 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemorization Inheritance in Sequence-Level Knowledge Distillation for Neural Machine Translation
Feb 03, 2025



In this work, we explore how instance-level memorization in the teacher Neural Machine Translation (NMT) model gets inherited by the student model in sequence-level knowledge distillation (SeqKD). We find that despite not directly seeing the original training data, students memorize more than baseline models (models of the same size, trained on the original data) -- 3.4% for exact matches and 57% for extractive memorization -- and show increased hallucination rates. Further, under this SeqKD setting, we also characterize how students behave on specific training data subgroups, such as subgroups with low quality and specific counterfactual memorization (CM) scores, and find that students exhibit amplified denoising on low-quality subgroups. Finally, we propose a modification to SeqKD named Adaptive-SeqKD, which intervenes in SeqKD to reduce memorization and hallucinations. Overall, we recommend caution when applying SeqKD: students inherit both their teachers' superior performance and their fault modes, thereby requiring active monitoring.
On Instruction-Finetuning Neural Machine Translation Models
Oct 07, 2024In this work, we introduce instruction finetuning for Neural Machine Translation (NMT) models, which distills instruction following capabilities from Large Language Models (LLMs) into orders-of-magnitude smaller NMT models. Our instruction-finetuning recipe for NMT models enables customization of translations for a limited but disparate set of translation-specific tasks. We show that NMT models are capable of following multiple instructions simultaneously and demonstrate capabilities of zero-shot composition of instructions. We also show that through instruction finetuning, traditionally disparate tasks such as formality-controlled machine translation, multi-domain adaptation as well as multi-modal translations can be tackled jointly by a single instruction finetuned NMT model, at a performance level comparable to LLMs such as GPT-3.5-Turbo. To the best of our knowledge, our work is among the first to demonstrate the instruction-following capabilities of traditional NMT models, which allows for faster, cheaper and more efficient serving of customized translations.
Dissecting In-Context Learning of Translations in GPTs
Oct 24, 2023



Most of the recent work in leveraging Large Language Models (LLMs) such as GPT-3 for Machine Translation (MT) has focused on selecting the few-shot samples for prompting. In this work, we try to better understand the role of demonstration attributes for the in-context learning of translations through perturbations of high-quality, in-domain demonstrations. We find that asymmetric perturbation of the source-target mappings yield vastly different results. We show that the perturbation of the source side has surprisingly little impact, while target perturbation can drastically reduce translation quality, suggesting that it is the output text distribution that provides the most important learning signal during in-context learning of translations. We propose a method named Zero-Shot-Context to add this signal automatically in Zero-Shot prompting. We demonstrate that it improves upon the zero-shot translation performance of GPT-3, even making it competitive with few-shot prompted translations.
SLIDE: Reference-free Evaluation for Machine Translation using a Sliding Document Window
Sep 16, 2023


Reference-based metrics that operate at the sentence level typically outperform quality estimation metrics, which have access only to the source and system output. This is unsurprising, since references resolve ambiguities that may be present in the source. We investigate whether additional source context can effectively substitute for a reference. We present a metric, SLIDE (SLiding Document Evaluator), which operates on blocks of sentences using a window that slides over each document in the test set, feeding each chunk into an unmodified, off-the-shelf quality estimation model. We find that SLIDE obtains significantly higher pairwise system accuracy than its sentence-level baseline, in some cases even eliminating the gap with reference-base metrics. This suggests that source context may provide the same information as a human reference.
Do GPTs Produce Less Literal Translations?
Jun 06, 2023



Large Language Models (LLMs) such as GPT-3 have emerged as general-purpose language models capable of addressing many natural language generation or understanding tasks. On the task of Machine Translation (MT), multiple works have investigated few-shot prompting mechanisms to elicit better translations from LLMs. However, there has been relatively little investigation on how such translations differ qualitatively from the translations generated by standard Neural Machine Translation (NMT) models. In this work, we investigate these differences in terms of the literalness of translations produced by the two systems. Using literalness measures involving word alignment and monotonicity, we find that translations out of English (E-X) from GPTs tend to be less literal, while exhibiting similar or better scores on MT quality metrics. We demonstrate that this finding is borne out in human evaluations as well. We then show that these differences are especially pronounced when translating sentences that contain idiomatic expressions.
Leveraging GPT-4 for Automatic Translation Post-Editing
May 24, 2023
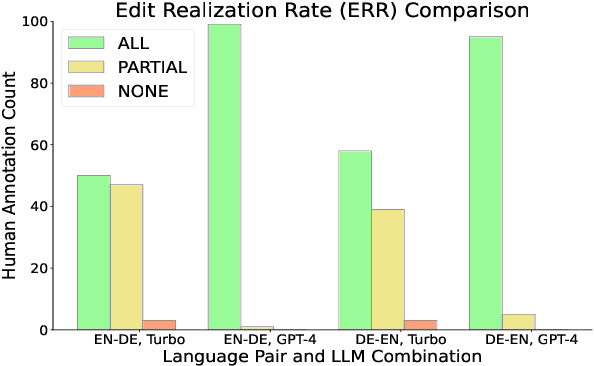
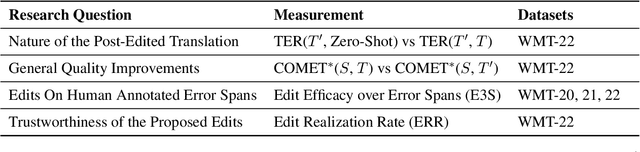

While Neural Machine Translation (NMT) represents the leading approach to Machine Translation (MT), the outputs of NMT models still require translation post-editing to rectify errors and enhance quality, particularly under critical settings. In this work, we formalize the task of translation post-editing with Large Language Models (LLMs) and explore the use of GPT-4 to automatically post-edit NMT outputs across several language pairs. Our results demonstrate that GPT-4 is adept at translation post-editing and produces meaningful edits even when the target language is not English. Notably, we achieve state-of-the-art performance on WMT-22 English-Chinese, English-German, Chinese-English and German-English language pairs using GPT-4 based post-editing, as evaluated by state-of-the-art MT quality metrics.
How Good Are GPT Models at Machine Translation? A Comprehensive Evaluation
Feb 18, 2023



Generative Pre-trained Transformer (GPT) models have shown remarkable capabilities for natural language generation, but their performance for machine translation has not been thoroughly investigated. In this paper, we present a comprehensive evaluation of GPT models for machine translation, covering various aspects such as quality of different GPT models in comparison with state-of-the-art research and commercial systems, effect of prompting strategies, robustness towards domain shifts and document-level translation. We experiment with eighteen different translation directions involving high and low resource languages, as well as non English-centric translations, and evaluate the performance of three GPT models: ChatGPT, GPT3.5 (text-davinci-003), and text-davinci-002. Our results show that GPT models achieve very competitive translation quality for high resource languages, while having limited capabilities for low resource languages. We also show that hybrid approaches, which combine GPT models with other translation systems, can further enhance the translation quality. We perform comprehensive analysis and human evaluation to further understand the characteristics of GPT translations. We hope that our paper provides valuable insights for researchers and practitioners in the field and helps to better understand the potential and limitations of GPT models for translation.
Rank-One Editing of Encoder-Decoder Models
Nov 23, 2022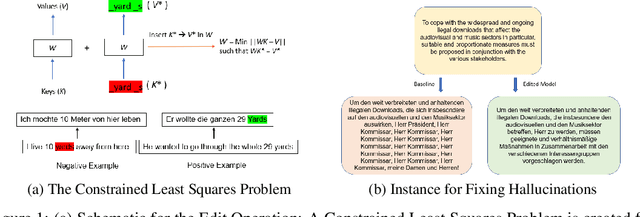

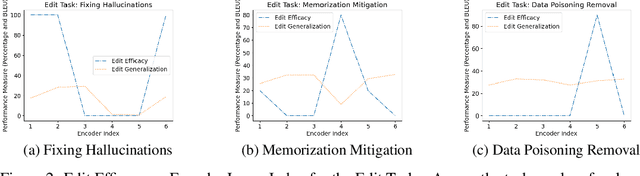

Large sequence to sequence models for tasks such as Neural Machine Translation (NMT) are usually trained over hundreds of millions of samples. However, training is just the origin of a model's life-cycle. Real-world deployments of models require further behavioral adaptations as new requirements emerge or shortcomings become known. Typically, in the space of model behaviors, behavior deletion requests are addressed through model retrainings whereas model finetuning is done to address behavior addition requests, both procedures being instances of data-based model intervention. In this work, we present a preliminary study investigating rank-one editing as a direct intervention method for behavior deletion requests in encoder-decoder transformer models. We propose four editing tasks for NMT and show that the proposed editing algorithm achieves high efficacy, while requiring only a single instance of positive example to fix an erroneous (negative) model behavior.
Operationalizing Specifications, In Addition to Test Sets for Evaluating Constrained Generative Models
Nov 19, 2022

In this work, we present some recommendations on the evaluation of state-of-the-art generative models for constrained generation tasks. The progress on generative models has been rapid in recent years. These large-scale models have had three impacts: firstly, the fluency of generation in both language and vision modalities has rendered common average-case evaluation metrics much less useful in diagnosing system errors. Secondly, the same substrate models now form the basis of a number of applications, driven both by the utility of their representations as well as phenomena such as in-context learning, which raise the abstraction level of interacting with such models. Thirdly, the user expectations around these models and their feted public releases have made the technical challenge of out of domain generalization much less excusable in practice. Subsequently, our evaluation methodologies haven't adapted to these changes. More concretely, while the associated utility and methods of interacting with generative models have expanded, a similar expansion has not been observed in their evaluation practices. In this paper, we argue that the scale of generative models could be exploited to raise the abstraction level at which evaluation itself is conducted and provide recommendations for the same. Our recommendations are based on leveraging specifications as a powerful instrument to evaluate generation quality and are readily applicable to a variety of tasks.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.