 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParaNames: A Massively Multilingual Entity Name Corpus
Paper and Code
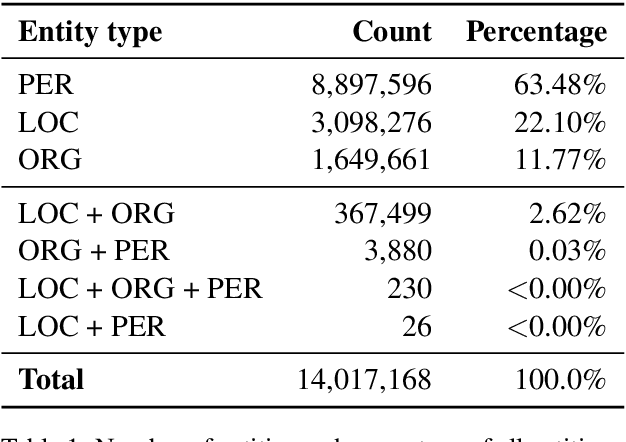
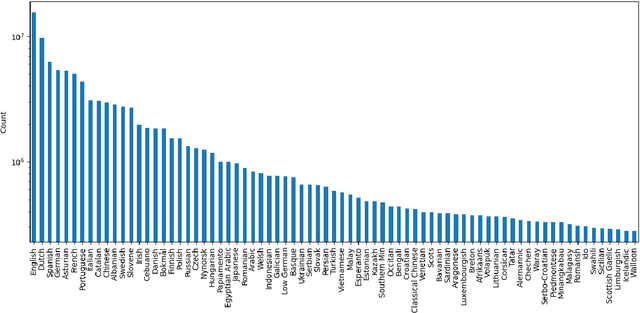
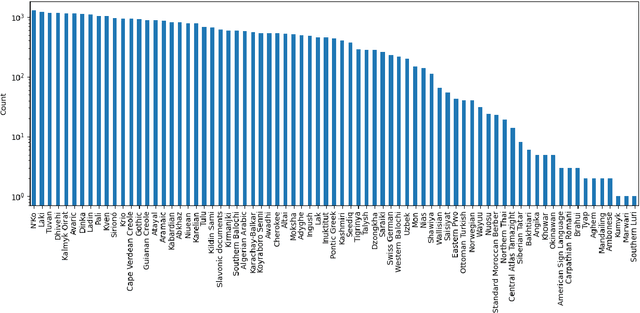
This preprint describes work in progress on ParaNames, a multilingual parallel name resource consisting of names for approximately 14 million entities. The included names span over 400 languages, and almost all entities are mapped to standardized entity types (PER/LOC/ORG). Using Wikidata as a source, we create the largest resource of this type to-date. We describe our approach to filtering and standardizing the data to provide the best quality possible. ParaNames is useful for multilingual language processing, both in defining tasks for name translation/transliteration and as supplementary data for tasks such as named entity recognition and linking. We demonstrate an application of ParaNames by training a multilingual model for canonical name translation to and from English. Our resource is released at \url{https://github.com/bltlab/paranames} under a Creative Commons license (CC BY 4.0).