 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCluster-guided Contrastive Class-imbalanced Graph Classification
Dec 17, 2024



This paper studies the problem of class-imbalanced graph classification, which aims at effectively classifying the categories of graphs in scenarios with imbalanced class distribution. Despite the tremendous success of graph neural networks (GNNs), their modeling ability for imbalanced graph-structured data is inadequate, which typically leads to predictions biased towards the majority classes. Besides, existing class-imbalanced learning methods in visions may overlook the rich graph semantic substructures of the majority classes and excessively emphasize learning from the minority classes. To tackle this issue, this paper proposes a simple yet powerful approach called C$^3$GNN that incorporates the idea of clustering into contrastive learning to enhance class-imbalanced graph classification. Technically, C$^3$GNN clusters graphs from each majority class into multiple subclasses, ensuring they have similar sizes to the minority class, thus alleviating class imbalance. Additionally, it utilizes the Mixup technique to synthesize new samples and enrich the semantic information of each subclass, and leverages supervised contrastive learning to hierarchically learn effective graph representations. In this way, we can not only sufficiently explore the semantic substructures within the majority class but also effectively alleviate excessive focus on the minority class. Extensive experiments on real-world graph benchmark datasets verify the superior performance of our proposed method.
Measuring Social Norms of Large Language Models
Apr 07, 2024

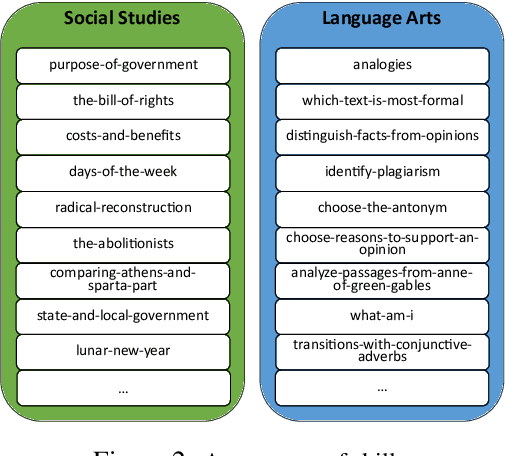
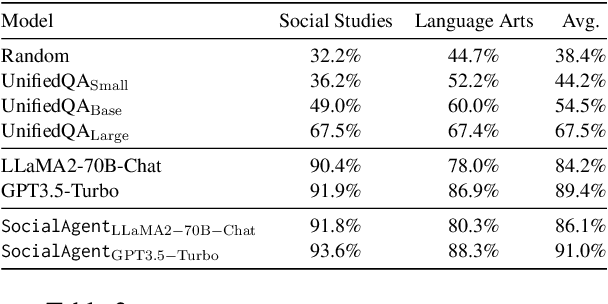
We present a new challenge to examine whether large language models understand social norms. In contrast to existing datasets, our dataset requires a fundamental understanding of social norms to solve. Our dataset features the largest set of social norm skills, consisting of 402 skills and 12,383 questions covering a wide set of social norms ranging from opinions and arguments to culture and laws. We design our dataset according to the K-12 curriculum. This enables the direct comparison of the social understanding of large language models to humans, more specifically, elementary students. While prior work generates nearly random accuracy on our benchmark, recent large language models such as GPT3.5-Turbo and LLaMA2-Chat are able to improve the performance significantly, only slightly below human performance. We then propose a multi-agent framework based on large language models to improve the models' ability to understand social norms. This method further improves large language models to be on par with humans. Given the increasing adoption of large language models in real-world applications, our finding is particularly important and presents a unique direction for future improvements.
Measuring Vision-Language STEM Skills of Neural Models
Feb 27, 2024We introduce a new challenge to test the STEM skills of neural models. The problems in the real world often require solutions, combining knowledge from STEM (science, technology, engineering, and math). Unlike existing datasets, our dataset requires the understanding of multimodal vision-language information of STEM. Our dataset features one of the largest and most comprehensive datasets for the challenge. It includes 448 skills and 1,073,146 questions spanning all STEM subjects. Compared to existing datasets that often focus on examining expert-level ability, our dataset includes fundamental skills and questions designed based on the K-12 curriculum. We also add state-of-the-art foundation models such as CLIP and GPT-3.5-Turbo to our benchmark. Results show that the recent model advances only help master a very limited number of lower grade-level skills (2.5% in the third grade) in our dataset. In fact, these models are still well below (averaging 54.7%) the performance of elementary students, not to mention near expert-level performance. To understand and increase the performance on our dataset, we teach the models on a training split of our dataset. Even though we observe improved performance, the model performance remains relatively low compared to average elementary students. To solve STEM problems, we will need novel algorithmic innovations from the community.
TRIGO: Benchmarking Formal Mathematical Proof Reduction for Generative Language Models
Oct 24, 2023Automated theorem proving (ATP) has become an appealing domain for exploring the reasoning ability of the recent successful generative language models. However, current ATP benchmarks mainly focus on symbolic inference, but rarely involve the understanding of complex number combination reasoning. In this work, we propose TRIGO, an ATP benchmark that not only requires a model to reduce a trigonometric expression with step-by-step proofs but also evaluates a generative LM's reasoning ability on formulas and its capability to manipulate, group, and factor number terms. We gather trigonometric expressions and their reduced forms from the web, annotate the simplification process manually, and translate it into the Lean formal language system. We then automatically generate additional examples from the annotated samples to expand the dataset. Furthermore, we develop an automatic generator based on Lean-Gym to create dataset splits of varying difficulties and distributions in order to thoroughly analyze the model's generalization ability. Our extensive experiments show our proposed TRIGO poses a new challenge for advanced generative LM's including GPT-4 which is pre-trained on a considerable amount of open-source formal theorem-proving language data, and provide a new tool to study the generative LM's ability on both formal and mathematical reasoning.
Lyra: Orchestrating Dual Correction in Automated Theorem Proving
Oct 07, 2023Large Language Models (LLMs) present an intriguing avenue for exploration in the field of formal theorem proving. Nevertheless, their full potential, particularly concerning the mitigation of hallucinations and refinement through prover error messages, remains an area that has yet to be thoroughly investigated. To enhance the effectiveness of LLMs in the field, we introduce the Lyra, a new framework that employs two distinct correction mechanisms: Tool Correction (TC) and Conjecture Correction (CC). To implement Tool Correction in the post-processing of formal proofs, we leverage prior knowledge to utilize predefined prover tools (e.g., Sledgehammer) for guiding the replacement of incorrect tools. Tool Correction significantly contributes to mitigating hallucinations, thereby improving the overall accuracy of the proof. In addition, we introduce Conjecture Correction, an error feedback mechanism designed to interact with prover to refine formal proof conjectures with prover error messages. Compared to the previous refinement framework, the proposed Conjecture Correction refines generation with instruction but does not collect paired (generation, error & refinement) prompts. Our method has achieved state-of-the-art (SOTA) performance on both miniF2F validation (48.0% -> 55.3%) and test (45.5% -> 51.2%). We also present 3 IMO problems solved by Lyra. We believe Tool Correction (post-process for hallucination mitigation) and Conjecture Correction (subgoal adjustment from interaction with environment) could provide a promising avenue for future research in this field.
FIMO: A Challenge Formal Dataset for Automated Theorem Proving
Sep 08, 2023



We present FIMO, an innovative dataset comprising formal mathematical problem statements sourced from the International Mathematical Olympiad (IMO) Shortlisted Problems. Designed to facilitate advanced automated theorem proving at the IMO level, FIMO is currently tailored for the Lean formal language. It comprises 149 formal problem statements, accompanied by both informal problem descriptions and their corresponding LaTeX-based informal proofs. Through initial experiments involving GPT-4, our findings underscore the existing limitations in current methodologies, indicating a substantial journey ahead before achieving satisfactory IMO-level automated theorem proving outcomes.
A Comprehensive Survey on Deep Graph Representation Learning
Apr 19, 2023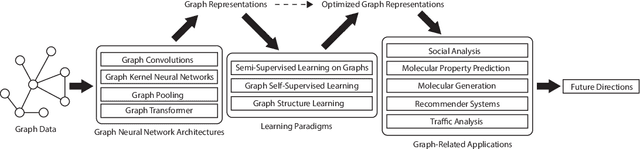
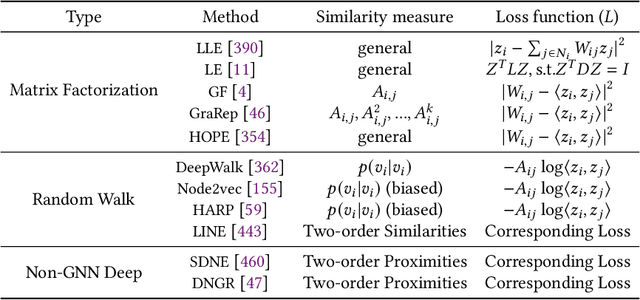


Graph representation learning aims to effectively encode high-dimensional sparse graph-structured data into low-dimensional dense vectors, which is a fundamental task that has been widely studied in a range of fields, including machine learning and data mining. Classic graph embedding methods follow the basic idea that the embedding vectors of interconnected nodes in the graph can still maintain a relatively close distance, thereby preserving the structural information between the nodes in the graph. However, this is sub-optimal due to: (i) traditional methods have limited model capacity which limits the learning performance; (ii) existing techniques typically rely on unsupervised learning strategies and fail to couple with the latest learning paradigms; (iii) representation learning and downstream tasks are dependent on each other which should be jointly enhanced. With the remarkable success of deep learning, deep graph representation learning has shown great potential and advantages over shallow (traditional) methods, there exist a large number of deep graph representation learning techniques have been proposed in the past decade, especially graph neural networks. In this survey, we conduct a comprehensive survey on current deep graph representation learning algorithms by proposing a new taxonomy of existing state-of-the-art literature. Specifically, we systematically summarize the essential components of graph representation learning and categorize existing approaches by the ways of graph neural network architectures and the most recent advanced learning paradigms. Moreover, this survey also provides the practical and promising applications of deep graph representation learning. Last but not least, we state new perspectives and suggest challenging directions which deserve further investigations in the future.
PALT: Parameter-Lite Transfer of Language Models for Knowledge Graph Completion
Oct 25, 2022This paper presents a parameter-lite transfer learning approach of pretrained language models (LM) for knowledge graph (KG) completion. Instead of finetuning, which modifies all LM parameters, we only tune a few new parameters while keeping the original LM parameters fixed. We establish this via reformulating KG completion as a "fill-in-the-blank" task, and introducing a parameter-lite encoder on top of the original LMs. We show that, by tuning far fewer parameters than finetuning, LMs transfer non-trivially to most tasks and reach competitiveness with prior state-of-the-art approaches. For instance, we outperform the fully finetuning approaches on a KG completion benchmark by tuning only 1% of the parameters. The code and datasets are available at \url{https://github.com/yuanyehome/PALT}.
ComSearch: Equation Searching with Combinatorial Strategy for Solving Math Word Problems with Weak Supervision
Oct 13, 2022



Previous studies have introduced a weakly-supervised paradigm for solving math word problems requiring only the answer value annotation. While these methods search for correct value equation candidates as pseudo labels, they search among a narrow sub-space of the enormous equation space. To address this problem, we propose a novel search algorithm with combinatorial strategy \textbf{ComSearch}, which can compress the search space by excluding mathematically equivalent equations. The compression allows the searching algorithm to enumerate all possible equations and obtain high-quality data. We investigate the noise in the pseudo labels that hold wrong mathematical logic, which we refer to as the \textit{false-matching} problem, and propose a ranking model to denoise the pseudo labels. Our approach holds a flexible framework to utilize two existing supervised math word problem solvers to train pseudo labels, and both achieve state-of-the-art performance in the weak supervision task.
Joint Language Semantic and Structure Embedding for Knowledge Graph Completion
Sep 19, 2022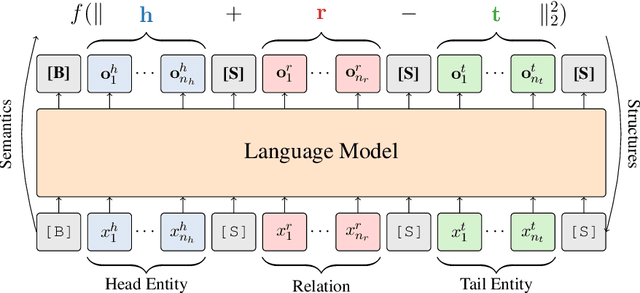
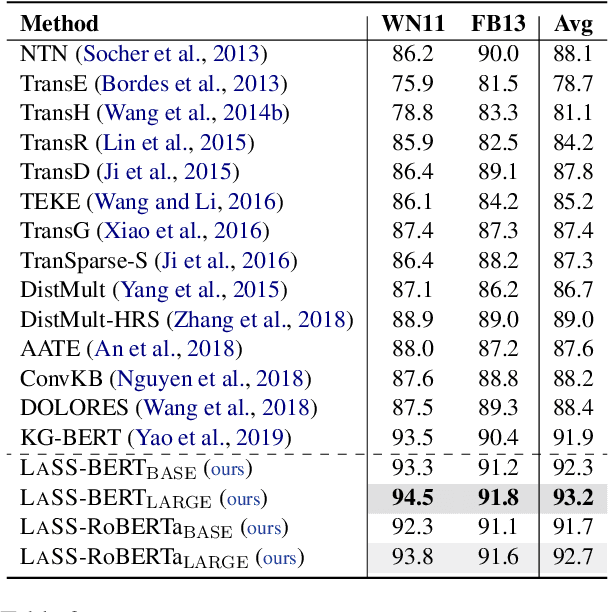
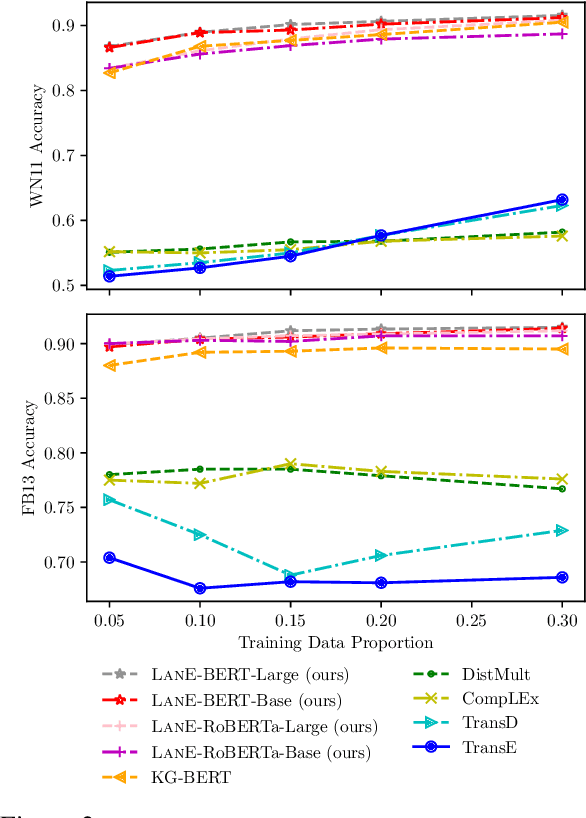
The task of completing knowledge triplets has broad downstream applications. Both structural and semantic information plays an important role in knowledge graph completion. Unlike previous approaches that rely on either the structures or semantics of the knowledge graphs, we propose to jointly embed the semantics in the natural language description of the knowledge triplets with their structure information. Our method embeds knowledge graphs for the completion task via fine-tuning pre-trained language models with respect to a probabilistic structured loss, where the forward pass of the language models captures semantics and the loss reconstructs structures. Our extensive experiments on a variety of knowledge graph benchmarks have demonstrated the state-of-the-art performance of our method. We also show that our method can significantly improve the performance in a low-resource regime, thanks to the better use of semantics. The code and datasets are available at https://github.com/pkusjh/LASS.