 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom tests to effect sizes: Quantifying uncertainty and statistical variability in multilingual and multitask NLP evaluation benchmarks
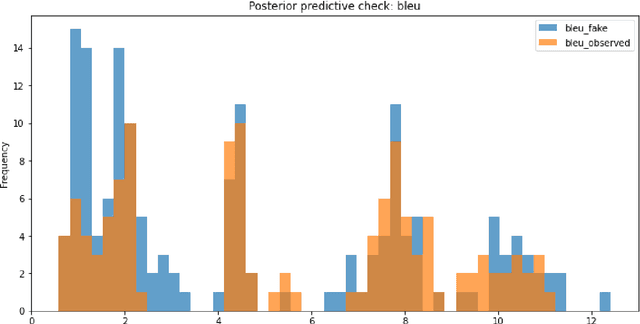
Sep 26, 2025In this paper, we introduce a set of resampling-based methods for quantifying uncertainty and statistical precision of evaluation metrics in multilingual and/or multitask NLP benchmarks. We show how experimental variation in performance scores arises from both model- and data-related sources, and that accounting for both of them is necessary to avoid substantially underestimating the overall variability over hypothetical replications. Using multilingual question answering, machine translation, and named entity recognition as example tasks, we also demonstrate how resampling methods are useful for computing sampling distributions for various quantities used in leaderboards such as the average/median, pairwise differences between models, and rankings.
OpenNER 1.0: Standardized Open-Access Named Entity Recognition Datasets in 50+ Languages
Dec 12, 2024We present OpenNER 1.0, a standardized collection of openly available named entity recognition (NER) datasets. OpenNER contains 34 datasets spanning 51 languages, annotated in varying named entity ontologies. We correct annotation format issues, standardize the original datasets into a uniform representation, map entity type names to be more consistent across corpora, and provide the collection in a structure that enables research in multilingual and multi-ontology NER. We provide baseline models using three pretrained multilingual language models to compare the performance of recent models and facilitate future research in NER.
Evaluating Morphological Compositional Generalization in Large Language Models
Oct 16, 2024Large language models (LLMs) have demonstrated significant progress in various natural language generation and understanding tasks. However, their linguistic generalization capabilities remain questionable, raising doubts about whether these models learn language similarly to humans. While humans exhibit compositional generalization and linguistic creativity in language use, the extent to which LLMs replicate these abilities, particularly in morphology, is under-explored. In this work, we systematically investigate the morphological generalization abilities of LLMs through the lens of compositionality. We define morphemes as compositional primitives and design a novel suite of generative and discriminative tasks to assess morphological productivity and systematicity. Focusing on agglutinative languages such as Turkish and Finnish, we evaluate several state-of-the-art instruction-finetuned multilingual models, including GPT-4 and Gemini. Our analysis shows that LLMs struggle with morphological compositional generalization particularly when applied to novel word roots, with performance declining sharply as morphological complexity increases. While models can identify individual morphological combinations better than chance, their performance lacks systematicity, leading to significant accuracy gaps compared to humans.
ParaNames 1.0: Creating an Entity Name Corpus for 400+ Languages using Wikidata
May 15, 2024We introduce ParaNames, a massively multilingual parallel name resource consisting of 140 million names spanning over 400 languages. Names are provided for 16.8 million entities, and each entity is mapped from a complex type hierarchy to a standard type (PER/LOC/ORG). Using Wikidata as a source, we create the largest resource of this type to date. We describe our approach to filtering and standardizing the data to provide the best quality possible. ParaNames is useful for multilingual language processing, both in defining tasks for name translation/transliteration and as supplementary data for tasks such as named entity recognition and linking. We demonstrate the usefulness of ParaNames on two tasks. First, we perform canonical name translation between English and 17 other languages. Second, we use it as a gazetteer for multilingual named entity recognition, obtaining performance improvements on all 10 languages evaluated.
What changes when you randomly choose BPE merge operations? Not much
May 04, 2023We introduce three simple randomized variants of byte pair encoding (BPE) and explore whether randomizing the selection of merge operations substantially affects a downstream machine translation task. We focus on translation into morphologically rich languages, hypothesizing that this task may show sensitivity to the method of choosing subwords. Analysis using a Bayesian linear model indicates that two of the variants perform nearly indistinguishably compared to standard BPE while the other degrades performance less than we anticipated. We conclude that although standard BPE is widely used, there exists an interesting universe of potential variations on it worth investigating. Our code is available at: https://github.com/bltlab/random-bpe.
ParaNames: A Massively Multilingual Entity Name Corpus
Mar 31, 2022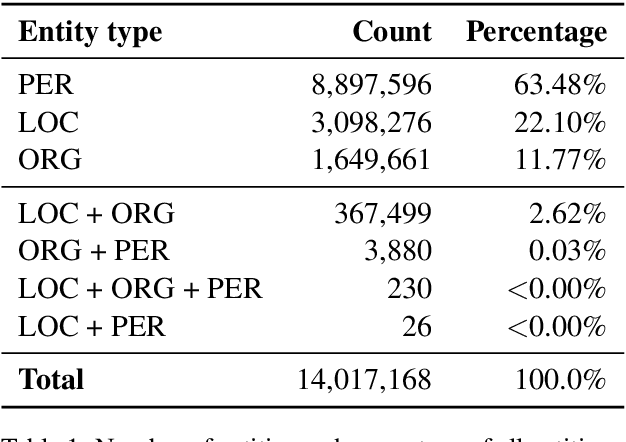
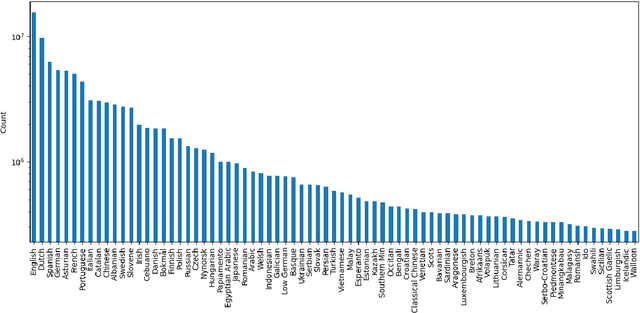
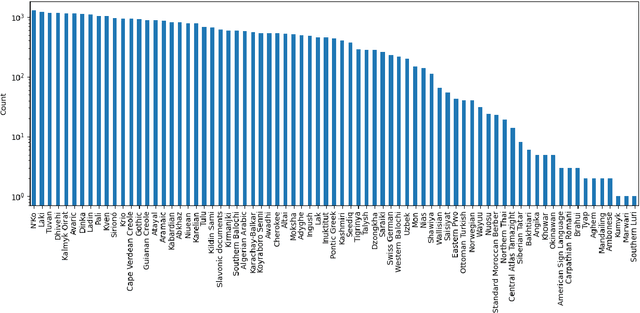
This preprint describes work in progress on ParaNames, a multilingual parallel name resource consisting of names for approximately 14 million entities. The included names span over 400 languages, and almost all entities are mapped to standardized entity types (PER/LOC/ORG). Using Wikidata as a source, we create the largest resource of this type to-date. We describe our approach to filtering and standardizing the data to provide the best quality possible. ParaNames is useful for multilingual language processing, both in defining tasks for name translation/transliteration and as supplementary data for tasks such as named entity recognition and linking. We demonstrate an application of ParaNames by training a multilingual model for canonical name translation to and from English. Our resource is released at \url{https://github.com/bltlab/paranames} under a Creative Commons license (CC BY 4.0).
Toward More Meaningful Resources for Lower-resourced Languages
Feb 24, 2022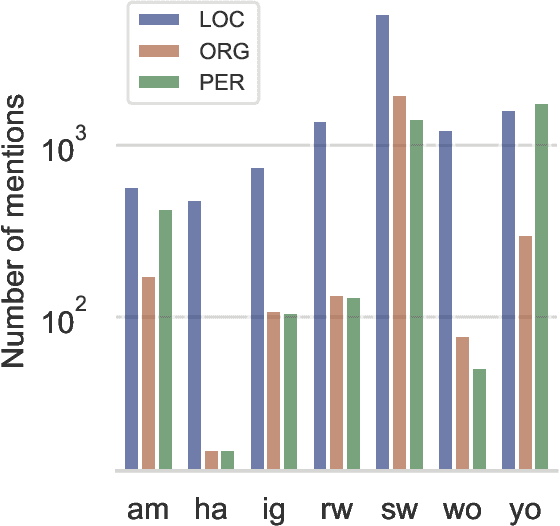


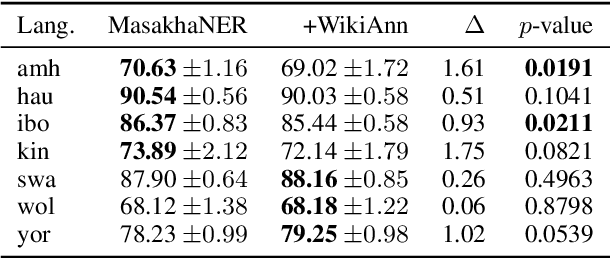
In this position paper, we describe our perspective on how meaningful resources for lower-resourced languages should be developed in connection with the speakers of those languages. We first examine two massively multilingual resources in detail. We explore the contents of the names stored in Wikidata for a few lower-resourced languages and find that many of them are not in fact in the languages they claim to be and require non-trivial effort to correct. We discuss quality issues present in WikiAnn and evaluate whether it is a useful supplement to hand annotated data. We then discuss the importance of creating annotation for lower-resourced languages in a thoughtful and ethical way that includes the languages' speakers as part of the development process. We conclude with recommended guidelines for resource development.
Mining Wikidata for Name Resources for African Languages
Apr 01, 2021



This work supports further development of language technology for the languages of Africa by providing a Wikidata-derived resource of name lists corresponding to common entity types (person, location, and organization). While we are not the first to mine Wikidata for name lists, our approach emphasizes scalability and replicability and addresses data quality issues for languages that do not use Latin scripts. We produce lists containing approximately 1.9 million names across 28 African languages. We describe the data, the process used to produce it, and its limitations, and provide the software and data for public use. Finally, we discuss the ethical considerations of producing this resource and others of its kind.
The Effectiveness of Morphology-aware Segmentation in Low-Resource Neural Machine Translation
Mar 20, 2021
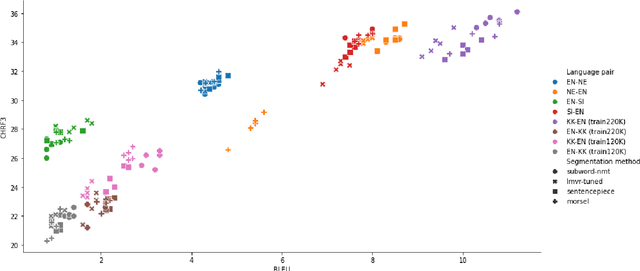

This paper evaluates the performance of several modern subword segmentation methods in a low-resource neural machine translation setting. We compare segmentations produced by applying BPE at the token or sentence level with morphologically-based segmentations from LMVR and MORSEL. We evaluate translation tasks between English and each of Nepali, Sinhala, and Kazakh, and predict that using morphologically-based segmentation methods would lead to better performance in this setting. However, comparing to BPE, we find that no consistent and reliable differences emerge between the segmentation methods. While morphologically-based methods outperform BPE in a few cases, what performs best tends to vary across tasks, and the performance of segmentation methods is often statistically indistinguishable.