 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Efficient ASR Rescoring with Transformers
Paper and Code
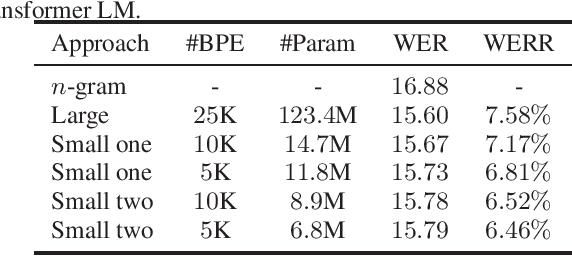
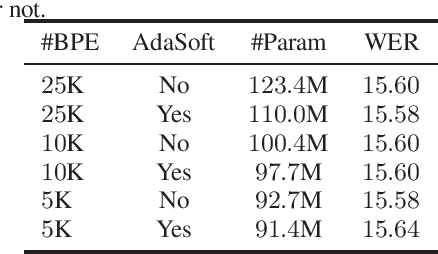
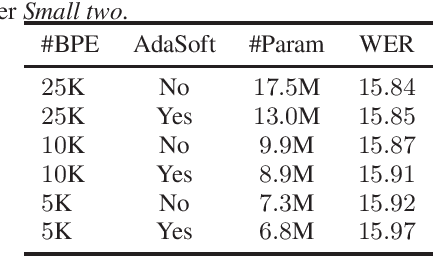
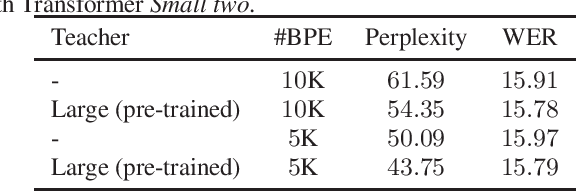
Neural language models (LMs) have been proved to significantly outperform classical n-gram LMs for language modeling due to their superior abilities to model long-range dependencies in text and handle data sparsity problems. And recently, well configured deep Transformers have exhibited superior performance over shallow stack of recurrent neural network layers for language modeling. However, these state-of-the-art deep Transformer models were mostly engineered to be deep with high model capacity, which makes it computationally inefficient and challenging to be deployed into large-scale real-world applications. Therefore, it is important to develop Transformer LMs that have relatively small model sizes, while still retaining good performance of those much larger models. In this paper, we aim to conduct empirical study on training Transformers with small parameter sizes in the context of ASR rescoring. By combining techniques including subword units, adaptive softmax, large-scale model pre-training, and knowledge distillation, we show that we are able to successfully train small Transformer LMs with significant relative word error rate reductions (WERR) through n-best rescoring. In particular, our experiments on a video speech recognition dataset show that we are able to achieve WERRs ranging from 6.46% to 7.17% while only with 5.5% to 11.9% parameter sizes of the well-known large GPT model [1], whose WERR with rescoring on the same dataset is 7.58%.