 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOTASTREAM: A Streaming Approach to Machine Translation Training
Aug 14, 2023



Many machine translation toolkits make use of a data preparation step wherein raw data is transformed into a tensor format that can be used directly by the trainer. This preparation step is increasingly at odds with modern research and development practices because this process produces a static, unchangeable version of the training data, making common training-time needs difficult (e.g., subword sampling), time-consuming (preprocessing with large data can take days), expensive (e.g., disk space), and cumbersome (managing experiment combinatorics). We propose an alternative approach that separates the generation of data from the consumption of that data. In this approach, there is no separate pre-processing step; data generation produces an infinite stream of permutations of the raw training data, which the trainer tensorizes and batches as it is consumed. Additionally, this data stream can be manipulated by a set of user-definable operators that provide on-the-fly modifications, such as data normalization, augmentation or filtering. We release an open-source toolkit, SOTASTREAM, that implements this approach: https://github.com/marian-nmt/sotastream. We show that it cuts training time, adds flexibility, reduces experiment management complexity, and reduces disk space, all without affecting the accuracy of the trained models.
Lipper: Synthesizing Thy Speech using Multi-View Lipreading
Jun 28, 2019
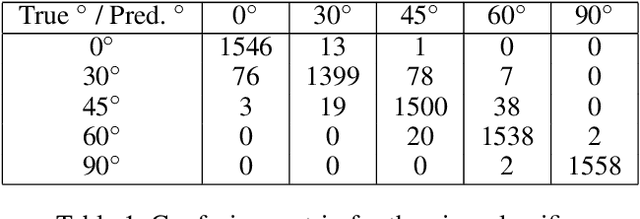


Lipreading has a lot of potential applications such as in the domain of surveillance and video conferencing. Despite this, most of the work in building lipreading systems has been limited to classifying silent videos into classes representing text phrases. However, there are multiple problems associated with making lipreading a text-based classification task like its dependence on a particular language and vocabulary mapping. Thus, in this paper we propose a multi-view lipreading to audio system, namely Lipper, which models it as a regression task. The model takes silent videos as input and produces speech as the output. With multi-view silent videos, we observe an improvement over single-view speech reconstruction results. We show this by presenting an exhaustive set of experiments for speaker-dependent, out-of-vocabulary and speaker-independent settings. Further, we compare the delay values of Lipper with other speechreading systems in order to show the real-time nature of audio produced. We also perform a user study for the audios produced in order to understand the level of comprehensibility of audios produced using Lipper.
Small Boxes Big Data: A Deep Learning Approach to Optimize Variable Sized Bin Packing
Feb 14, 2017
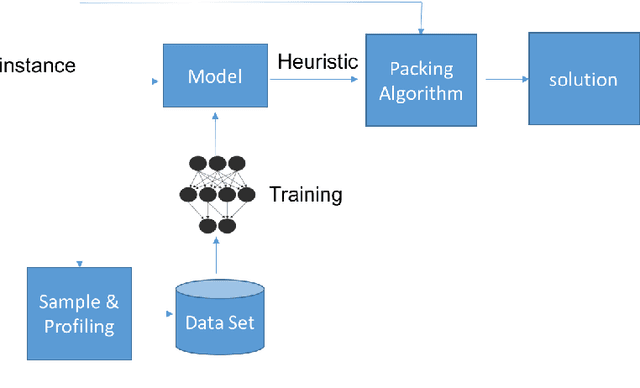
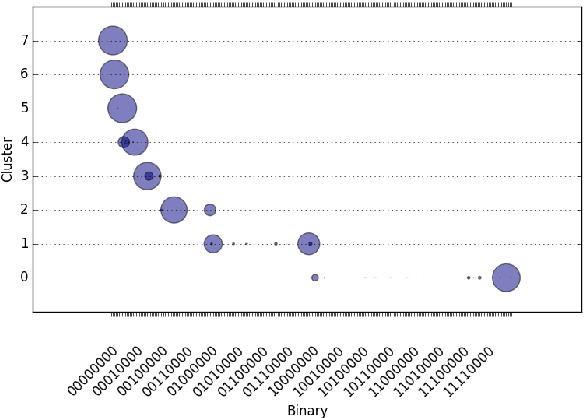
Bin Packing problems have been widely studied because of their broad applications in different domains. Known as a set of NP-hard problems, they have different vari- ations and many heuristics have been proposed for obtaining approximate solutions. Specifically, for the 1D variable sized bin packing problem, the two key sets of optimization heuristics are the bin assignment and the bin allocation. Usually the performance of a single static optimization heuristic can not beat that of a dynamic one which is tailored for each bin packing instance. Building such an adaptive system requires modeling the relationship between bin features and packing perform profiles. The primary drawbacks of traditional AI machine learnings for this task are the natural limitations of feature engineering, such as the curse of dimensionality and feature selection quality. We introduce a deep learning approach to overcome the drawbacks by applying a large training data set, auto feature selection and fast, accurate labeling. We show in this paper how to build such a system by both theoretical formulation and engineering practices. Our prediction system achieves up to 89% training accuracy and 72% validation accuracy to select the best heuristic that can generate a better quality bin packing solution.