 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBio-inspired Color Constancy: From Gray Anchoring Theory to Gray Pixel Methods
Apr 22, 2026Color constancy is a fundamental ability of many biological visual systems and a crucial step in computer imaging systems. Bio-inspired modeling offers a promising way to elucidate the computational principles underlying color constancy and to develop efficient computational methods. However, bio-inspired methods for color constancy remain underexplored and lack a comprehensive analysis. This paper presents a comprehensive technical framework that integrates biological mechanisms, computational theory, and algorithmic implementation for bio-inspired color constancy. Specifically, we systematically revisit the computational theory of biological color constancy, which shows that illuminant estimation can be reduced to the task of gray-anchor (pixel or surface) detection in early vision. Subsequently, typical gray-pixel detection methods, including Gray-Pixel and Grayness-Index, are reinterpreted within a unified theoretical framework with the Lambertian reflection model and biological color-opponent mechanisms. Finally, we propose a simple learning-based method that couples reflection-model constraints with feature learning to explore the potential of bio-inspired color constancy based on gray-pixel detection. Extensive experiments confirm the effectiveness of gray-pixel detection for color constancy and demonstrate the potential of bio-inspired methods.
A biological vision inspired framework for machine perception of abutting grating illusory contours
Aug 24, 2025Higher levels of machine intelligence demand alignment with human perception and cognition. Deep neural networks (DNN) dominated machine intelligence have demonstrated exceptional performance across various real-world tasks. Nevertheless, recent evidence suggests that DNNs fail to perceive illusory contours like the abutting grating, a discrepancy that misaligns with human perception patterns. Departing from previous works, we propose a novel deep network called illusory contour perception network (ICPNet) inspired by the circuits of the visual cortex. In ICPNet, a multi-scale feature projection (MFP) module is designed to extract multi-scale representations. To boost the interaction between feedforward and feedback features, a feature interaction attention module (FIAM) is introduced. Moreover, drawing inspiration from the shape bias observed in human perception, an edge detection task conducted via the edge fusion module (EFM) injects shape constraints that guide the network to concentrate on the foreground. We assess our method on the existing AG-MNIST test set and the AG-Fashion-MNIST test sets constructed by this work. Comprehensive experimental results reveal that ICPNet is significantly more sensitive to abutting grating illusory contours than state-of-the-art models, with notable improvements in top-1 accuracy across various subsets. This work is expected to make a step towards human-level intelligence for DNN-based models.
Visual Attention Graph
Mar 11, 2025
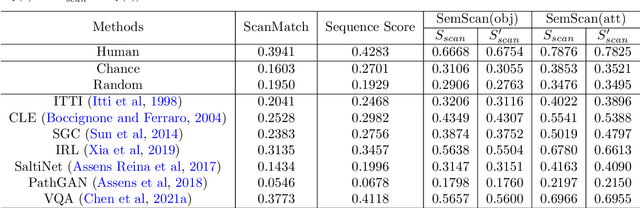
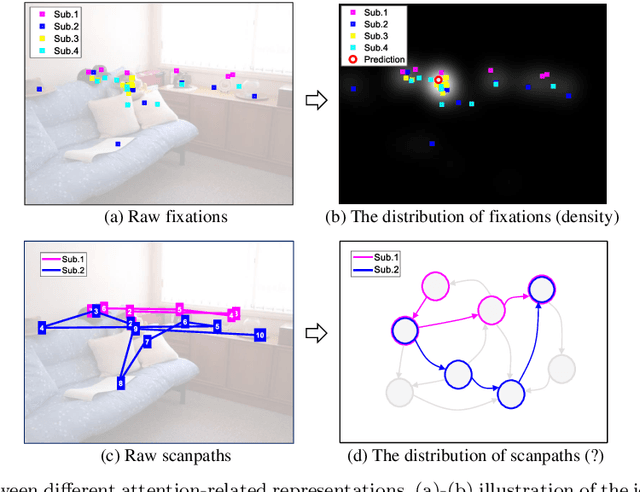

Visual attention plays a critical role when our visual system executes active visual tasks by interacting with the physical scene. However, how to encode the visual object relationship in the psychological world of our brain deserves to be explored. In the field of computer vision, predicting visual fixations or scanpaths is a usual way to explore the visual attention and behaviors of human observers when viewing a scene. Most existing methods encode visual attention using individual fixations or scanpaths based on the raw gaze shift data collected from human observers. This may not capture the common attention pattern well, because without considering the semantic information of the viewed scene, raw gaze shift data alone contain high inter- and intra-observer variability. To address this issue, we propose a new attention representation, called Attention Graph, to simultaneously code the visual saliency and scanpath in a graph-based representation and better reveal the common attention behavior of human observers. In the attention graph, the semantic-based scanpath is defined by the path on the graph, while saliency of objects can be obtained by computing fixation density on each node. Systemic experiments demonstrate that the proposed attention graph combined with our new evaluation metrics provides a better benchmark for evaluating attention prediction methods. Meanwhile, extra experiments demonstrate the promising potentials of the proposed attention graph in assessing human cognitive states, such as autism spectrum disorder screening and age classification.
Systematic Abductive Reasoning via Diverse Relation Representations in Vector-symbolic Architecture
Jan 21, 2025



In abstract visual reasoning, monolithic deep learning models suffer from limited interpretability and generalization, while existing neuro-symbolic approaches fall short in capturing the diversity and systematicity of attributes and relation representations. To address these challenges, we propose a Systematic Abductive Reasoning model with diverse relation representations (Rel-SAR) in Vector-symbolic Architecture (VSA) to solve Raven's Progressive Matrices (RPM). To derive attribute representations with symbolic reasoning potential, we introduce not only various types of atomic vectors that represent numeric, periodic and logical semantics, but also the structured high-dimentional representation (SHDR) for the overall Grid component. For systematic reasoning, we propose novel numerical and logical relation functions and perform rule abduction and execution in a unified framework that integrates these relation representations. Experimental results demonstrate that Rel-SAR achieves significant improvement on RPM tasks and exhibits robust out-of-distribution generalization. Rel-SAR leverages the synergy between HD attribute representations and symbolic reasoning to achieve systematic abductive reasoning with both interpretable and computable semantics.
PESFormer: Boosting Macro- and Micro-expression Spotting with Direct Timestamp Encoding
Oct 24, 2024



The task of macro- and micro-expression spotting aims to precisely localize and categorize temporal expression instances within untrimmed videos. Given the sparse distribution and varying durations of expressions, existing anchor-based methods often represent instances by encoding their deviations from predefined anchors. Additionally, these methods typically slice the untrimmed videos into fixed-length sliding windows. However, anchor-based encoding often fails to capture all training intervals, and slicing the original video as sliding windows can result in valuable training intervals being discarded. To overcome these limitations, we introduce PESFormer, a simple yet effective model based on the vision transformer architecture to achieve point-to-interval expression spotting. PESFormer employs a direct timestamp encoding (DTE) approach to replace anchors, enabling binary classification of each timestamp instead of optimizing entire ground truths. Thus, all training intervals are retained in the form of discrete timestamps. To maximize the utilization of training intervals, we enhance the preprocessing process by replacing the short videos produced through the sliding window method.Instead, we implement a strategy that involves zero-padding the untrimmed training videos to create uniform, longer videos of a predetermined duration. This operation efficiently preserves the original training intervals and eliminates video slice enhancement.Extensive qualitative and quantitative evaluations on three datasets -- CAS(ME)^2, CAS(ME)^3 and SAMM-LV -- demonstrate that our PESFormer outperforms existing techniques, achieving the best performance.
Weak Supervision with Arbitrary Single Frame for Micro- and Macro-expression Spotting
Mar 21, 2024



Frame-level micro- and macro-expression spotting methods require time-consuming frame-by-frame observation during annotation. Meanwhile, video-level spotting lacks sufficient information about the location and number of expressions during training, resulting in significantly inferior performance compared with fully-supervised spotting. To bridge this gap, we propose a point-level weakly-supervised expression spotting (PWES) framework, where each expression requires to be annotated with only one random frame (i.e., a point). To mitigate the issue of sparse label distribution, the prevailing solution is pseudo-label mining, which, however, introduces new problems: localizing contextual background snippets results in inaccurate boundaries and discarding foreground snippets leads to fragmentary predictions. Therefore, we design the strategies of multi-refined pseudo label generation (MPLG) and distribution-guided feature contrastive learning (DFCL) to address these problems. Specifically, MPLG generates more reliable pseudo labels by merging class-specific probabilities, attention scores, fused features, and point-level labels. DFCL is utilized to enhance feature similarity for the same categories and feature variability for different categories while capturing global representations across the entire datasets. Extensive experiments on the CAS(ME)^2, CAS(ME)^3, and SAMM-LV datasets demonstrate PWES achieves promising performance comparable to that of recent fully-supervised methods.
Nighttime Thermal Infrared Image Colorization with Feedback-based Object Appearance Learning
Oct 24, 2023


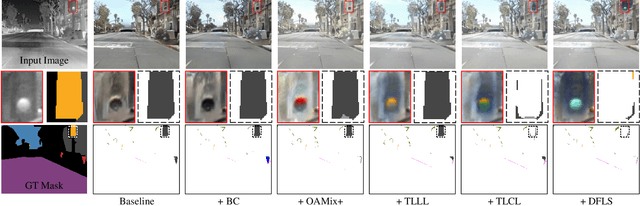
Stable imaging in adverse environments (e.g., total darkness) makes thermal infrared (TIR) cameras a prevalent option for night scene perception. However, the low contrast and lack of chromaticity of TIR images are detrimental to human interpretation and subsequent deployment of RGB-based vision algorithms. Therefore, it makes sense to colorize the nighttime TIR images by translating them into the corresponding daytime color images (NTIR2DC). Despite the impressive progress made in the NTIR2DC task, how to improve the translation performance of small object classes is under-explored. To address this problem, we propose a generative adversarial network incorporating feedback-based object appearance learning (FoalGAN). Specifically, an occlusion-aware mixup module and corresponding appearance consistency loss are proposed to reduce the context dependence of object translation. As a representative example of small objects in nighttime street scenes, we illustrate how to enhance the realism of traffic light by designing a traffic light appearance loss. To further improve the appearance learning of small objects, we devise a dual feedback learning strategy to selectively adjust the learning frequency of different samples. In addition, we provide pixel-level annotation for a subset of the Brno dataset, which can facilitate the research of NTIR image understanding under multiple weather conditions. Extensive experiments illustrate that the proposed FoalGAN is not only effective for appearance learning of small objects, but also outperforms other image translation methods in terms of semantic preservation and edge consistency for the NTIR2DC task.
Weakly-supervised Micro- and Macro-expression Spotting Based on Multi-level Consistency
May 04, 2023



Most micro- and macro-expression spotting methods in untrimmed videos suffer from the burden of video-wise collection and frame-wise annotation. Weakly-supervised expression spotting (WES) based on video-level labels can potentially mitigate the complexity of frame-level annotation while achieving fine-grained frame-level spotting. However, we argue that existing weakly-supervised methods are based on multiple instance learning (MIL) involving inter-modality, inter-sample, and inter-task gaps. The inter-sample gap is primarily from the sample distribution and duration. Therefore, we propose a novel and simple WES framework, MC-WES, using multi-consistency collaborative mechanisms that include modal-level saliency, video-level distribution, label-level duration and segment-level feature consistency strategies to implement fine frame-level spotting with only video-level labels to alleviate the above gaps and merge prior knowledge. The modal-level saliency consistency strategy focuses on capturing key correlations between raw images and optical flow. The video-level distribution consistency strategy utilizes the difference of sparsity in temporal distribution. The label-level duration consistency strategy exploits the difference in the duration of facial muscles. The segment-level feature consistency strategy emphasizes that features under the same labels maintain similarity. Experimental results on two challenging datasets -- CAS(ME)$^2$ and SAMM-LV -- demonstrate that MC-WES is comparable to state-of-the-art fully-supervised methods.
Memory-Guided Collaborative Attention for Nighttime Thermal Infrared Image Colorization
Aug 05, 2022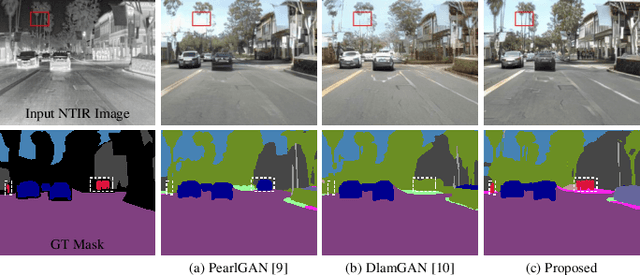
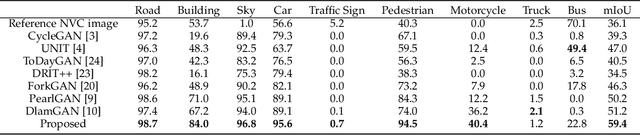
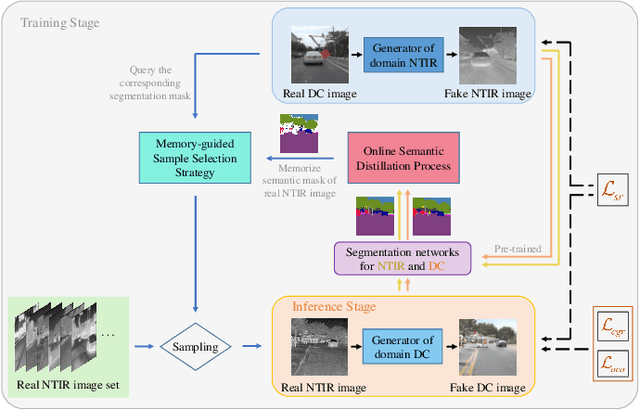
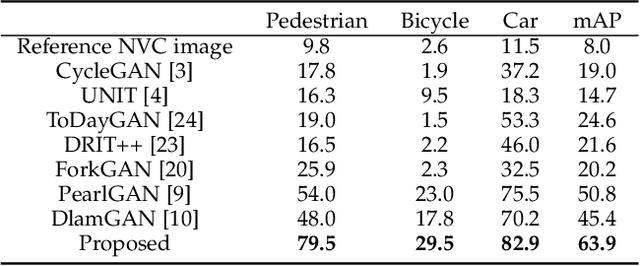
Nighttime thermal infrared (NTIR) image colorization, also known as translation of NTIR images into daytime color images (NTIR2DC), is a promising research direction to facilitate nighttime scene perception for humans and intelligent systems under unfavorable conditions (e.g., complete darkness). However, previously developed methods have poor colorization performance for small sample classes. Moreover, reducing the high confidence noise in pseudo-labels and addressing the problem of image gradient disappearance during translation are still under-explored, and keeping edges from being distorted during translation is also challenging. To address the aforementioned issues, we propose a novel learning framework called Memory-guided cOllaboRative atteNtion Generative Adversarial Network (MornGAN), which is inspired by the analogical reasoning mechanisms of humans. Specifically, a memory-guided sample selection strategy and adaptive collaborative attention loss are devised to enhance the semantic preservation of small sample categories. In addition, we propose an online semantic distillation module to mine and refine the pseudo-labels of NTIR images. Further, conditional gradient repair loss is introduced for reducing edge distortion during translation. Extensive experiments on the NTIR2DC task show that the proposed MornGAN significantly outperforms other image-to-image translation methods in terms of semantic preservation and edge consistency, which helps improve the object detection accuracy remarkably.
Learning to Adapt to Light
Feb 16, 2022
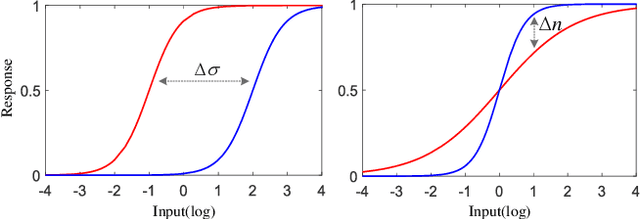
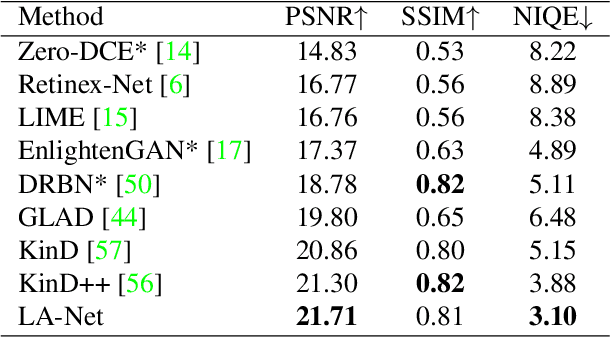
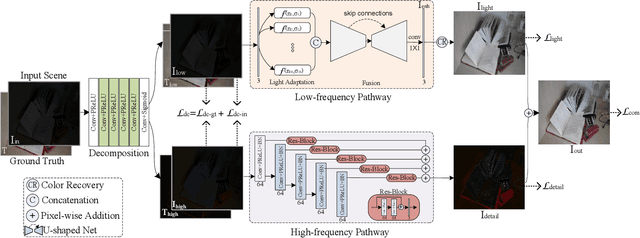
Light adaptation or brightness correction is a key step in improving the contrast and visual appeal of an image. There are multiple light-related tasks (for example, low-light enhancement and exposure correction) and previous studies have mainly investigated these tasks individually. However, it is interesting to consider whether these light-related tasks can be executed by a unified model, especially considering that our visual system adapts to external light in such way. In this study, we propose a biologically inspired method to handle light-related image-enhancement tasks with a unified network (called LA-Net). First, a frequency-based decomposition module is designed to decouple the common and characteristic sub-problems of light-related tasks into two pathways. Then, a new module is built inspired by biological visual adaptation to achieve unified light adaptation in the low-frequency pathway. In addition, noise suppression or detail enhancement is achieved effectively in the high-frequency pathway regardless of the light levels. Extensive experiments on three tasks -- low-light enhancement, exposure correction, and tone mapping -- demonstrate that the proposed method almost obtains state-of-the-art performance compared with recent methods designed for these individual tasks.