 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMacro-Average: Rare Types Are Important Too
Paper and Code

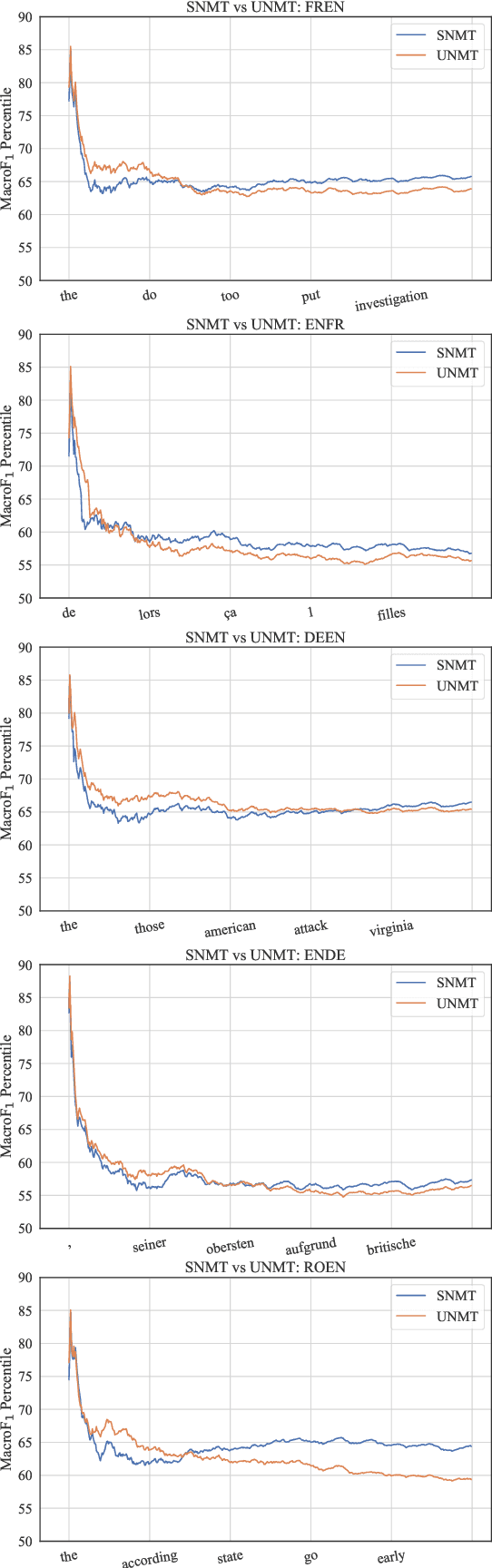
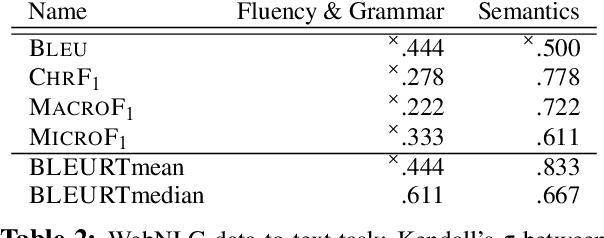
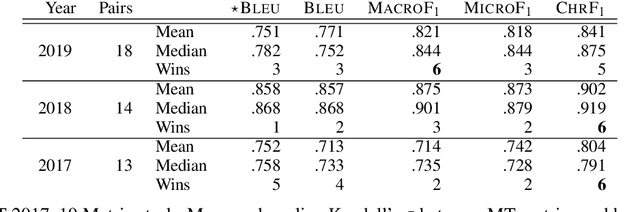
While traditional corpus-level evaluation metrics for machine translation (MT) correlate well with fluency, they struggle to reflect adequacy. Model-based MT metrics trained on segment-level human judgments have emerged as an attractive replacement due to strong correlation results. These models, however, require potentially expensive re-training for new domains and languages. Furthermore, their decisions are inherently non-transparent and appear to reflect unwelcome biases. We explore the simple type-based classifier metric, MacroF1, and study its applicability to MT evaluation. We find that MacroF1 is competitive on direct assessment, and outperforms others in indicating downstream cross-lingual information retrieval task performance. Further, we show that MacroF1 can be used to effectively compare supervised and unsupervised neural machine translation, and reveal significant qualitative differences in the methods' outputs.