 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of LLMs on Syntax-Aware Code Fill-in-the-Middle Tasks
Mar 07, 2024



We introduce Syntax-Aware Fill-In-the-Middle (SAFIM), a new benchmark for evaluating Large Language Models (LLMs) on the code Fill-in-the-Middle (FIM) task. This benchmark focuses on syntax-aware completions of program structures such as code blocks and conditional expressions, and includes 17,720 examples from multiple programming languages, sourced from recent code submissions after April 2022 to minimize data contamination. SAFIM provides a robust framework with various prompt designs and novel syntax-aware post-processing techniques, facilitating accurate and fair comparisons across LLMs. Our comprehensive evaluation of 15 LLMs shows that FIM pretraining not only enhances FIM proficiency but also improves Left-to-Right (L2R) inference using LLMs. Our findings challenge conventional beliefs and suggest that pretraining methods and data quality have more impact than model size. SAFIM thus serves as a foundational platform for future research in effective pretraining strategies for code LLMs. The evaluation toolkit and dataset are available at https://github.com/gonglinyuan/safim, and the leaderboard is available at https://safimbenchmark.com.
AST-T5: Structure-Aware Pretraining for Code Generation and Understanding
Jan 05, 2024



Large language models (LLMs) have made significant advancements in code-related tasks, yet many LLMs treat code as simple sequences, neglecting its structured nature. We introduce AST-T5, a novel pretraining paradigm that leverages the Abstract Syntax Tree (AST) for enhanced code generation, transpilation, and understanding. Using dynamic programming, our AST-Aware Segmentation retains code structure, while our AST-Aware Span Corruption objective equips the model to reconstruct various code structures. Unlike other models, AST-T5 avoids intricate program analyses or architectural changes, so it integrates seamlessly with any encoder-decoder Transformer. Evaluations show that AST-T5 consistently outperforms similar-sized LMs across various code-related tasks. Structure-awareness makes AST-T5 particularly powerful in code-to-code tasks, surpassing CodeT5 by 2 points in exact match score for the Bugs2Fix task and by 3 points in exact match score for Java-C# Transpilation in CodeXGLUE. Our code and model are publicly available at https://github.com/gonglinyuan/ast_t5.
Model-Generated Pretraining Signals Improves Zero-Shot Generalization of Text-to-Text Transformers
May 21, 2023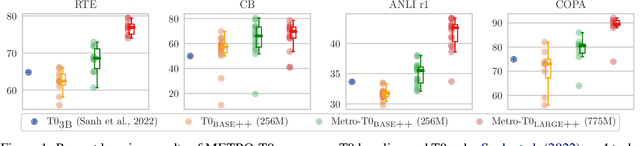

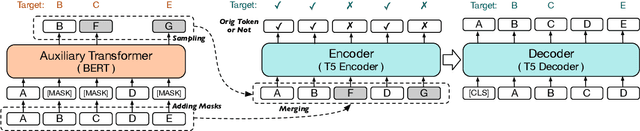
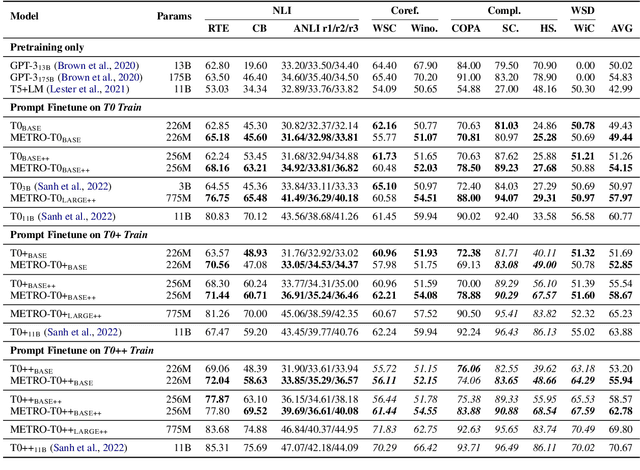
This paper explores the effectiveness of model-generated signals in improving zero-shot generalization of text-to-text Transformers such as T5. We study various designs to pretrain T5 using an auxiliary model to construct more challenging token replacements for the main model to denoise. Key aspects under study include the decoding target, the location of the RTD head, and the masking pattern. Based on these studies, we develop a new model, METRO-T0, which is pretrained using the redesigned ELECTRA-Style pretraining strategies and then prompt-finetuned on a mixture of NLP tasks. METRO-T0 outperforms all similar-sized baselines on prompted NLP benchmarks, such as T0 Eval and MMLU, and rivals the state-of-the-art T0-11B model with only 8% of its parameters. Our analysis on model's neural activation and parameter sensitivity reveals that the effectiveness of METRO-T0 stems from more balanced contribution of parameters and better utilization of their capacity. The code and model checkpoints are available at https://github.com/gonglinyuan/metro_t0.
ADELT: Transpilation Between Deep Learning Frameworks
Mar 07, 2023



We propose Adversarial DEep Learning Transpiler (ADELT) for source-to-source transpilation between deep learning frameworks. Unlike prior approaches, we decouple the transpilation of code skeletons and the mapping of API keywords (an API function name or a parameter name). ADELT transpile code skeletons using few-shot prompting on big language models. Based on contextual embeddings extracted by a BERT for code, we train aligned API embeddings in a domain-adversarial setup, upon which we generate a dictionary for keyword translation. The model is trained on our unlabeled DL corpus from web crawl data, without using any hand-crafted rules and parallel data. Our method outperforms state-of-the-art transpilers on multiple transpilation pairs including PyTorch-Keras and PyTorch-MXNet by 15.9pts and 12.0pts in exact match scores respectively.
Joint Language Semantic and Structure Embedding for Knowledge Graph Completion
Sep 19, 2022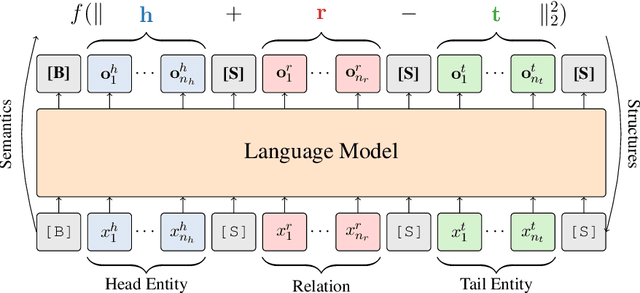
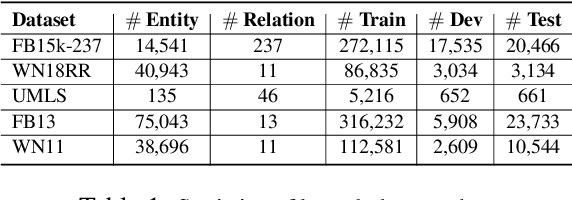
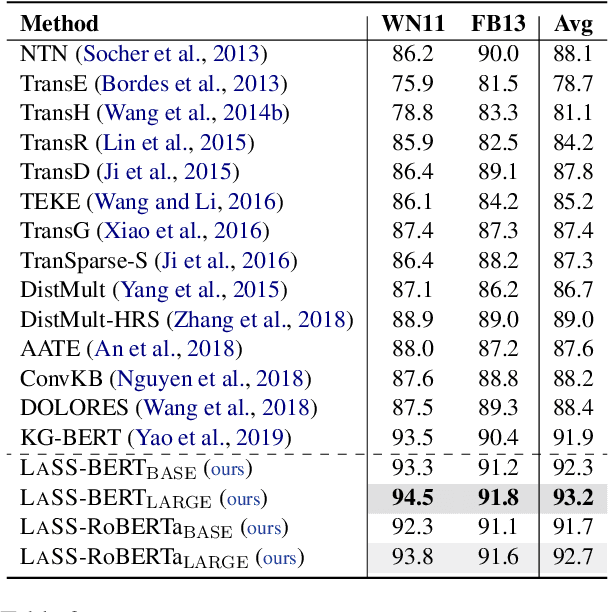
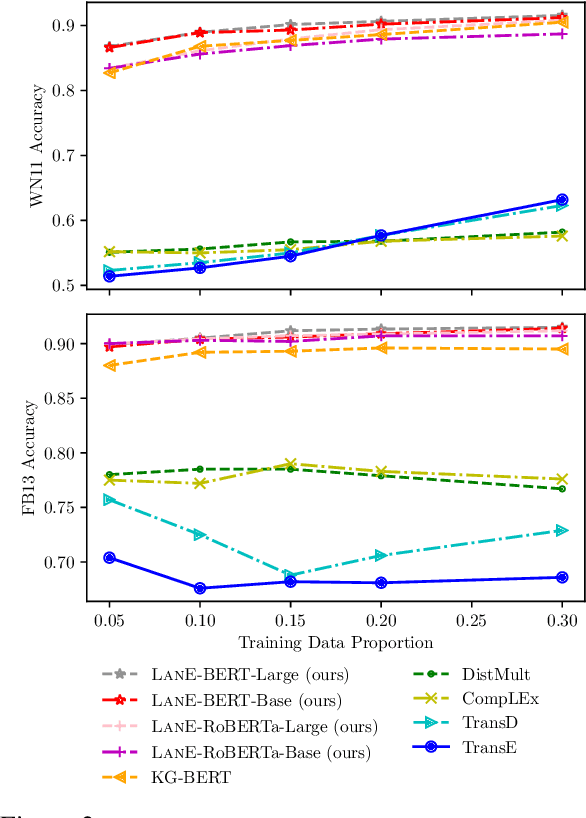
The task of completing knowledge triplets has broad downstream applications. Both structural and semantic information plays an important role in knowledge graph completion. Unlike previous approaches that rely on either the structures or semantics of the knowledge graphs, we propose to jointly embed the semantics in the natural language description of the knowledge triplets with their structure information. Our method embeds knowledge graphs for the completion task via fine-tuning pre-trained language models with respect to a probabilistic structured loss, where the forward pass of the language models captures semantics and the loss reconstructs structures. Our extensive experiments on a variety of knowledge graph benchmarks have demonstrated the state-of-the-art performance of our method. We also show that our method can significantly improve the performance in a low-resource regime, thanks to the better use of semantics. The code and datasets are available at https://github.com/pkusjh/LASS.
Anytime Sampling for Autoregressive Models via Ordered Autoencoding
Feb 23, 2021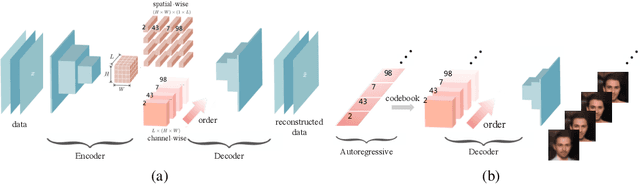

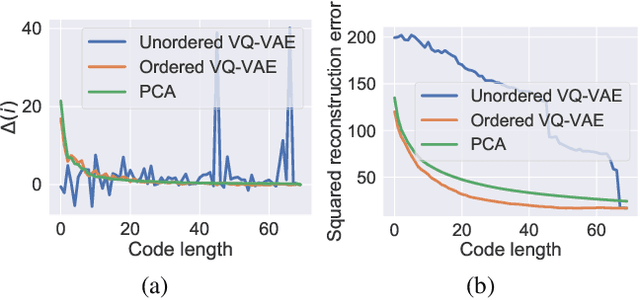
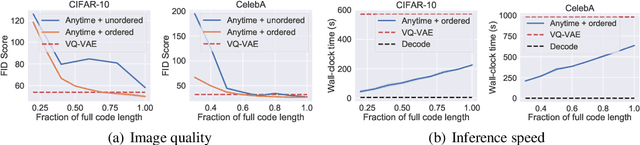
Autoregressive models are widely used for tasks such as image and audio generation. The sampling process of these models, however, does not allow interruptions and cannot adapt to real-time computational resources. This challenge impedes the deployment of powerful autoregressive models, which involve a slow sampling process that is sequential in nature and typically scales linearly with respect to the data dimension. To address this difficulty, we propose a new family of autoregressive models that enables anytime sampling. Inspired by Principal Component Analysis, we learn a structured representation space where dimensions are ordered based on their importance with respect to reconstruction. Using an autoregressive model in this latent space, we trade off sample quality for computational efficiency by truncating the generation process before decoding into the original data space. Experimentally, we demonstrate in several image and audio generation tasks that sample quality degrades gracefully as we reduce the computational budget for sampling. The approach suffers almost no loss in sample quality (measured by FID) using only 60\% to 80\% of all latent dimensions for image data. Code is available at https://github.com/Newbeeer/Anytime-Auto-Regressive-Model .
MC-BERT: Efficient Language Pre-Training via a Meta Controller
Jun 16, 2020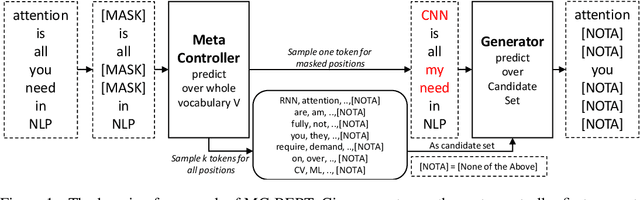

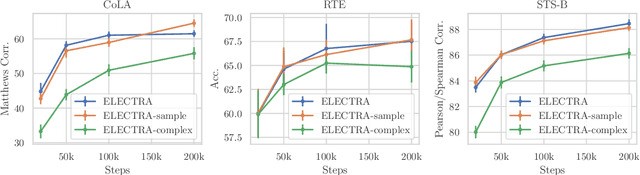

Pre-trained contextual representations (e.g., BERT) have become the foundation to achieve state-of-the-art results on many NLP tasks. However, large-scale pre-training is computationally expensive. ELECTRA, an early attempt to accelerate pre-training, trains a discriminative model that predicts whether each input token was replaced by a generator. Our studies reveal that ELECTRA's success is mainly due to its reduced complexity of the pre-training task: the binary classification (replaced token detection) is more efficient to learn than the generation task (masked language modeling). However, such a simplified task is less semantically informative. To achieve better efficiency and effectiveness, we propose a novel meta-learning framework, MC-BERT. The pre-training task is a multi-choice cloze test with a reject option, where a meta controller network provides training input and candidates. Results over GLUE natural language understanding benchmark demonstrate that our proposed method is both efficient and effective: it outperforms baselines on GLUE semantic tasks given the same computational budget.
Microsoft Research Asia's Systems for WMT19
Nov 07, 2019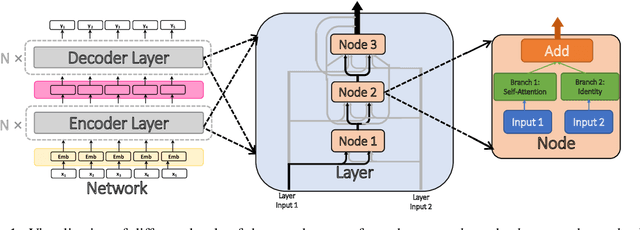

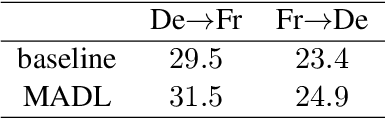
We Microsoft Research Asia made submissions to 11 language directions in the WMT19 news translation tasks. We won the first place for 8 of the 11 directions and the second place for the other three. Our basic systems are built on Transformer, back translation and knowledge distillation. We integrate several of our rececent techniques to enhance the baseline systems: multi-agent dual learning (MADL), masked sequence-to-sequence pre-training (MASS), neural architecture optimization (NAO), and soft contextual data augmentation (SCA).
What Does a TextCNN Learn?
Jan 19, 2018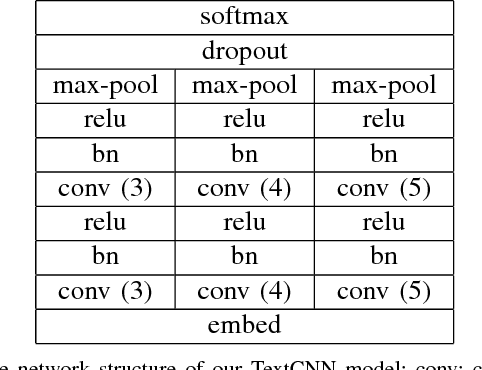
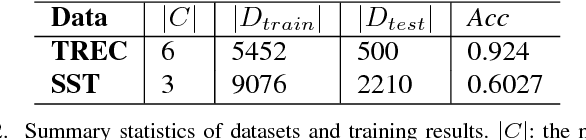
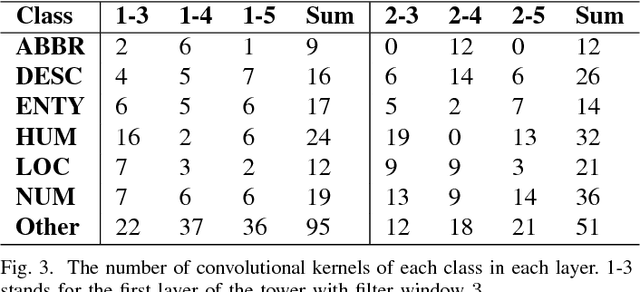

TextCNN, the convolutional neural network for text, is a useful deep learning algorithm for sentence classification tasks such as sentiment analysis and question classification. However, neural networks have long been known as black boxes because interpreting them is a challenging task. Researchers have developed several tools to understand a CNN for image classification by deep visualization, but research about deep TextCNNs is still insufficient. In this paper, we are trying to understand what a TextCNN learns on two classical NLP datasets. Our work focuses on functions of different convolutional kernels and correlations between convolutional kernels.