 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSedentary Behavior Estimation with Hip-worn Accelerometer Data: Segmentation, Classification and Thresholding
Jul 05, 2022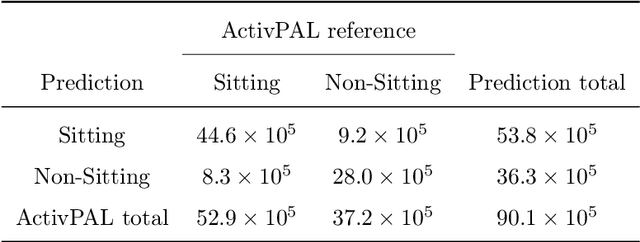
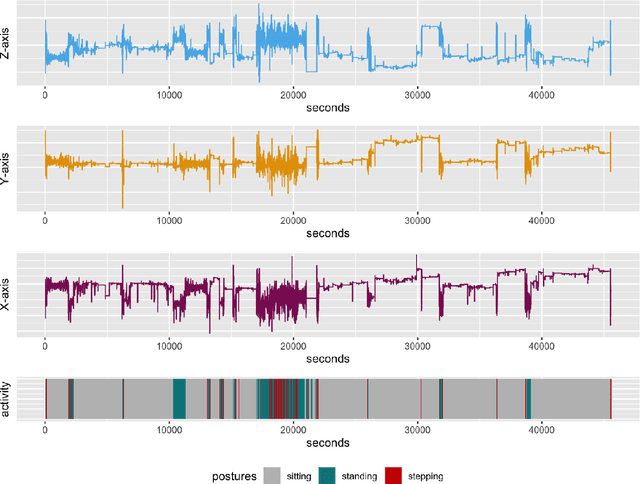

Cohort studies are increasingly using accelerometers for physical activity and sedentary behavior estimation. These devices tend to be less error-prone than self-report, can capture activity throughout the day, and are economical. However, previous methods for estimating sedentary behavior based on hip-worn data are often invalid or suboptimal under free-living situations and subject-to-subject variation. In this paper, we propose a local Markov switching model that takes this situation into account, and introduce a general procedure for posture classification and sedentary behavior analysis that fits the model naturally. Our method features changepoint detection methods in time series and also a two stage classification step that labels data into 3 classes(sitting, standing, stepping). Through a rigorous training-testing paradigm, we showed that our approach achieves > 80% accuracy. In addition, our method is robust and easy to interpret.
Multi-task Learning for Multilingual Neural Machine Translation
Oct 06, 2020
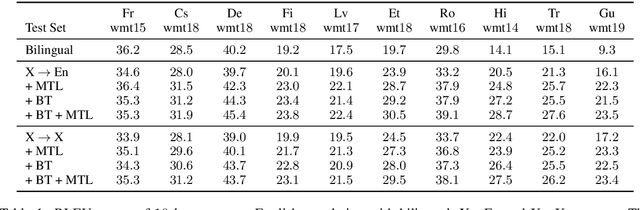


While monolingual data has been shown to be useful in improving bilingual neural machine translation (NMT), effectively and efficiently leveraging monolingual data for Multilingual NMT (MNMT) systems is a less explored area. In this work, we propose a multi-task learning (MTL) framework that jointly trains the model with the translation task on bitext data and two denoising tasks on the monolingual data. We conduct extensive empirical studies on MNMT systems with 10 language pairs from WMT datasets. We show that the proposed approach can effectively improve the translation quality for both high-resource and low-resource languages with large margin, achieving significantly better results than the individual bilingual models. We also demonstrate the efficacy of the proposed approach in the zero-shot setup for language pairs without bitext training data. Furthermore, we show the effectiveness of MTL over pre-training approaches for both NMT and cross-lingual transfer learning NLU tasks; the proposed approach outperforms massive scale models trained on single task.
Improving N-gram Language Models with Pre-trained Deep Transformer
Nov 22, 2019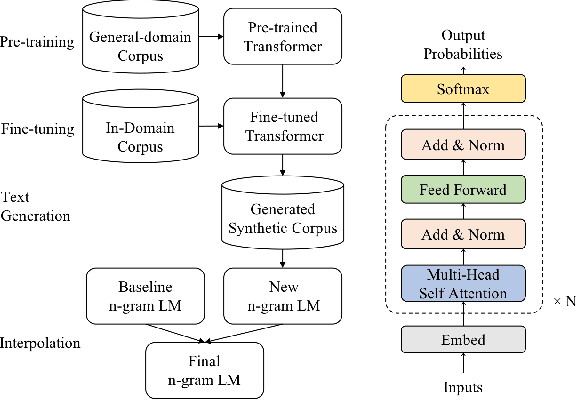

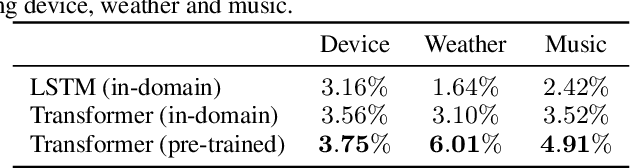
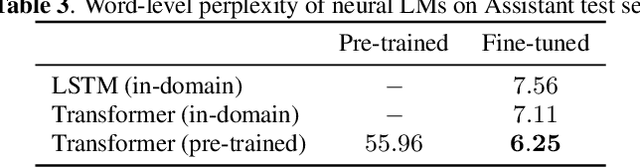
Although n-gram language models (LMs) have been outperformed by the state-of-the-art neural LMs, they are still widely used in speech recognition due to its high efficiency in inference. In this paper, we demonstrate that n-gram LM can be improved by neural LMs through a text generation based data augmentation method. In contrast to previous approaches, we employ a large-scale general domain pre-training followed by in-domain fine-tuning strategy to construct deep Transformer based neural LMs. Large amount of in-domain text data is generated with the well trained deep Transformer to construct new n-gram LMs, which are then interpolated with baseline n-gram systems. Empirical studies on different speech recognition tasks show that the proposed approach can effectively improve recognition accuracy. In particular, our proposed approach brings significant relative word error rate reduction up to 6.0% for domains with limited in-domain data.
Microsoft Research Asia's Systems for WMT19
Nov 07, 2019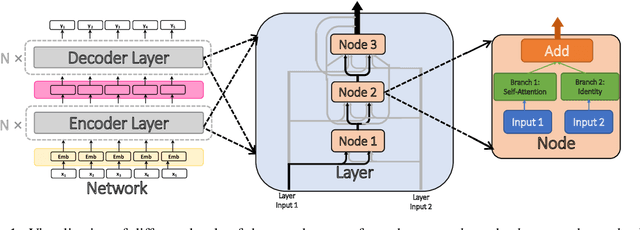

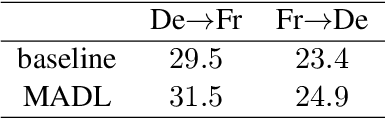
We Microsoft Research Asia made submissions to 11 language directions in the WMT19 news translation tasks. We won the first place for 8 of the 11 directions and the second place for the other three. Our basic systems are built on Transformer, back translation and knowledge distillation. We integrate several of our rececent techniques to enhance the baseline systems: multi-agent dual learning (MADL), masked sequence-to-sequence pre-training (MASS), neural architecture optimization (NAO), and soft contextual data augmentation (SCA).
Depth Growing for Neural Machine Translation
Jul 03, 2019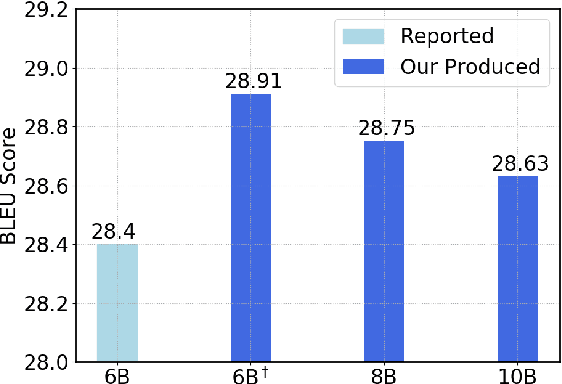
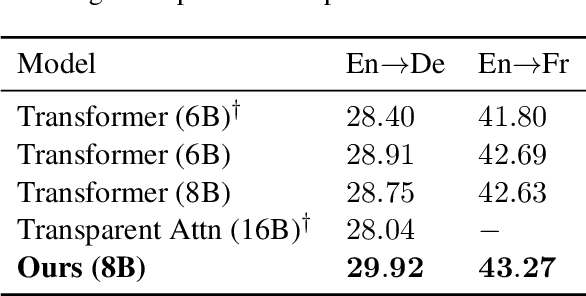

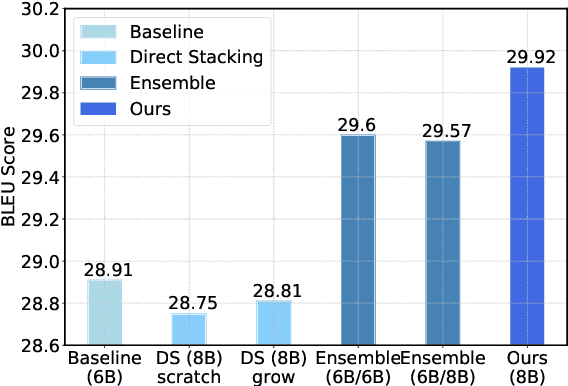
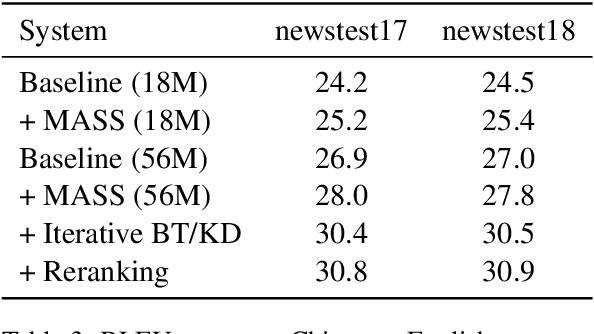
While very deep neural networks have shown effectiveness for computer vision and text classification applications, how to increase the network depth of neural machine translation (NMT) models for better translation quality remains a challenging problem. Directly stacking more blocks to the NMT model results in no improvement and even reduces performance. In this work, we propose an effective two-stage approach with three specially designed components to construct deeper NMT models, which result in significant improvements over the strong Transformer baselines on WMT$14$ English$\to$German and English$\to$French translation tasks\footnote{Our code is available at \url{https://github.com/apeterswu/Depth_Growing_NMT}}.
Non-Autoregressive Machine Translation with Auxiliary Regularization
Feb 22, 2019



As a new neural machine translation approach, Non-Autoregressive machine Translation (NAT) has attracted attention recently due to its high efficiency in inference. However, the high efficiency has come at the cost of not capturing the sequential dependency on the target side of translation, which causes NAT to suffer from two kinds of translation errors: 1) repeated translations (due to indistinguishable adjacent decoder hidden states), and 2) incomplete translations (due to incomplete transfer of source side information via the decoder hidden states). In this paper, we propose to address these two problems by improving the quality of decoder hidden representations via two auxiliary regularization terms in the training process of an NAT model. First, to make the hidden states more distinguishable, we regularize the similarity between consecutive hidden states based on the corresponding target tokens. Second, to force the hidden states to contain all the information in the source sentence, we leverage the dual nature of translation tasks (e.g., English to German and German to English) and minimize a backward reconstruction error to ensure that the hidden states of the NAT decoder are able to recover the source side sentence. Extensive experiments conducted on several benchmark datasets show that both regularization strategies are effective and can alleviate the issues of repeated translations and incomplete translations in NAT models. The accuracy of NAT models is therefore improved significantly over the state-of-the-art NAT models with even better efficiency for inference.