 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving N-gram Language Models with Pre-trained Deep Transformer
Nov 22, 2019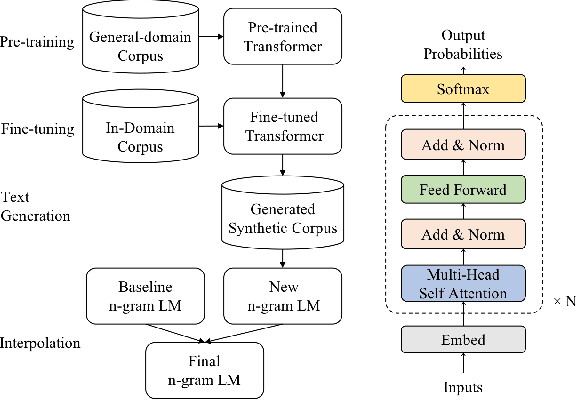

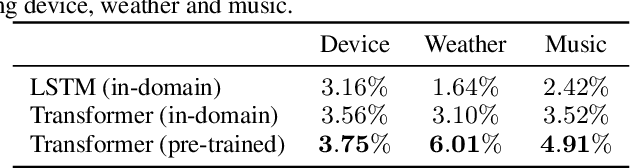
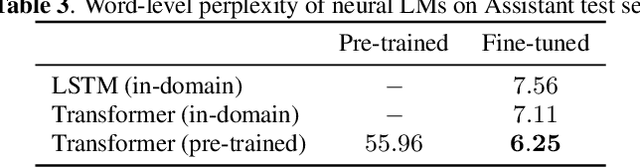
Although n-gram language models (LMs) have been outperformed by the state-of-the-art neural LMs, they are still widely used in speech recognition due to its high efficiency in inference. In this paper, we demonstrate that n-gram LM can be improved by neural LMs through a text generation based data augmentation method. In contrast to previous approaches, we employ a large-scale general domain pre-training followed by in-domain fine-tuning strategy to construct deep Transformer based neural LMs. Large amount of in-domain text data is generated with the well trained deep Transformer to construct new n-gram LMs, which are then interpolated with baseline n-gram systems. Empirical studies on different speech recognition tasks show that the proposed approach can effectively improve recognition accuracy. In particular, our proposed approach brings significant relative word error rate reduction up to 6.0% for domains with limited in-domain data.
An Empirical Study of Efficient ASR Rescoring with Transformers
Oct 24, 2019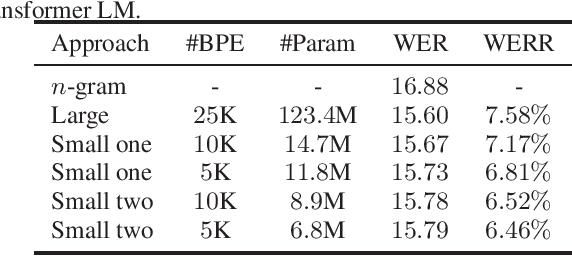
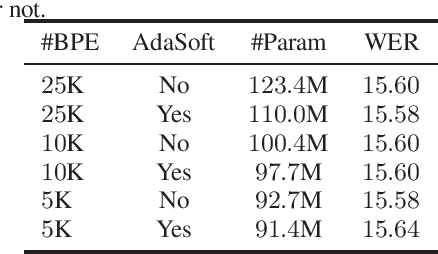
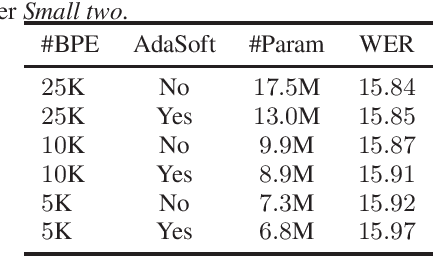
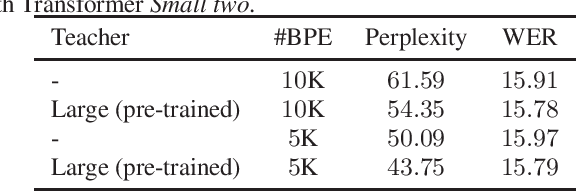
Neural language models (LMs) have been proved to significantly outperform classical n-gram LMs for language modeling due to their superior abilities to model long-range dependencies in text and handle data sparsity problems. And recently, well configured deep Transformers have exhibited superior performance over shallow stack of recurrent neural network layers for language modeling. However, these state-of-the-art deep Transformer models were mostly engineered to be deep with high model capacity, which makes it computationally inefficient and challenging to be deployed into large-scale real-world applications. Therefore, it is important to develop Transformer LMs that have relatively small model sizes, while still retaining good performance of those much larger models. In this paper, we aim to conduct empirical study on training Transformers with small parameter sizes in the context of ASR rescoring. By combining techniques including subword units, adaptive softmax, large-scale model pre-training, and knowledge distillation, we show that we are able to successfully train small Transformer LMs with significant relative word error rate reductions (WERR) through n-best rescoring. In particular, our experiments on a video speech recognition dataset show that we are able to achieve WERRs ranging from 6.46% to 7.17% while only with 5.5% to 11.9% parameter sizes of the well-known large GPT model [1], whose WERR with rescoring on the same dataset is 7.58%.
Transformer-based Acoustic Modeling for Hybrid Speech Recognition
Oct 22, 2019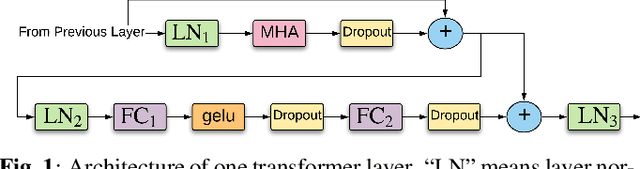
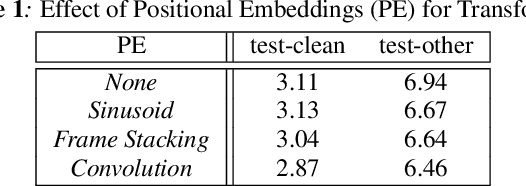
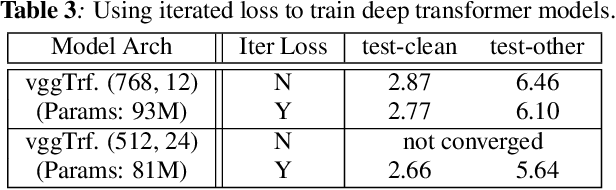
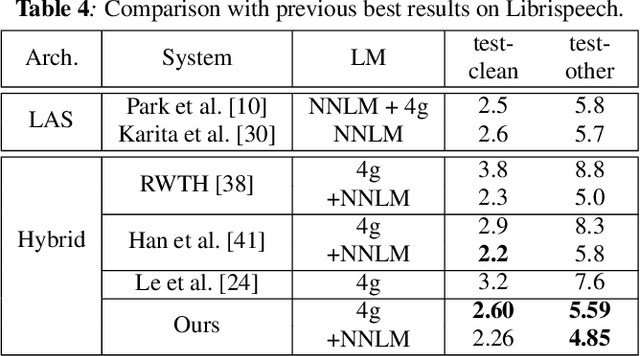
We propose and evaluate transformer-based acoustic models (AMs) for hybrid speech recognition. Several modeling choices are discussed in this work, including various positional embedding methods and an iterated loss to enable training deep transformers. We also present a preliminary study of using limited right context in transformer models, which makes it possible for streaming applications. We demonstrate that on the widely used Librispeech benchmark, our transformer-based AM outperforms the best published hybrid result by 19% to 26% relative when the standard n-gram language model (LM) is used. Combined with neural network LM for rescoring, our proposed approach achieves state-of-the-art results on Librispeech. Our findings are also confirmed on a much larger internal dataset.
Leveraging Deep Neural Networks and Knowledge Graphs for Entity Disambiguation
Apr 28, 2015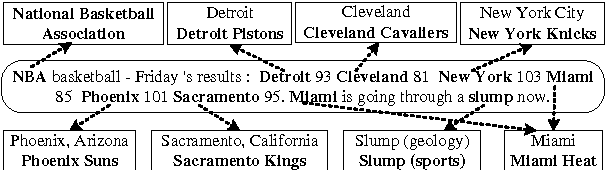

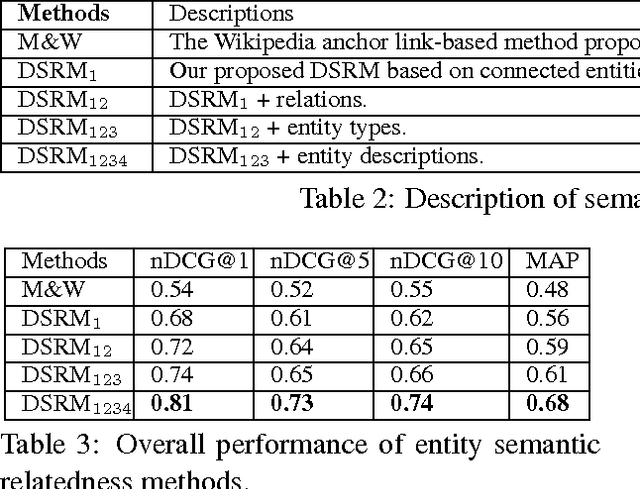
Entity Disambiguation aims to link mentions of ambiguous entities to a knowledge base (e.g., Wikipedia). Modeling topical coherence is crucial for this task based on the assumption that information from the same semantic context tends to belong to the same topic. This paper presents a novel deep semantic relatedness model (DSRM) based on deep neural networks (DNN) and semantic knowledge graphs (KGs) to measure entity semantic relatedness for topical coherence modeling. The DSRM is directly trained on large-scale KGs and it maps heterogeneous types of knowledge of an entity from KGs to numerical feature vectors in a latent space such that the distance between two semantically-related entities is minimized. Compared with the state-of-the-art relatedness approach proposed by (Milne and Witten, 2008a), the DSRM obtains 19.4% and 24.5% reductions in entity disambiguation errors on two publicly available datasets respectively.