges for models that rely on context or interactions to improve their proficiency, including language models, decision models, and world models. Our experiments reveal that parameter scale alone may not be crucial for ICL or GPICL, suggesting alternative approaches such as increasing the scale of contexts and memory states.
Semantic Gesticulator: Semantics-Aware Co-Speech Gesture Synthesis
May 17, 2024



In this work, we present Semantic Gesticulator, a novel framework designed to synthesize realistic gestures accompanying speech with strong semantic correspondence. Semantically meaningful gestures are crucial for effective non-verbal communication, but such gestures often fall within the long tail of the distribution of natural human motion. The sparsity of these movements makes it challenging for deep learning-based systems, trained on moderately sized datasets, to capture the relationship between the movements and the corresponding speech semantics. To address this challenge, we develop a generative retrieval framework based on a large language model. This framework efficiently retrieves suitable semantic gesture candidates from a motion library in response to the input speech. To construct this motion library, we summarize a comprehensive list of commonly used semantic gestures based on findings in linguistics, and we collect a high-quality motion dataset encompassing both body and hand movements. We also design a novel GPT-based model with strong generalization capabilities to audio, capable of generating high-quality gestures that match the rhythm of speech. Furthermore, we propose a semantic alignment mechanism to efficiently align the retrieved semantic gestures with the GPT's output, ensuring the naturalness of the final animation. Our system demonstrates robustness in generating gestures that are rhythmically coherent and semantically explicit, as evidenced by a comprehensive collection of examples. User studies confirm the quality and human-likeness of our results, and show that our system outperforms state-of-the-art systems in terms of semantic appropriateness by a clear margin.
Learning Crisp Boundaries Using Deep Refinement Network and Adaptive Weighting Loss
Mar 03, 2021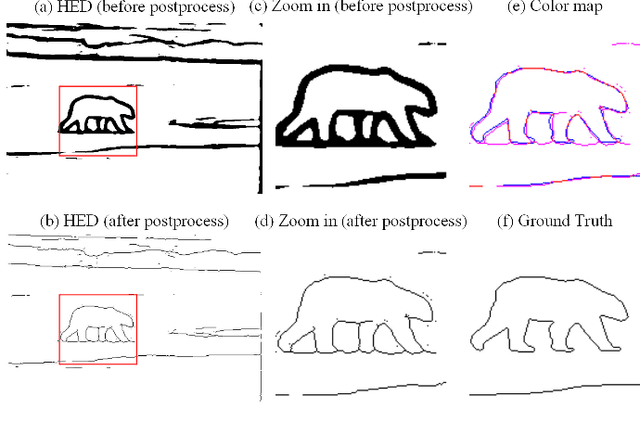

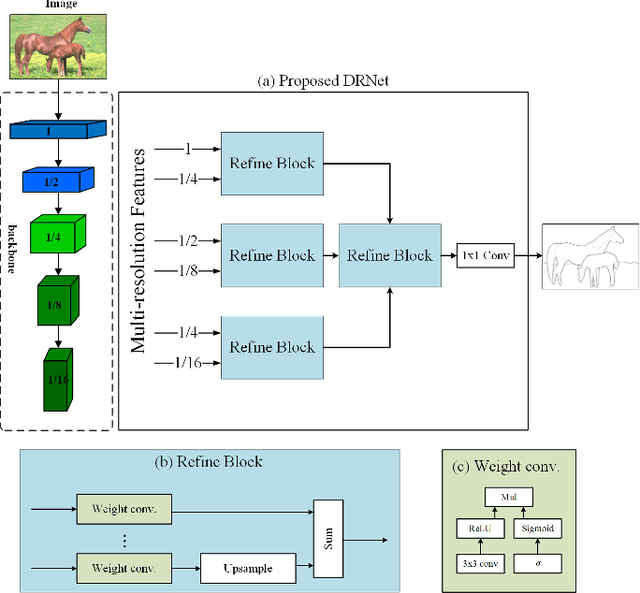
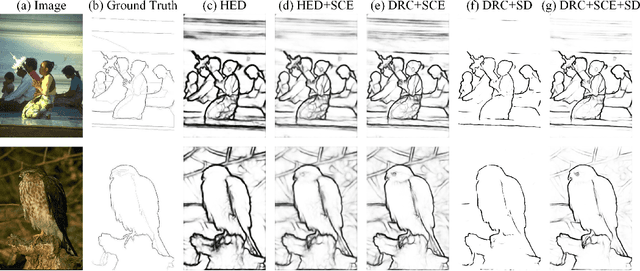
Significant progress has been made in boundary detection with the help of convolutional neural networks. Recent boundary detection models not only focus on real object boundary detection but also "crisp" boundaries (precisely localized along the object's contour). There are two methods to evaluate crisp boundary performance. One uses more strict tolerance to measure the distance between the ground truth and the detected contour. The other focuses on evaluating the contour map without any postprocessing. In this study, we analyze both methods and conclude that both methods are two aspects of crisp contour evaluation. Accordingly, we propose a novel network named deep refinement network (DRNet) that stacks multiple refinement modules to achieve richer feature representation and a novel loss function, which combines cross-entropy and dice loss through effective adaptive fusion. Experimental results demonstrated that we achieve state-of-the-art performance for several available datasets.
* 11 pages, 7 figures