 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws of Synthetic Data for Language Models
Mar 26, 2025



Large language models (LLMs) achieve strong performance across diverse tasks, largely driven by high-quality web data used in pre-training. However, recent studies indicate this data source is rapidly depleting. Synthetic data emerges as a promising alternative, but it remains unclear whether synthetic datasets exhibit predictable scalability comparable to raw pre-training data. In this work, we systematically investigate the scaling laws of synthetic data by introducing SynthLLM, a scalable framework that transforms pre-training corpora into diverse, high-quality synthetic datasets. Our approach achieves this by automatically extracting and recombining high-level concepts across multiple documents using a graph algorithm. Key findings from our extensive mathematical experiments on SynthLLM include: (1) SynthLLM generates synthetic data that reliably adheres to the rectified scaling law across various model sizes; (2) Performance improvements plateau near 300B tokens; and (3) Larger models approach optimal performance with fewer training tokens. For instance, an 8B model peaks at 1T tokens, while a 3B model requires 4T. Moreover, comparisons with existing synthetic data generation and augmentation methods demonstrate that SynthLLM achieves superior performance and scalability. Our findings highlight synthetic data as a scalable and reliable alternative to organic pre-training corpora, offering a viable path toward continued improvement in model performance.
Dissecting In-Context Learning of Translations in GPTs
Oct 24, 2023



Most of the recent work in leveraging Large Language Models (LLMs) such as GPT-3 for Machine Translation (MT) has focused on selecting the few-shot samples for prompting. In this work, we try to better understand the role of demonstration attributes for the in-context learning of translations through perturbations of high-quality, in-domain demonstrations. We find that asymmetric perturbation of the source-target mappings yield vastly different results. We show that the perturbation of the source side has surprisingly little impact, while target perturbation can drastically reduce translation quality, suggesting that it is the output text distribution that provides the most important learning signal during in-context learning of translations. We propose a method named Zero-Shot-Context to add this signal automatically in Zero-Shot prompting. We demonstrate that it improves upon the zero-shot translation performance of GPT-3, even making it competitive with few-shot prompted translations.
Mixture of Quantized Experts (MoQE): Complementary Effect of Low-bit Quantization and Robustness
Oct 03, 2023

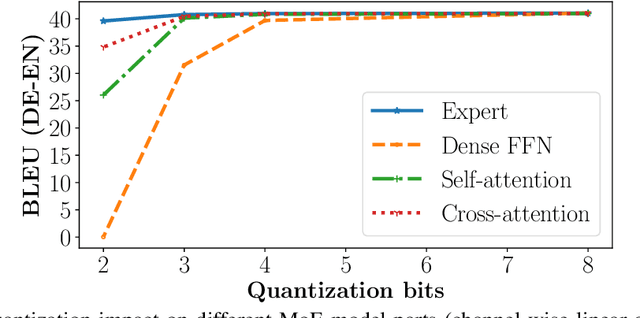

Large Mixture of Experts (MoE) models could achieve state-of-the-art quality on various language tasks, including machine translation task, thanks to the efficient model scaling capability with expert parallelism. However, it has brought a fundamental issue of larger memory consumption and increased memory bandwidth bottleneck at deployment time. In this paper, we propose Mixture of Quantized Experts (MoQE) which is a simple weight-only quantization method applying ultra low-bit down to 2-bit quantizations only to expert weights for mitigating the increased memory and latency issues of MoE models. We show that low-bit quantization together with the MoE architecture delivers a reliable model performance while reducing the memory size significantly even without any additional training in most cases. In particular, expert layers in MoE models are much more robust to the quantization than conventional feedforward networks (FFN) layers. In our comprehensive analysis, we show that MoE models with 2-bit expert weights can deliver better model performance than the dense model trained on the same dataset. As a result of low-bit quantization, we show the model size can be reduced by 79.6% of the original half precision floating point (fp16) MoE model. Combined with an optimized GPU runtime implementation, it also achieves 1.24X speed-up on A100 GPUs.
A Paradigm Shift in Machine Translation: Boosting Translation Performance of Large Language Models
Sep 20, 2023Generative Large Language Models (LLMs) have achieved remarkable advancements in various NLP tasks. However, these advances have not been reflected in the translation task, especially those with moderate model sizes (i.e., 7B or 13B parameters), which still lag behind conventional supervised encoder-decoder translation models. Previous studies have attempted to improve the translation capabilities of these moderate LLMs, but their gains have been limited. In this study, we propose a novel fine-tuning approach for LLMs that is specifically designed for the translation task, eliminating the need for the abundant parallel data that traditional translation models usually depend on. Our approach consists of two fine-tuning stages: initial fine-tuning on monolingual data followed by subsequent fine-tuning on a small set of high-quality parallel data. We introduce the LLM developed through this strategy as Advanced Language Model-based trAnslator (ALMA). Based on LLaMA-2 as our underlying model, our results show that the model can achieve an average improvement of more than 12 BLEU and 12 COMET over its zero-shot performance across 10 translation directions from the WMT'21 (2 directions) and WMT'22 (8 directions) test datasets. The performance is significantly better than all prior work and even superior to the NLLB-54B model and GPT-3.5-text-davinci-003, with only 7B or 13B parameters. This method establishes the foundation for a novel training paradigm in machine translation.
Task-Based MoE for Multitask Multilingual Machine Translation
Sep 11, 2023Mixture-of-experts (MoE) architecture has been proven a powerful method for diverse tasks in training deep models in many applications. However, current MoE implementations are task agnostic, treating all tokens from different tasks in the same manner. In this work, we instead design a novel method that incorporates task information into MoE models at different granular levels with shared dynamic task-based adapters. Our experiments and analysis show the advantages of our approaches over the dense and canonical MoE models on multi-task multilingual machine translations. With task-specific adapters, our models can additionally generalize to new tasks efficiently.
FineQuant: Unlocking Efficiency with Fine-Grained Weight-Only Quantization for LLMs
Aug 16, 2023Large Language Models (LLMs) have achieved state-of-the-art performance across various language tasks but pose challenges for practical deployment due to their substantial memory requirements. Furthermore, the latest generative models suffer from high inference costs caused by the memory bandwidth bottleneck in the auto-regressive decoding process. To address these issues, we propose an efficient weight-only quantization method that reduces memory consumption and accelerates inference for LLMs. To ensure minimal quality degradation, we introduce a simple and effective heuristic approach that utilizes only the model weights of a pre-trained model. This approach is applicable to both Mixture-of-Experts (MoE) and dense models without requiring additional fine-tuning. To demonstrate the effectiveness of our proposed method, we first analyze the challenges and issues associated with LLM quantization. Subsequently, we present our heuristic approach, which adaptively finds the granularity of quantization, effectively addressing these problems. Furthermore, we implement highly efficient GPU GEMMs that perform on-the-fly matrix multiplication and dequantization, supporting the multiplication of fp16 or bf16 activations with int8 or int4 weights. We evaluate our approach on large-scale open source models such as OPT-175B and internal MoE models, showcasing minimal accuracy loss while achieving up to 3.65 times higher throughput on the same number of GPUs.
Do GPTs Produce Less Literal Translations?
Jun 06, 2023



Large Language Models (LLMs) such as GPT-3 have emerged as general-purpose language models capable of addressing many natural language generation or understanding tasks. On the task of Machine Translation (MT), multiple works have investigated few-shot prompting mechanisms to elicit better translations from LLMs. However, there has been relatively little investigation on how such translations differ qualitatively from the translations generated by standard Neural Machine Translation (NMT) models. In this work, we investigate these differences in terms of the literalness of translations produced by the two systems. Using literalness measures involving word alignment and monotonicity, we find that translations out of English (E-X) from GPTs tend to be less literal, while exhibiting similar or better scores on MT quality metrics. We demonstrate that this finding is borne out in human evaluations as well. We then show that these differences are especially pronounced when translating sentences that contain idiomatic expressions.
ResiDual: Transformer with Dual Residual Connections
Apr 28, 2023



Transformer networks have become the preferred architecture for many tasks due to their state-of-the-art performance. However, the optimal way to implement residual connections in Transformer, which are essential for effective training, is still debated. Two widely used variants are the Post-Layer-Normalization (Post-LN) and Pre-Layer-Normalization (Pre-LN) Transformers, which apply layer normalization after each residual block's output or before each residual block's input, respectively. While both variants enjoy their advantages, they also suffer from severe limitations: Post-LN causes gradient vanishing issue that hinders training deep Transformers, and Pre-LN causes representation collapse issue that limits model capacity. In this paper, we propose ResiDual, a novel Transformer architecture with Pre-Post-LN (PPLN), which fuses the connections in Post-LN and Pre-LN together and inherits their advantages while avoids their limitations. We conduct both theoretical analyses and empirical experiments to verify the effectiveness of ResiDual. Theoretically, we prove that ResiDual has a lower bound on the gradient to avoid the vanishing issue due to the residual connection from Pre-LN. Moreover, ResiDual also has diverse model representations to avoid the collapse issue due to the residual connection from Post-LN. Empirically, ResiDual outperforms both Post-LN and Pre-LN on several machine translation benchmarks across different network depths and data sizes. Thanks to the good theoretical and empirical performance, ResiDual Transformer can serve as a foundation architecture for different AI models (e.g., large language models). Our code is available at https://github.com/microsoft/ResiDual.
How Good Are GPT Models at Machine Translation? A Comprehensive Evaluation
Feb 18, 2023



Generative Pre-trained Transformer (GPT) models have shown remarkable capabilities for natural language generation, but their performance for machine translation has not been thoroughly investigated. In this paper, we present a comprehensive evaluation of GPT models for machine translation, covering various aspects such as quality of different GPT models in comparison with state-of-the-art research and commercial systems, effect of prompting strategies, robustness towards domain shifts and document-level translation. We experiment with eighteen different translation directions involving high and low resource languages, as well as non English-centric translations, and evaluate the performance of three GPT models: ChatGPT, GPT3.5 (text-davinci-003), and text-davinci-002. Our results show that GPT models achieve very competitive translation quality for high resource languages, while having limited capabilities for low resource languages. We also show that hybrid approaches, which combine GPT models with other translation systems, can further enhance the translation quality. We perform comprehensive analysis and human evaluation to further understand the characteristics of GPT translations. We hope that our paper provides valuable insights for researchers and practitioners in the field and helps to better understand the potential and limitations of GPT models for translation.
Who Says Elephants Can't Run: Bringing Large Scale MoE Models into Cloud Scale Production
Nov 18, 2022



Mixture of Experts (MoE) models with conditional execution of sparsely activated layers have enabled training models with a much larger number of parameters. As a result, these models have achieved significantly better quality on various natural language processing tasks including machine translation. However, it remains challenging to deploy such models in real-life scenarios due to the large memory requirements and inefficient inference. In this work, we introduce a highly efficient inference framework with several optimization approaches to accelerate the computation of sparse models and cut down the memory consumption significantly. While we achieve up to 26x speed-up in terms of throughput, we also reduce the model size almost to one eighth of the original 32-bit float model by quantizing expert weights into 4-bit integers. As a result, we are able to deploy 136x larger models with 27% less cost and significantly better quality compared to the existing solutions. This enables a paradigm shift in deploying large scale multilingual MoE transformers models replacing the traditional practice of distilling teacher models into dozens of smaller models per language or task.