 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying and Correcting Label Noise for Robust GNNs via Influence Contradiction
Jan 24, 2026Graph Neural Networks (GNNs) have shown remarkable capabilities in learning from graph-structured data with various applications such as social analysis and bioinformatics. However, the presence of label noise in real scenarios poses a significant challenge in learning robust GNNs, and their effectiveness can be severely impacted when dealing with noisy labels on graphs, often stemming from annotation errors or inconsistencies. To address this, in this paper we propose a novel approach called ICGNN that harnesses the structure information of the graph to effectively alleviate the challenges posed by noisy labels. Specifically, we first design a novel noise indicator that measures the influence contradiction score (ICS) based on the graph diffusion matrix to quantify the credibility of nodes with clean labels, such that nodes with higher ICS values are more likely to be detected as having noisy labels. Then we leverage the Gaussian mixture model to precisely detect whether the label of a node is noisy or not. Additionally, we develop a soft strategy to combine the predictions from neighboring nodes on the graph to correct the detected noisy labels. At last, pseudo-labeling for abundant unlabeled nodes is incorporated to provide auxiliary supervision signals and guide the model optimization. Experiments on benchmark datasets show the superiority of our proposed approach.
DeepEra: A Deep Evidence Reranking Agent for Scientific Retrieval-Augmented Generated Question Answering
Jan 23, 2026With the rapid growth of scientific literature, scientific question answering (SciQA) has become increasingly critical for exploring and utilizing scientific knowledge. Retrieval-Augmented Generation (RAG) enhances LLMs by incorporating knowledge from external sources, thereby providing credible evidence for scientific question answering. But existing retrieval and reranking methods remain vulnerable to passages that are semantically similar but logically irrelevant, often reducing factual reliability and amplifying hallucinations.To address this challenge, we propose a Deep Evidence Reranking Agent (DeepEra) that integrates step-by-step reasoning, enabling more precise evaluation of candidate passages beyond surface-level semantics. To support systematic evaluation, we construct SciRAG-SSLI (Scientific RAG - Semantically Similar but Logically Irrelevant), a large-scale dataset comprising about 300K SciQA instances across 10 subjects, constructed from 10M scientific corpus. The dataset combines naturally retrieved contexts with systematically generated distractors to test logical robustness and factual grounding. Comprehensive evaluations confirm that our approach achieves superior retrieval performance compared to leading rerankers. To our knowledge, this work is the first to comprehensively study and empirically validate innegligible SSLI issues in two-stage RAG frameworks.
A Survey on Efficient Large Language Model Training: From Data-centric Perspectives
Oct 29, 2025Post-training of Large Language Models (LLMs) is crucial for unlocking their task generalization potential and domain-specific capabilities. However, the current LLM post-training paradigm faces significant data challenges, including the high costs of manual annotation and diminishing marginal returns on data scales. Therefore, achieving data-efficient post-training has become a key research question. In this paper, we present the first systematic survey of data-efficient LLM post-training from a data-centric perspective. We propose a taxonomy of data-efficient LLM post-training methods, covering data selection, data quality enhancement, synthetic data generation, data distillation and compression, and self-evolving data ecosystems. We summarize representative approaches in each category and outline future research directions. By examining the challenges in data-efficient LLM post-training, we highlight open problems and propose potential research avenues. We hope our work inspires further exploration into maximizing the potential of data utilization in large-scale model training. Paper List: https://github.com/luo-junyu/Awesome-Data-Efficient-LLM
SciRerankBench: Benchmarking Rerankers Towards Scientific Retrieval-Augmented Generated LLMs
Aug 12, 2025Scientific literature question answering is a pivotal step towards new scientific discoveries. Recently, \textit{two-stage} retrieval-augmented generated large language models (RAG-LLMs) have shown impressive advancements in this domain. Such a two-stage framework, especially the second stage (reranker), is particularly essential in the scientific domain, where subtle differences in terminology may have a greatly negative impact on the final factual-oriented or knowledge-intensive answers. Despite this significant progress, the potential and limitations of these works remain unexplored. In this work, we present a Scientific Rerank-oriented RAG Benchmark (SciRerankBench), for evaluating rerankers within RAG-LLMs systems, spanning five scientific subjects. To rigorously assess the reranker performance in terms of noise resilience, relevance disambiguation, and factual consistency, we develop three types of question-context-answer (Q-C-A) pairs, i.e., Noisy Contexts (NC), Semantically Similar but Logically Irrelevant Contexts (SSLI), and Counterfactual Contexts (CC). Through systematic evaluation of 13 widely used rerankers on five families of LLMs, we provide detailed insights into their relative strengths and limitations. To the best of our knowledge, SciRerankBench is the first benchmark specifically developed to evaluate rerankers within RAG-LLMs, which provides valuable observations and guidance for their future development.
Sparse Causal Discovery with Generative Intervention for Unsupervised Graph Domain Adaptation
Jul 10, 2025Unsupervised Graph Domain Adaptation (UGDA) leverages labeled source domain graphs to achieve effective performance in unlabeled target domains despite distribution shifts. However, existing methods often yield suboptimal results due to the entanglement of causal-spurious features and the failure of global alignment strategies. We propose SLOGAN (Sparse Causal Discovery with Generative Intervention), a novel approach that achieves stable graph representation transfer through sparse causal modeling and dynamic intervention mechanisms. Specifically, SLOGAN first constructs a sparse causal graph structure, leveraging mutual information bottleneck constraints to disentangle sparse, stable causal features while compressing domain-dependent spurious correlations through variational inference. To address residual spurious correlations, we innovatively design a generative intervention mechanism that breaks local spurious couplings through cross-domain feature recombination while maintaining causal feature semantic consistency via covariance constraints. Furthermore, to mitigate error accumulation in target domain pseudo-labels, we introduce a category-adaptive dynamic calibration strategy, ensuring stable discriminative learning. Extensive experiments on multiple real-world datasets demonstrate that SLOGAN significantly outperforms existing baselines.
Dynamic Text Bundling Supervision for Zero-Shot Inference on Text-Attributed Graphs
May 23, 2025Large language models (LLMs) have been used in many zero-shot learning problems, with their strong generalization ability. Recently, adopting LLMs in text-attributed graphs (TAGs) has drawn increasing attention. However, the adoption of LLMs faces two major challenges: limited information on graph structure and unreliable responses. LLMs struggle with text attributes isolated from the graph topology. Worse still, they yield unreliable predictions due to both information insufficiency and the inherent weakness of LLMs (e.g., hallucination). Towards this end, this paper proposes a novel method named Dynamic Text Bundling Supervision (DENSE) that queries LLMs with bundles of texts to obtain bundle-level labels and uses these labels to supervise graph neural networks. Specifically, we sample a set of bundles, each containing a set of nodes with corresponding texts of close proximity. We then query LLMs with the bundled texts to obtain the label of each bundle. Subsequently, the bundle labels are used to supervise the optimization of graph neural networks, and the bundles are further refined to exclude noisy items. To justify our design, we also provide theoretical analysis of the proposed method. Extensive experiments across ten datasets validate the effectiveness of the proposed method.
MARCO: Meta-Reflection with Cross-Referencing for Code Reasoning
May 23, 2025The ability to reason is one of the most fundamental capabilities of large language models (LLMs), enabling a wide range of downstream tasks through sophisticated problem-solving. A critical aspect of this is code reasoning, which involves logical reasoning with formal languages (i.e., programming code). In this paper, we enhance this capability of LLMs by exploring the following question: how can an LLM agent become progressively smarter in code reasoning with each solution it proposes, thereby achieving substantial cumulative improvement? Most existing research takes a static perspective, focusing on isolated problem-solving using frozen LLMs. In contrast, we adopt a cognitive-evolving perspective and propose a novel framework named Meta-Reflection with Cross-Referencing (MARCO) that enables the LLM to evolve dynamically during inference through self-improvement. From the perspective of human cognitive development, we leverage both knowledge accumulation and lesson sharing. In particular, to accumulate knowledge during problem-solving, we propose meta-reflection that reflects on the reasoning paths of the current problem to obtain knowledge and experience for future consideration. Moreover, to effectively utilize the lessons from other agents, we propose cross-referencing that incorporates the solution and feedback from other agents into the current problem-solving process. We conduct experiments across various datasets in code reasoning, and the results demonstrate the effectiveness of MARCO.
Cross-Domain Diffusion with Progressive Alignment for Efficient Adaptive Retrieval
May 20, 2025Unsupervised efficient domain adaptive retrieval aims to transfer knowledge from a labeled source domain to an unlabeled target domain, while maintaining low storage cost and high retrieval efficiency. However, existing methods typically fail to address potential noise in the target domain, and directly align high-level features across domains, thus resulting in suboptimal retrieval performance. To address these challenges, we propose a novel Cross-Domain Diffusion with Progressive Alignment method (COUPLE). This approach revisits unsupervised efficient domain adaptive retrieval from a graph diffusion perspective, simulating cross-domain adaptation dynamics to achieve a stable target domain adaptation process. First, we construct a cross-domain relationship graph and leverage noise-robust graph flow diffusion to simulate the transfer dynamics from the source domain to the target domain, identifying lower noise clusters. We then leverage the graph diffusion results for discriminative hash code learning, effectively learning from the target domain while reducing the negative impact of noise. Furthermore, we employ a hierarchical Mixup operation for progressive domain alignment, which is performed along the cross-domain random walk paths. Utilizing target domain discriminative hash learning and progressive domain alignment, COUPLE enables effective domain adaptive hash learning. Extensive experiments demonstrate COUPLE's effectiveness on competitive benchmarks.
* IEEE TIP
Memory-Augmented Dual-Decoder Networks for Multi-Class Unsupervised Anomaly Detection
Apr 21, 2025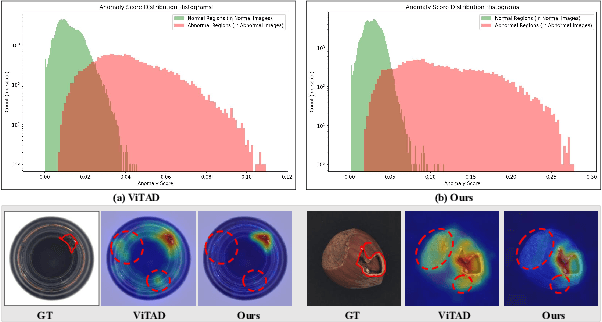
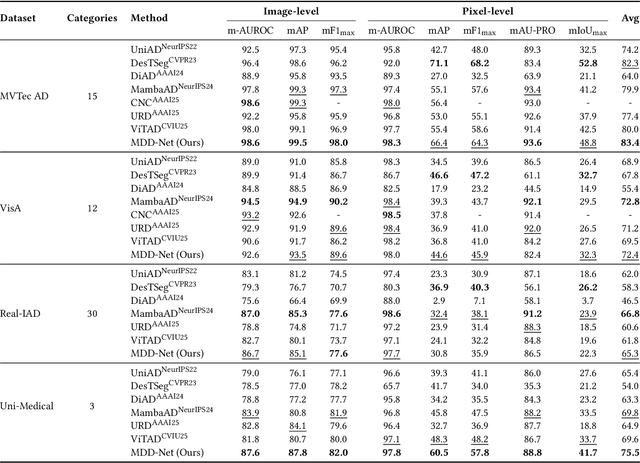
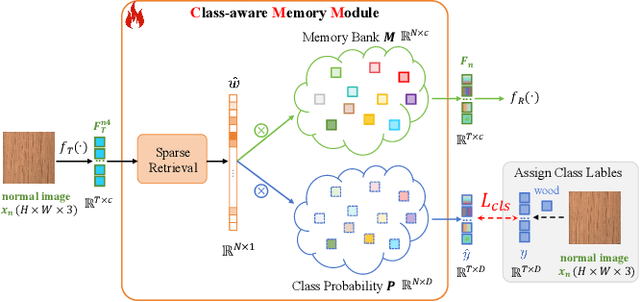
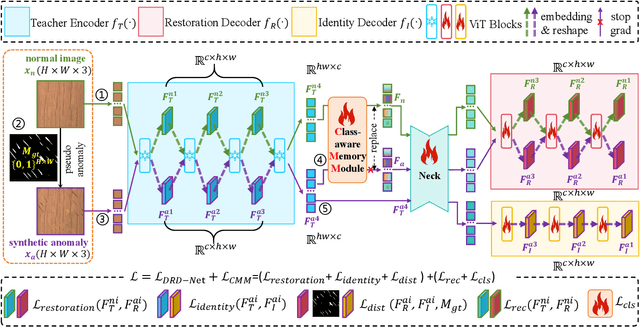
Recent advances in unsupervised anomaly detection (UAD) have shifted from single-class to multi-class scenarios. In such complex contexts, the increasing pattern diversity has brought two challenges to reconstruction-based approaches: (1) over-generalization: anomalies that are subtle or share compositional similarities with normal patterns may be reconstructed with high fidelity, making them difficult to distinguish from normal instances; and (2) insufficient normality reconstruction: complex normal features, such as intricate textures or fine-grained structures, may not be faithfully reconstructed due to the model's limited representational capacity, resulting in false positives. Existing methods typically focus on addressing the former, which unintentionally exacerbate the latter, resulting in inadequate representation of intricate normal patterns. To concurrently address these two challenges, we propose a Memory-augmented Dual-Decoder Networks (MDD-Net). This network includes two critical components: a Dual-Decoder Reverse Distillation Network (DRD-Net) and a Class-aware Memory Module (CMM). Specifically, the DRD-Net incorporates a restoration decoder designed to recover normal features from synthetic abnormal inputs and an identity decoder to reconstruct features that maintain the anomalous semantics. By exploiting the discrepancy between features produced by two decoders, our approach refines anomaly scores beyond the conventional encoder-decoder comparison paradigm, effectively reducing false positives and enhancing localization accuracy. Furthermore, the CMM explicitly encodes and preserves class-specific normal prototypes, actively steering the network away from anomaly reconstruction. Comprehensive experimental results across several benchmarks demonstrate the superior performance of our MDD-Net framework over current SoTA approaches in multi-class UAD tasks.
Large Language Model Agent: A Survey on Methodology, Applications and Challenges
Mar 27, 2025The era of intelligent agents is upon us, driven by revolutionary advancements in large language models. Large Language Model (LLM) agents, with goal-driven behaviors and dynamic adaptation capabilities, potentially represent a critical pathway toward artificial general intelligence. This survey systematically deconstructs LLM agent systems through a methodology-centered taxonomy, linking architectural foundations, collaboration mechanisms, and evolutionary pathways. We unify fragmented research threads by revealing fundamental connections between agent design principles and their emergent behaviors in complex environments. Our work provides a unified architectural perspective, examining how agents are constructed, how they collaborate, and how they evolve over time, while also addressing evaluation methodologies, tool applications, practical challenges, and diverse application domains. By surveying the latest developments in this rapidly evolving field, we offer researchers a structured taxonomy for understanding LLM agents and identify promising directions for future research. The collection is available at https://github.com/luo-junyu/Awesome-Agent-Papers.