 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeak Supervision with Arbitrary Single Frame for Micro- and Macro-expression Spotting
Mar 21, 2024



Frame-level micro- and macro-expression spotting methods require time-consuming frame-by-frame observation during annotation. Meanwhile, video-level spotting lacks sufficient information about the location and number of expressions during training, resulting in significantly inferior performance compared with fully-supervised spotting. To bridge this gap, we propose a point-level weakly-supervised expression spotting (PWES) framework, where each expression requires to be annotated with only one random frame (i.e., a point). To mitigate the issue of sparse label distribution, the prevailing solution is pseudo-label mining, which, however, introduces new problems: localizing contextual background snippets results in inaccurate boundaries and discarding foreground snippets leads to fragmentary predictions. Therefore, we design the strategies of multi-refined pseudo label generation (MPLG) and distribution-guided feature contrastive learning (DFCL) to address these problems. Specifically, MPLG generates more reliable pseudo labels by merging class-specific probabilities, attention scores, fused features, and point-level labels. DFCL is utilized to enhance feature similarity for the same categories and feature variability for different categories while capturing global representations across the entire datasets. Extensive experiments on the CAS(ME)^2, CAS(ME)^3, and SAMM-LV datasets demonstrate PWES achieves promising performance comparable to that of recent fully-supervised methods.
Nighttime Thermal Infrared Image Colorization with Feedback-based Object Appearance Learning
Oct 24, 2023


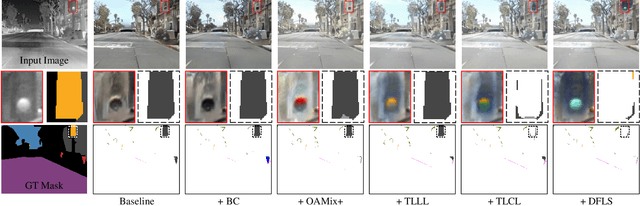
Stable imaging in adverse environments (e.g., total darkness) makes thermal infrared (TIR) cameras a prevalent option for night scene perception. However, the low contrast and lack of chromaticity of TIR images are detrimental to human interpretation and subsequent deployment of RGB-based vision algorithms. Therefore, it makes sense to colorize the nighttime TIR images by translating them into the corresponding daytime color images (NTIR2DC). Despite the impressive progress made in the NTIR2DC task, how to improve the translation performance of small object classes is under-explored. To address this problem, we propose a generative adversarial network incorporating feedback-based object appearance learning (FoalGAN). Specifically, an occlusion-aware mixup module and corresponding appearance consistency loss are proposed to reduce the context dependence of object translation. As a representative example of small objects in nighttime street scenes, we illustrate how to enhance the realism of traffic light by designing a traffic light appearance loss. To further improve the appearance learning of small objects, we devise a dual feedback learning strategy to selectively adjust the learning frequency of different samples. In addition, we provide pixel-level annotation for a subset of the Brno dataset, which can facilitate the research of NTIR image understanding under multiple weather conditions. Extensive experiments illustrate that the proposed FoalGAN is not only effective for appearance learning of small objects, but also outperforms other image translation methods in terms of semantic preservation and edge consistency for the NTIR2DC task.
Memory-Guided Collaborative Attention for Nighttime Thermal Infrared Image Colorization
Aug 05, 2022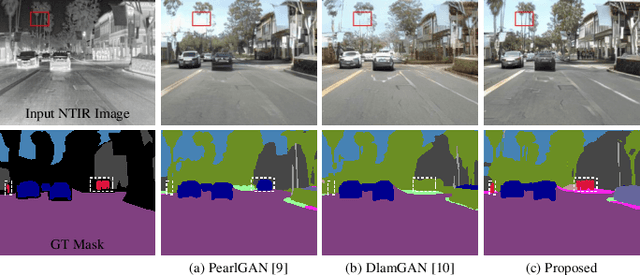
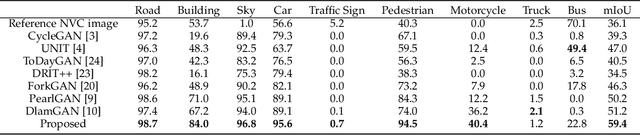
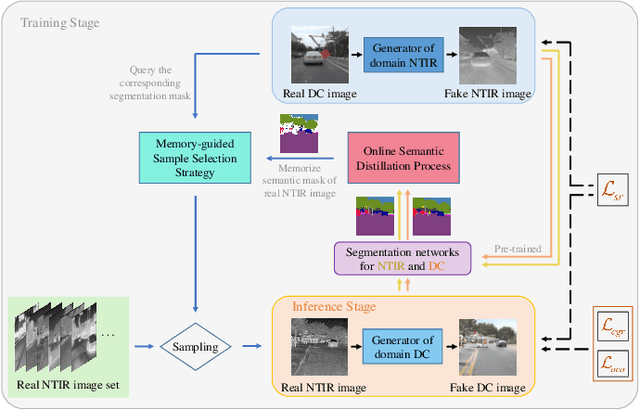
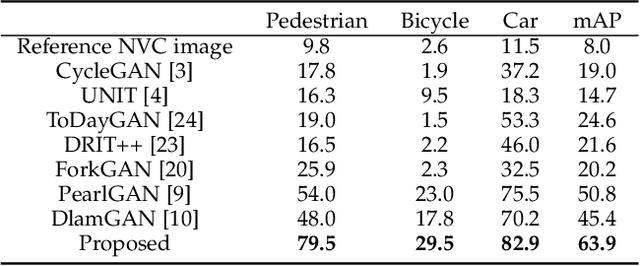
Nighttime thermal infrared (NTIR) image colorization, also known as translation of NTIR images into daytime color images (NTIR2DC), is a promising research direction to facilitate nighttime scene perception for humans and intelligent systems under unfavorable conditions (e.g., complete darkness). However, previously developed methods have poor colorization performance for small sample classes. Moreover, reducing the high confidence noise in pseudo-labels and addressing the problem of image gradient disappearance during translation are still under-explored, and keeping edges from being distorted during translation is also challenging. To address the aforementioned issues, we propose a novel learning framework called Memory-guided cOllaboRative atteNtion Generative Adversarial Network (MornGAN), which is inspired by the analogical reasoning mechanisms of humans. Specifically, a memory-guided sample selection strategy and adaptive collaborative attention loss are devised to enhance the semantic preservation of small sample categories. In addition, we propose an online semantic distillation module to mine and refine the pseudo-labels of NTIR images. Further, conditional gradient repair loss is introduced for reducing edge distortion during translation. Extensive experiments on the NTIR2DC task show that the proposed MornGAN significantly outperforms other image-to-image translation methods in terms of semantic preservation and edge consistency, which helps improve the object detection accuracy remarkably.