 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyMarian: Fast Neural Machine Translation and Evaluation in Python
Aug 15, 2024



The deep learning language of choice these days is Python; measured by factors such as available libraries and technical support, it is hard to beat. At the same time, software written in lower-level programming languages like C++ retain advantages in speed. We describe a Python interface to Marian NMT, a C++-based training and inference toolkit for sequence-to-sequence models, focusing on machine translation. This interface enables models trained with Marian to be connected to the rich, wide range of tools available in Python. A highlight of the interface is the ability to compute state-of-the-art COMET metrics from Python but using Marian's inference engine, with a speedup factor of up to 7.8$\times$ the existing implementations. We also briefly spotlight a number of other integrations, including Jupyter notebooks, connection with prebuilt models, and a web app interface provided with the package. PyMarian is available in PyPI via $\texttt{pip install pymarian}$.
Preliminary WMT24 Ranking of General MT Systems and LLMs
Jul 29, 2024



This is the preliminary ranking of WMT24 General MT systems based on automatic metrics. The official ranking will be a human evaluation, which is superior to the automatic ranking and supersedes it. The purpose of this report is not to interpret any findings but only provide preliminary results to the participants of the General MT task that may be useful during the writing of the system submission.
BotEval: Facilitating Interactive Human Evaluation
Jul 25, 2024Following the rapid progress in natural language processing (NLP) models, language models are applied to increasingly more complex interactive tasks such as negotiations and conversation moderations. Having human evaluators directly interact with these NLP models is essential for adequately evaluating the performance on such interactive tasks. We develop BotEval, an easily customizable, open-source, evaluation toolkit that focuses on enabling human-bot interactions as part of the evaluation process, as opposed to human evaluators making judgements for a static input. BotEval balances flexibility for customization and user-friendliness by providing templates for common use cases that span various degrees of complexity and built-in compatibility with popular crowdsourcing platforms. We showcase the numerous useful features of BotEval through a study that evaluates the performance of various chatbots on their effectiveness for conversational moderation and discuss how BotEval differs from other annotation tools.
SOTASTREAM: A Streaming Approach to Machine Translation Training
Aug 14, 2023



Many machine translation toolkits make use of a data preparation step wherein raw data is transformed into a tensor format that can be used directly by the trainer. This preparation step is increasingly at odds with modern research and development practices because this process produces a static, unchangeable version of the training data, making common training-time needs difficult (e.g., subword sampling), time-consuming (preprocessing with large data can take days), expensive (e.g., disk space), and cumbersome (managing experiment combinatorics). We propose an alternative approach that separates the generation of data from the consumption of that data. In this approach, there is no separate pre-processing step; data generation produces an infinite stream of permutations of the raw training data, which the trainer tensorizes and batches as it is consumed. Additionally, this data stream can be manipulated by a set of user-definable operators that provide on-the-fly modifications, such as data normalization, augmentation or filtering. We release an open-source toolkit, SOTASTREAM, that implements this approach: https://github.com/marian-nmt/sotastream. We show that it cuts training time, adds flexibility, reduces experiment management complexity, and reduces disk space, all without affecting the accuracy of the trained models.
Checks and Strategies for Enabling Code-Switched Machine Translation
Oct 11, 2022
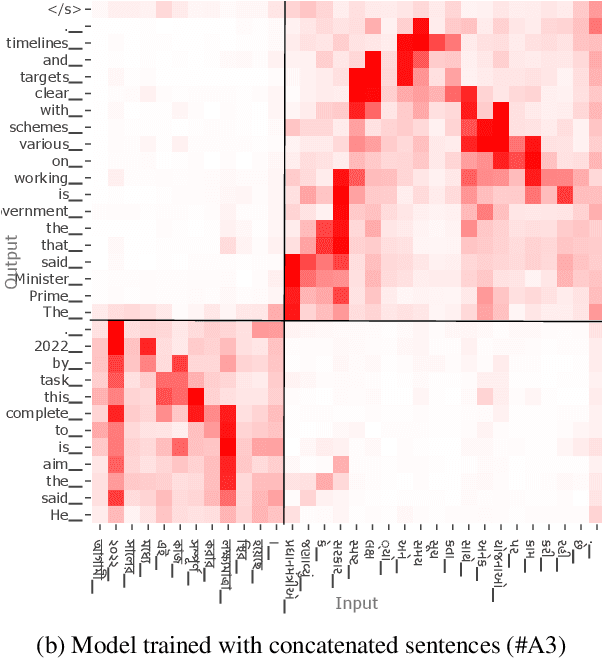
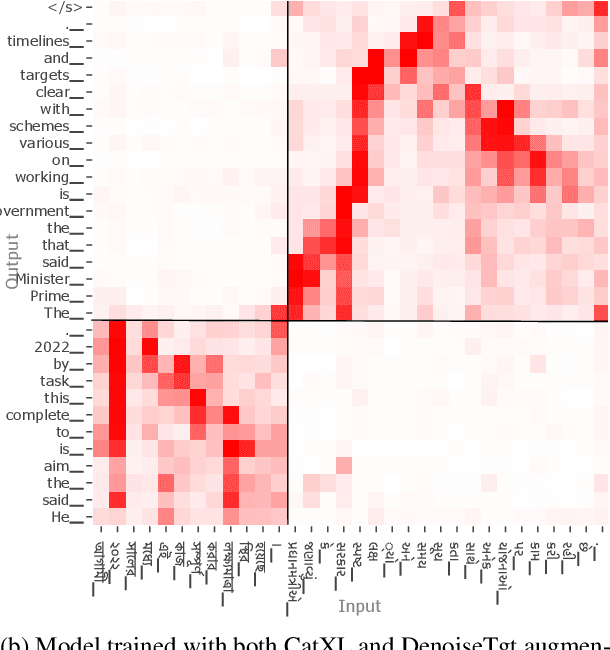
Code-switching is a common phenomenon among multilingual speakers, where alternation between two or more languages occurs within the context of a single conversation. While multilingual humans can seamlessly switch back and forth between languages, multilingual neural machine translation (NMT) models are not robust to such sudden changes in input. This work explores multilingual NMT models' ability to handle code-switched text. First, we propose checks to measure switching capability. Second, we investigate simple and effective data augmentation methods that can enhance an NMT model's ability to support code-switching. Finally, by using a glass-box analysis of attention modules, we demonstrate the effectiveness of these methods in improving robustness.
Macro-Average: Rare Types Are Important Too
Apr 12, 2021
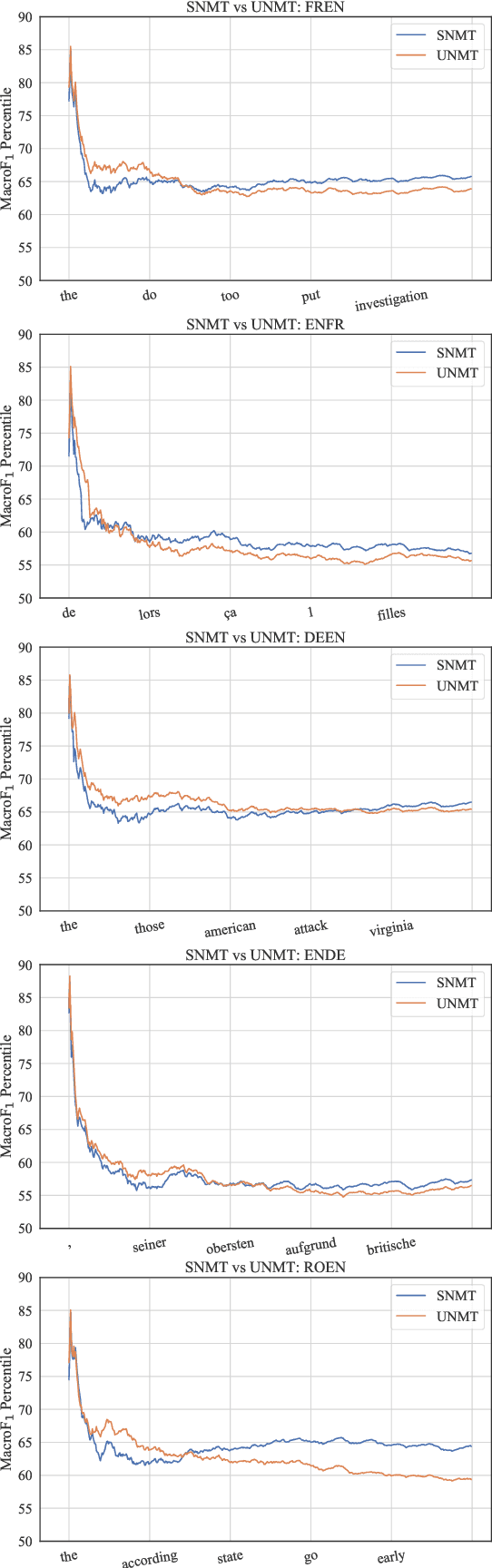
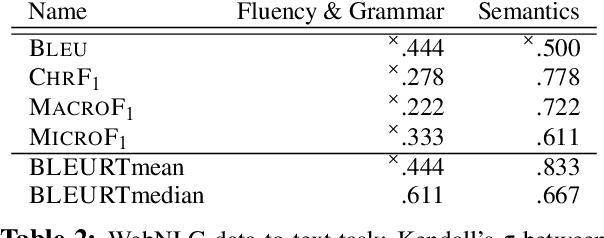
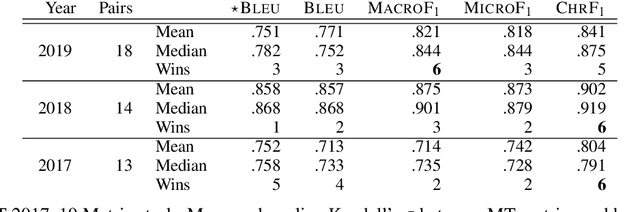
While traditional corpus-level evaluation metrics for machine translation (MT) correlate well with fluency, they struggle to reflect adequacy. Model-based MT metrics trained on segment-level human judgments have emerged as an attractive replacement due to strong correlation results. These models, however, require potentially expensive re-training for new domains and languages. Furthermore, their decisions are inherently non-transparent and appear to reflect unwelcome biases. We explore the simple type-based classifier metric, MacroF1, and study its applicability to MT evaluation. We find that MacroF1 is competitive on direct assessment, and outperforms others in indicating downstream cross-lingual information retrieval task performance. Further, we show that MacroF1 can be used to effectively compare supervised and unsupervised neural machine translation, and reveal significant qualitative differences in the methods' outputs.
Many-to-English Machine Translation Tools, Data, and Pretrained Models
Apr 01, 2021
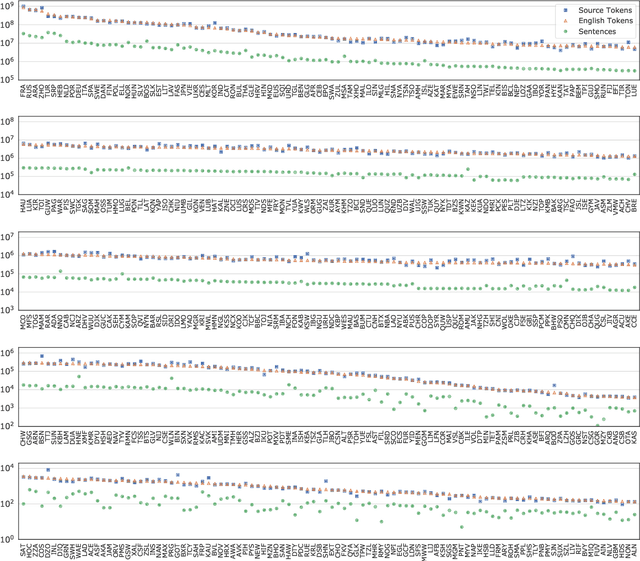
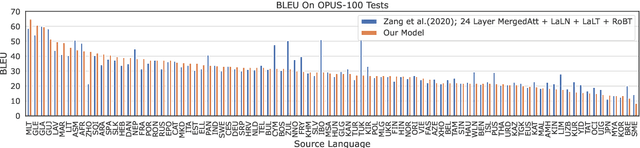

While there are more than 7000 languages in the world, most translation research efforts have targeted a few high-resource languages. Commercial translation systems support only one hundred languages or fewer, and do not make these models available for transfer to low resource languages. In this work, we present useful tools for machine translation research: MTData, NLCodec, and RTG. We demonstrate their usefulness by creating a multilingual neural machine translation model capable of translating from 500 source languages to English. We make this multilingual model readily downloadable and usable as a service, or as a parent model for transfer-learning to even lower-resource languages.
Neural Machine Translation with Imbalanced Classes
Apr 05, 2020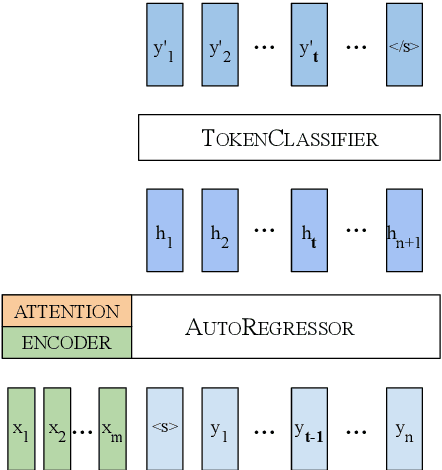

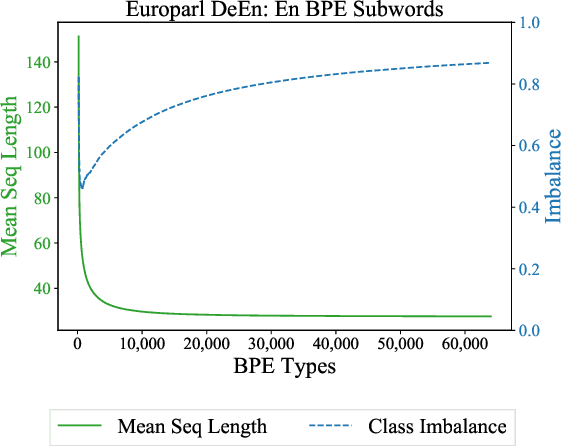
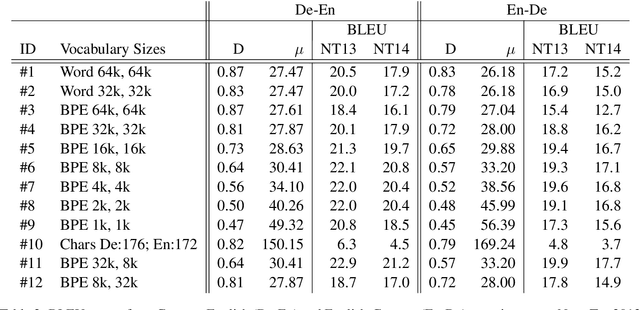
We cast neural machine translation (NMT) as a classification task in an autoregressive setting and analyze the limitations of both classification and autoregression components. Classifiers are known to perform better with balanced class distributions during training. Since the Zipfian nature of languages causes imbalanced classes, we explore the effect of class imbalance on NMT. We analyze the effect of vocabulary sizes on NMT performance and reveal an explanation for 'why' certain vocabulary sizes are better than others.
Man is to Person as Woman is to Location: Measuring Gender Bias in Named Entity Recognition
Oct 24, 2019

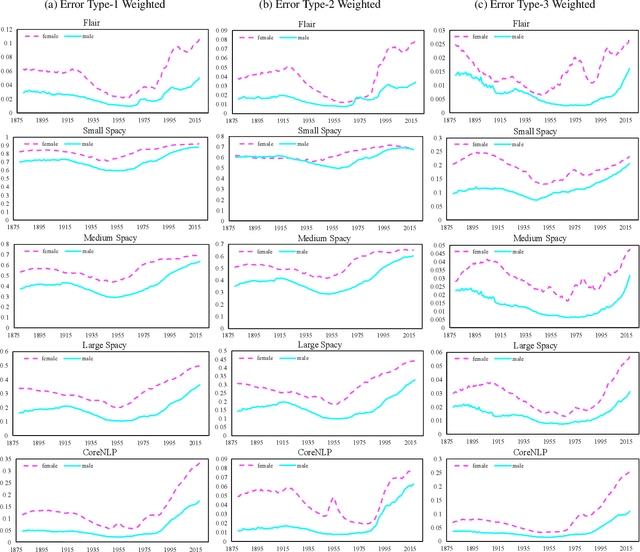
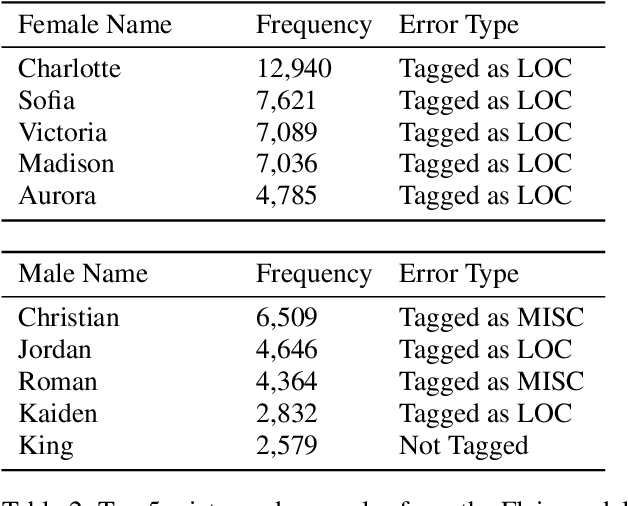
We study the bias in several state-of-the-art named entity recognition (NER) models---specifically, a difference in the ability to recognize male and female names as PERSON entity types. We evaluate NER models on a dataset containing 139 years of U.S. census baby names and find that relatively more female names, as opposed to male names, are not recognized as PERSON entities. We study the extent of this bias in several NER systems that are used prominently in industry and academia. In addition, we also report a bias in the datasets on which these models were trained. The result of this analysis yields a new benchmark for gender bias evaluation in named entity recognition systems. The data and code for the application of this benchmark will be publicly available for researchers to use.
Always Lurking: Understanding and Mitigating Bias in Online Human Trafficking Detection
Dec 03, 2017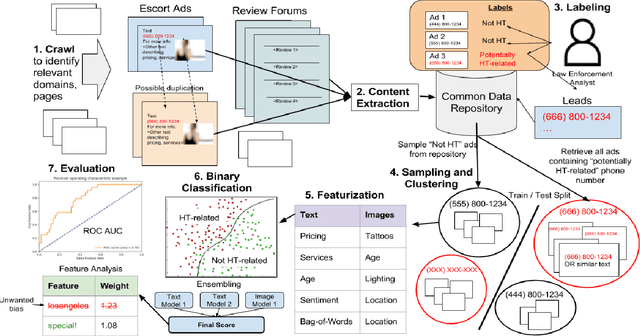
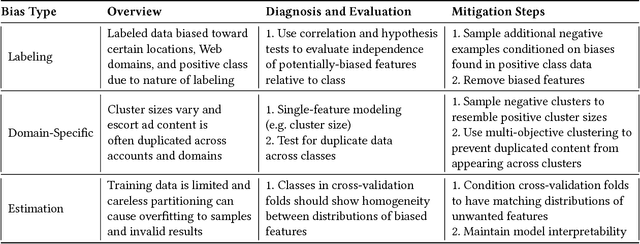
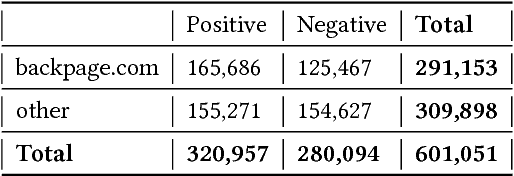
Web-based human trafficking activity has increased in recent years but it remains sparsely dispersed among escort advertisements and difficult to identify due to its often-latent nature. The use of intelligent systems to detect trafficking can thus have a direct impact on investigative resource allocation and decision-making, and, more broadly, help curb a widespread social problem. Trafficking detection involves assigning a normalized score to a set of escort advertisements crawled from the Web -- a higher score indicates a greater risk of trafficking-related (involuntary) activities. In this paper, we define and study the problem of trafficking detection and present a trafficking detection pipeline architecture developed over three years of research within the DARPA Memex program. Drawing on multi-institutional data, systems, and experiences collected during this time, we also conduct post hoc bias analyses and present a bias mitigation plan. Our findings show that, while automatic trafficking detection is an important application of AI for social good, it also provides cautionary lessons for deploying predictive machine learning algorithms without appropriate de-biasing. This ultimately led to integration of an interpretable solution into a search system that contains over 100 million advertisements and is used by over 200 law enforcement agencies to investigate leads.
* Submitted to 2018 AAAI 1st conference on AI, Ethics, and Society. Awaiting review