 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Instruction-Finetuning Neural Machine Translation Models
Oct 07, 2024In this work, we introduce instruction finetuning for Neural Machine Translation (NMT) models, which distills instruction following capabilities from Large Language Models (LLMs) into orders-of-magnitude smaller NMT models. Our instruction-finetuning recipe for NMT models enables customization of translations for a limited but disparate set of translation-specific tasks. We show that NMT models are capable of following multiple instructions simultaneously and demonstrate capabilities of zero-shot composition of instructions. We also show that through instruction finetuning, traditionally disparate tasks such as formality-controlled machine translation, multi-domain adaptation as well as multi-modal translations can be tackled jointly by a single instruction finetuned NMT model, at a performance level comparable to LLMs such as GPT-3.5-Turbo. To the best of our knowledge, our work is among the first to demonstrate the instruction-following capabilities of traditional NMT models, which allows for faster, cheaper and more efficient serving of customized translations.
PyMarian: Fast Neural Machine Translation and Evaluation in Python
Aug 15, 2024



The deep learning language of choice these days is Python; measured by factors such as available libraries and technical support, it is hard to beat. At the same time, software written in lower-level programming languages like C++ retain advantages in speed. We describe a Python interface to Marian NMT, a C++-based training and inference toolkit for sequence-to-sequence models, focusing on machine translation. This interface enables models trained with Marian to be connected to the rich, wide range of tools available in Python. A highlight of the interface is the ability to compute state-of-the-art COMET metrics from Python but using Marian's inference engine, with a speedup factor of up to 7.8$\times$ the existing implementations. We also briefly spotlight a number of other integrations, including Jupyter notebooks, connection with prebuilt models, and a web app interface provided with the package. PyMarian is available in PyPI via $\texttt{pip install pymarian}$.
On-the-Fly Fusion of Large Language Models and Machine Translation
Nov 14, 2023



We propose the on-the-fly ensembling of a machine translation model with an LLM, prompted on the same task and input. We perform experiments on 4 language pairs (both directions) with varying data amounts. We find that a slightly weaker-at-translation LLM can improve translations of a NMT model, and ensembling with an LLM can produce better translations than ensembling two stronger MT models. We combine our method with various techniques from LLM prompting, such as in context learning and translation context.
SOTASTREAM: A Streaming Approach to Machine Translation Training
Aug 14, 2023



Many machine translation toolkits make use of a data preparation step wherein raw data is transformed into a tensor format that can be used directly by the trainer. This preparation step is increasingly at odds with modern research and development practices because this process produces a static, unchangeable version of the training data, making common training-time needs difficult (e.g., subword sampling), time-consuming (preprocessing with large data can take days), expensive (e.g., disk space), and cumbersome (managing experiment combinatorics). We propose an alternative approach that separates the generation of data from the consumption of that data. In this approach, there is no separate pre-processing step; data generation produces an infinite stream of permutations of the raw training data, which the trainer tensorizes and batches as it is consumed. Additionally, this data stream can be manipulated by a set of user-definable operators that provide on-the-fly modifications, such as data normalization, augmentation or filtering. We release an open-source toolkit, SOTASTREAM, that implements this approach: https://github.com/marian-nmt/sotastream. We show that it cuts training time, adds flexibility, reduces experiment management complexity, and reduces disk space, all without affecting the accuracy of the trained models.
Escaping the sentence-level paradigm in machine translation
Apr 25, 2023It is well-known that document context is vital for resolving a range of translation ambiguities, and in fact the document setting is the most natural setting for nearly all translation. It is therefore unfortunate that machine translation -- both research and production -- largely remains stuck in a decades-old sentence-level translation paradigm. It is also an increasingly glaring problem in light of competitive pressure from large language models, which are natively document-based. Much work in document-context machine translation exists, but for various reasons has been unable to catch hold. This paper suggests a path out of this rut by addressing three impediments at once: what architectures should we use? where do we get document-level information for training them? and how do we know whether they are any good? In contrast to work on specialized architectures, we show that the standard Transformer architecture is sufficient, provided it has enough capacity. Next, we address the training data issue by taking document samples from back-translated data only, where the data is not only more readily available, but is also of higher quality compared to parallel document data, which may contain machine translation output. Finally, we propose generative variants of existing contrastive metrics that are better able to discriminate among document systems. Results in four large-data language pairs (DE$\rightarrow$EN, EN$\rightarrow$DE, EN$\rightarrow$FR, and EN$\rightarrow$RU) establish the success of these three pieces together in improving document-level performance.
The JHU-Microsoft Submission for WMT21 Quality Estimation Shared Task
Sep 17, 2021
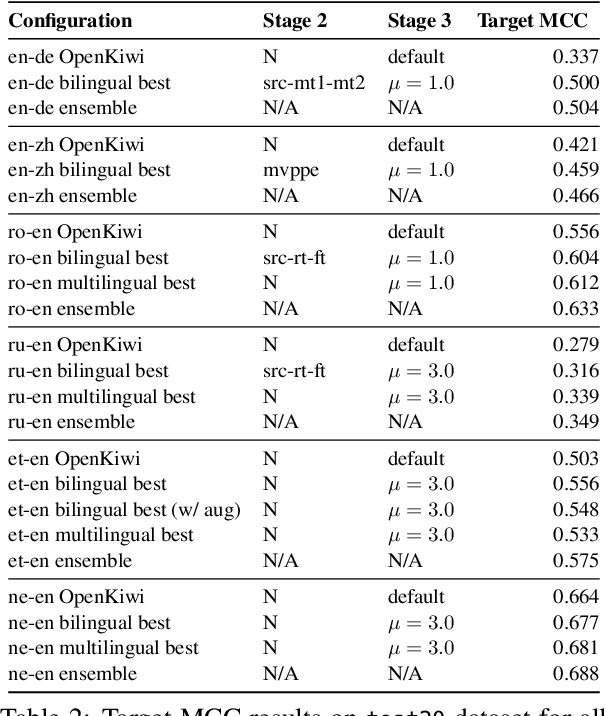
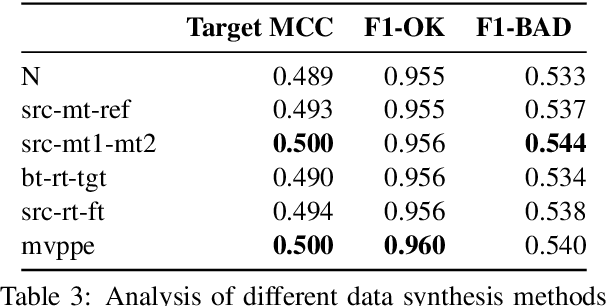
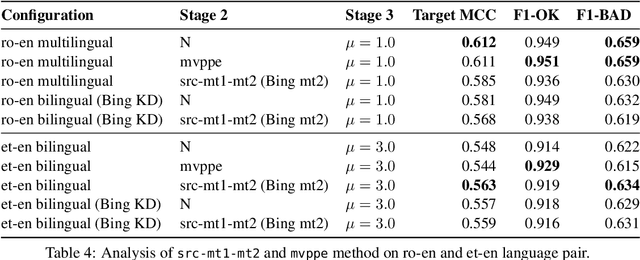
This paper presents the JHU-Microsoft joint submission for WMT 2021 quality estimation shared task. We only participate in Task 2 (post-editing effort estimation) of the shared task, focusing on the target-side word-level quality estimation. The techniques we experimented with include Levenshtein Transformer training and data augmentation with a combination of forward, backward, round-trip translation, and pseudo post-editing of the MT output. We demonstrate the competitiveness of our system compared to the widely adopted OpenKiwi-XLM baseline. Our system is also the top-ranking system on the MT MCC metric for the English-German language pair.
Levenshtein Training for Word-level Quality Estimation
Sep 15, 2021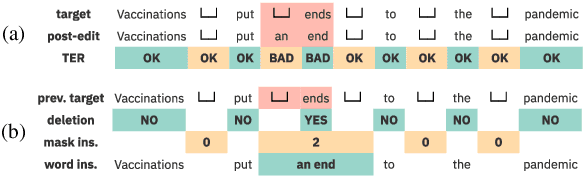
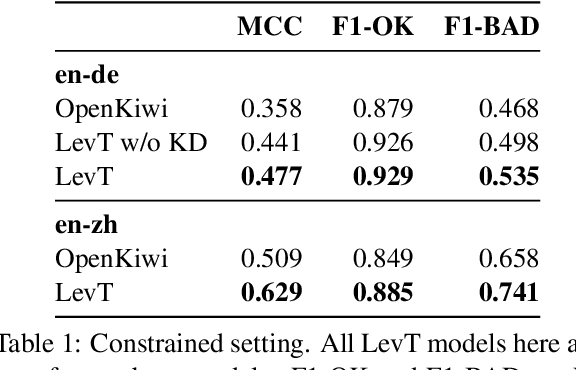
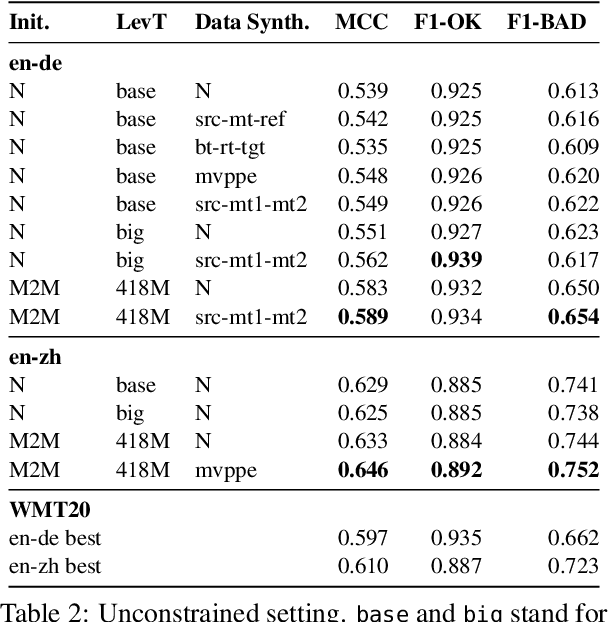
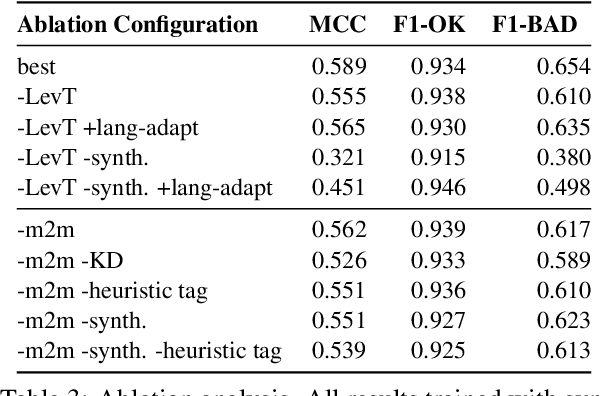
We propose a novel scheme to use the Levenshtein Transformer to perform the task of word-level quality estimation. A Levenshtein Transformer is a natural fit for this task: trained to perform decoding in an iterative manner, a Levenshtein Transformer can learn to post-edit without explicit supervision. To further minimize the mismatch between the translation task and the word-level QE task, we propose a two-stage transfer learning procedure on both augmented data and human post-editing data. We also propose heuristics to construct reference labels that are compatible with subword-level finetuning and inference. Results on WMT 2020 QE shared task dataset show that our proposed method has superior data efficiency under the data-constrained setting and competitive performance under the unconstrained setting.
To Ship or Not to Ship: An Extensive Evaluation of Automatic Metrics for Machine Translation
Jul 22, 2021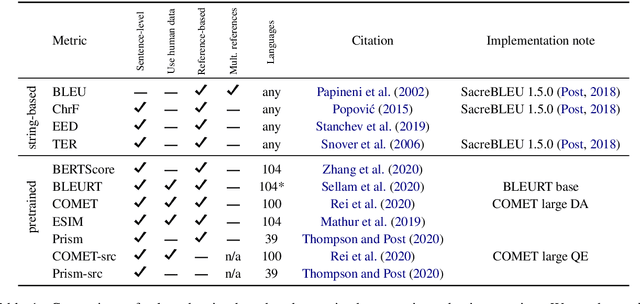
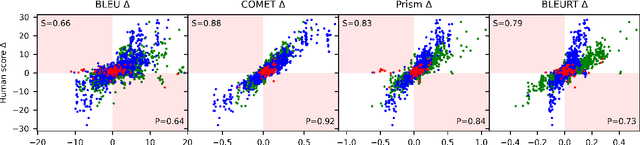
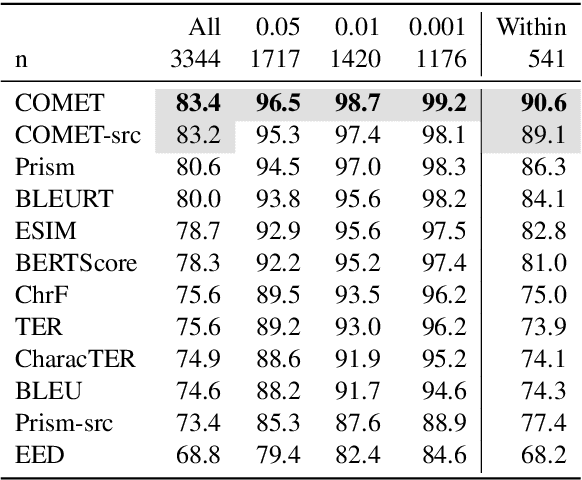
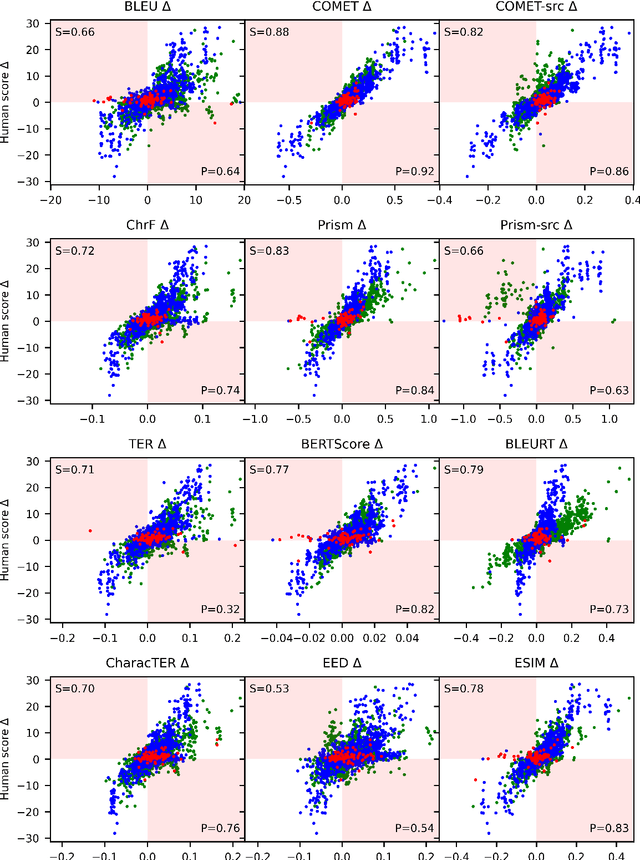
Automatic metrics are commonly used as the exclusive tool for declaring the superiority of one machine translation system's quality over another. The community choice of automatic metric guides research directions and industrial developments by deciding which models are deemed better. Evaluating metrics correlations has been limited to a small collection of human judgements. In this paper, we corroborate how reliable metrics are in contrast to human judgements on - to the best of our knowledge - the largest collection of human judgements. We investigate which metrics have the highest accuracy to make system-level quality rankings for pairs of systems, taking human judgement as a gold standard, which is the closest scenario to the real metric usage. Furthermore, we evaluate the performance of various metrics across different language pairs and domains. Lastly, we show that the sole use of BLEU negatively affected the past development of improved models. We release the collection of human judgements of 4380 systems, and 2.3 M annotated sentences for further analysis and replication of our work.
On User Interfaces for Large-Scale Document-Level Human Evaluation of Machine Translation Outputs
Apr 21, 2021
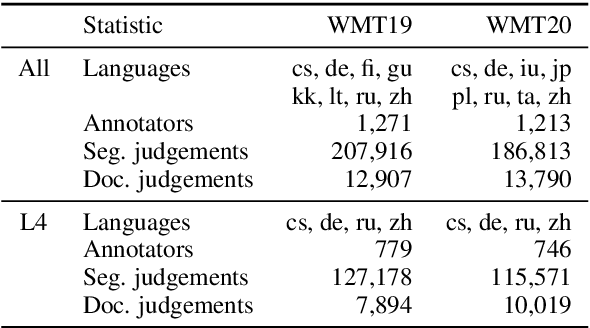
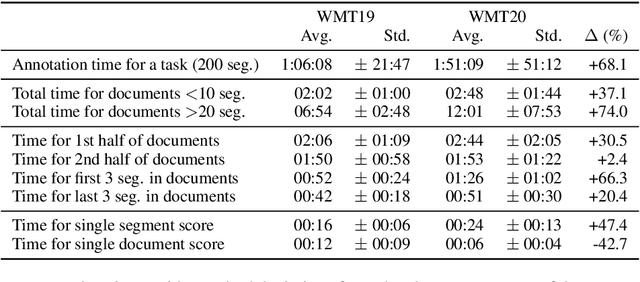
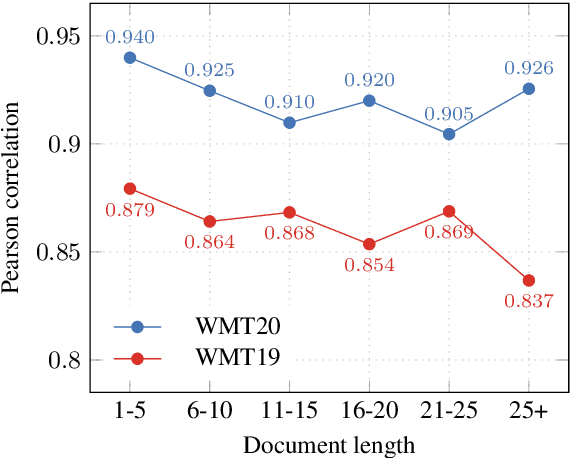
Recent studies emphasize the need of document context in human evaluation of machine translations, but little research has been done on the impact of user interfaces on annotator productivity and the reliability of assessments. In this work, we compare human assessment data from the last two WMT evaluation campaigns collected via two different methods for document-level evaluation. Our analysis shows that a document-centric approach to evaluation where the annotator is presented with the entire document context on a screen leads to higher quality segment and document level assessments. It improves the correlation between segment and document scores and increases inter-annotator agreement for document scores but is considerably more time consuming for annotators.
The Curious Case of Hallucinations in Neural Machine Translation
Apr 14, 2021

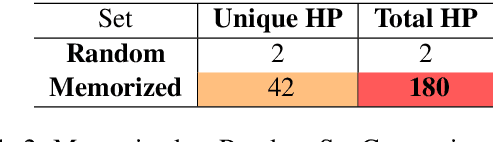
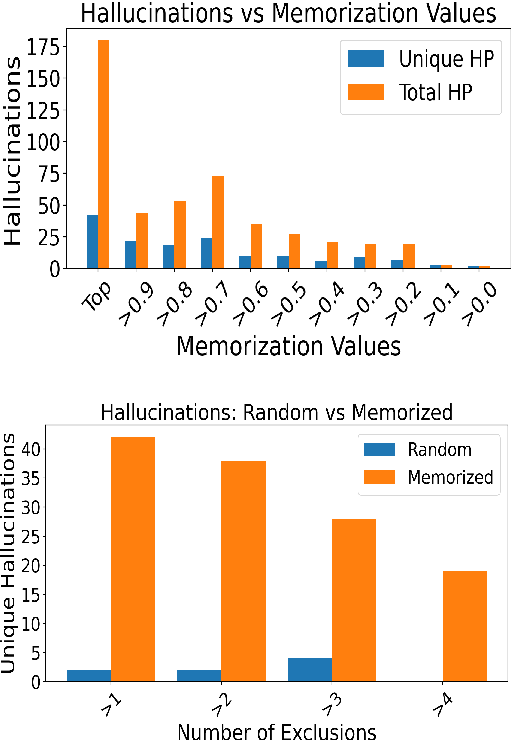
In this work, we study hallucinations in Neural Machine Translation (NMT), which lie at an extreme end on the spectrum of NMT pathologies. Firstly, we connect the phenomenon of hallucinations under source perturbation to the Long-Tail theory of Feldman (2020), and present an empirically validated hypothesis that explains hallucinations under source perturbation. Secondly, we consider hallucinations under corpus-level noise (without any source perturbation) and demonstrate that two prominent types of natural hallucinations (detached and oscillatory outputs) could be generated and explained through specific corpus-level noise patterns. Finally, we elucidate the phenomenon of hallucination amplification in popular data-generation processes such as Backtranslation and sequence-level Knowledge Distillation.