 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Approaches to Automatic Summarization in Less-Resourced Languages
Dec 30, 2025Automatic text summarization has achieved high performance in high-resourced languages like English, but comparatively less attention has been given to summarization in less-resourced languages. This work compares a variety of different approaches to summarization from zero-shot prompting of LLMs large and small to fine-tuning smaller models like mT5 with and without three data augmentation approaches and multilingual transfer. We also explore an LLM translation pipeline approach, translating from the source language to English, summarizing and translating back. Evaluating with five different metrics, we find that there is variation across LLMs in their performance across similar parameter sizes, that our multilingual fine-tuned mT5 baseline outperforms most other approaches including zero-shot LLM performance for most metrics, and that LLM as judge may be less reliable on less-resourced languages.
From tests to effect sizes: Quantifying uncertainty and statistical variability in multilingual and multitask NLP evaluation benchmarks
Sep 26, 2025In this paper, we introduce a set of resampling-based methods for quantifying uncertainty and statistical precision of evaluation metrics in multilingual and/or multitask NLP benchmarks. We show how experimental variation in performance scores arises from both model- and data-related sources, and that accounting for both of them is necessary to avoid substantially underestimating the overall variability over hypothetical replications. Using multilingual question answering, machine translation, and named entity recognition as example tasks, we also demonstrate how resampling methods are useful for computing sampling distributions for various quantities used in leaderboards such as the average/median, pairwise differences between models, and rankings.
Overview of ADoBo at IberLEF 2025: Automatic Detection of Anglicisms in Spanish
Jul 29, 2025This paper summarizes the main findings of ADoBo 2025, the shared task on anglicism identification in Spanish proposed in the context of IberLEF 2025. Participants of ADoBo 2025 were asked to detect English lexical borrowings (or anglicisms) from a collection of Spanish journalistic texts. Five teams submitted their solutions for the test phase. Proposed systems included LLMs, deep learning models, Transformer-based models and rule-based systems. The results range from F1 scores of 0.17 to 0.99, which showcases the variability in performance different systems can have for this task.
OpenNER 1.0: Standardized Open-Access Named Entity Recognition Datasets in 50+ Languages
Dec 12, 2024We present OpenNER 1.0, a standardized collection of openly available named entity recognition (NER) datasets. OpenNER contains 34 datasets spanning 51 languages, annotated in varying named entity ontologies. We correct annotation format issues, standardize the original datasets into a uniform representation, map entity type names to be more consistent across corpora, and provide the collection in a structure that enables research in multilingual and multi-ontology NER. We provide baseline models using three pretrained multilingual language models to compare the performance of recent models and facilitate future research in NER.
CoNLL#: Fine-grained Error Analysis and a Corrected Test Set for CoNLL-03 English
May 20, 2024Modern named entity recognition systems have steadily improved performance in the age of larger and more powerful neural models. However, over the past several years, the state-of-the-art has seemingly hit another plateau on the benchmark CoNLL-03 English dataset. In this paper, we perform a deep dive into the test outputs of the highest-performing NER models, conducting a fine-grained evaluation of their performance by introducing new document-level annotations on the test set. We go beyond F1 scores by categorizing errors in order to interpret the true state of the art for NER and guide future work. We review previous attempts at correcting the various flaws of the test set and introduce CoNLL#, a new corrected version of the test set that addresses its systematic and most prevalent errors, allowing for low-noise, interpretable error analysis.
* Accepted to LREC-COLING 2024
ParaNames 1.0: Creating an Entity Name Corpus for 400+ Languages using Wikidata
May 15, 2024We introduce ParaNames, a massively multilingual parallel name resource consisting of 140 million names spanning over 400 languages. Names are provided for 16.8 million entities, and each entity is mapped from a complex type hierarchy to a standard type (PER/LOC/ORG). Using Wikidata as a source, we create the largest resource of this type to date. We describe our approach to filtering and standardizing the data to provide the best quality possible. ParaNames is useful for multilingual language processing, both in defining tasks for name translation/transliteration and as supplementary data for tasks such as named entity recognition and linking. We demonstrate the usefulness of ParaNames on two tasks. First, we perform canonical name translation between English and 17 other languages. Second, we use it as a gazetteer for multilingual named entity recognition, obtaining performance improvements on all 10 languages evaluated.
QueryNER: Segmentation of E-commerce Queries
May 15, 2024



We present QueryNER, a manually-annotated dataset and accompanying model for e-commerce query segmentation. Prior work in sequence labeling for e-commerce has largely addressed aspect-value extraction which focuses on extracting portions of a product title or query for narrowly defined aspects. Our work instead focuses on the goal of dividing a query into meaningful chunks with broadly applicable types. We report baseline tagging results and conduct experiments comparing token and entity dropping for null and low recall query recovery. Challenging test sets are created using automatic transformations and show how simple data augmentation techniques can make the models more robust to noise. We make the QueryNER dataset publicly available.
What changes when you randomly choose BPE merge operations? Not much
May 04, 2023We introduce three simple randomized variants of byte pair encoding (BPE) and explore whether randomizing the selection of merge operations substantially affects a downstream machine translation task. We focus on translation into morphologically rich languages, hypothesizing that this task may show sensitivity to the method of choosing subwords. Analysis using a Bayesian linear model indicates that two of the variants perform nearly indistinguishably compared to standard BPE while the other degrades performance less than we anticipated. We conclude that although standard BPE is widely used, there exists an interesting universe of potential variations on it worth investigating. Our code is available at: https://github.com/bltlab/random-bpe.
LR-Sum: Summarization for Less-Resourced Languages
Dec 19, 2022This preprint describes work in progress on LR-Sum, a new permissively-licensed dataset created with the goal of enabling further research in automatic summarization for less-resourced languages. LR-Sum contains human-written summaries for 40 languages, many of which are less-resourced. We describe our process for extracting and filtering the dataset from the Multilingual Open Text corpus (Palen-Michel et al., 2022). The source data is public domain newswire collected from from Voice of America websites, and LR-Sum is released under a Creative Commons license (CC BY 4.0), making it one of the most openly-licensed multilingual summarization datasets. We describe how we plan to use the data for modeling experiments and discuss limitations of the dataset.
Borrowing or Codeswitching? Annotating for Finer-Grained Distinctions in Language Mixing
Jun 10, 2022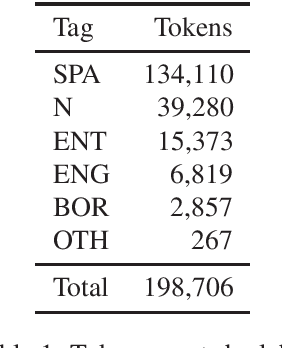
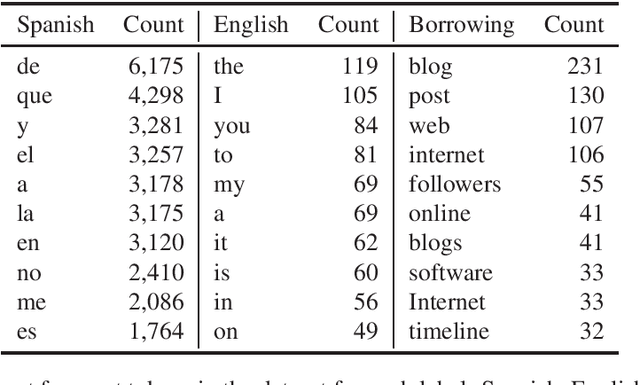

We present a new corpus of Twitter data annotated for codeswitching and borrowing between Spanish and English. The corpus contains 9,500 tweets annotated at the token level with codeswitches, borrowings, and named entities. This corpus differs from prior corpora of codeswitching in that we attempt to clearly define and annotate the boundary between codeswitching and borrowing and do not treat common "internet-speak" ('lol', etc.) as codeswitching when used in an otherwise monolingual context. The result is a corpus that enables the study and modeling of Spanish-English borrowing and codeswitching on Twitter in one dataset. We present baseline scores for modeling the labels of this corpus using Transformer-based language models. The annotation itself is released with a CC BY 4.0 license, while the text it applies to is distributed in compliance with the Twitter terms of service.