 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward More Meaningful Resources for Lower-resourced Languages
Feb 24, 2022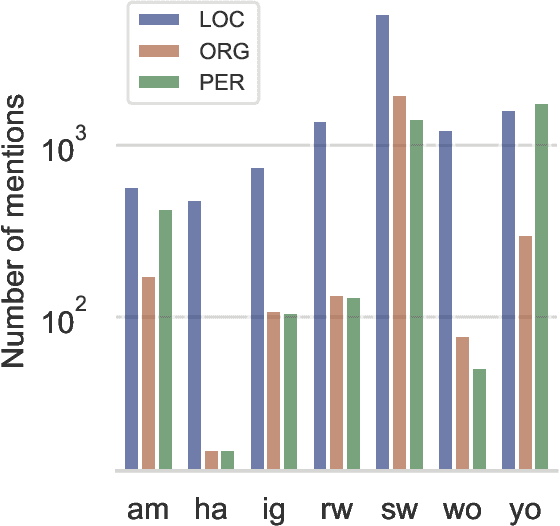


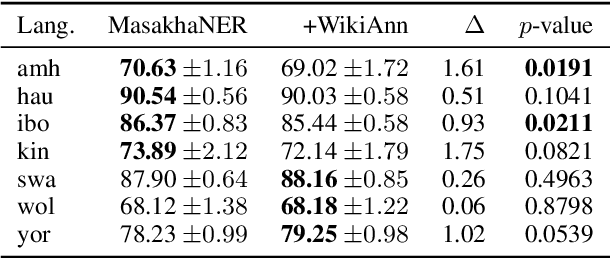
In this position paper, we describe our perspective on how meaningful resources for lower-resourced languages should be developed in connection with the speakers of those languages. We first examine two massively multilingual resources in detail. We explore the contents of the names stored in Wikidata for a few lower-resourced languages and find that many of them are not in fact in the languages they claim to be and require non-trivial effort to correct. We discuss quality issues present in WikiAnn and evaluate whether it is a useful supplement to hand annotated data. We then discuss the importance of creating annotation for lower-resourced languages in a thoughtful and ethical way that includes the languages' speakers as part of the development process. We conclude with recommended guidelines for resource development.
Addressing Barriers to Reproducible Named Entity Recognition Evaluation
Jul 29, 2021
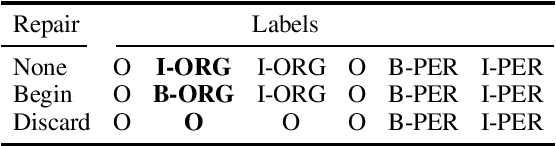

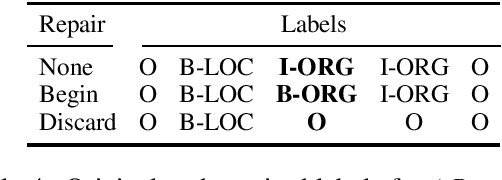
To address what we believe is a looming crisis of unreproducible evaluation for named entity recognition tasks, we present guidelines for reproducible evaluation. The guidelines we propose are extremely simple, focusing on transparency regarding how chunks are encoded and scored, but very few papers currently being published fully comply with them. We demonstrate that despite the apparent simplicity of NER evaluation, unreported differences in the scoring procedure can result in changes to scores that are both of noticeable magnitude and are statistically significant. We provide SeqScore, an open source toolkit that addresses many of the issues that cause replication failures and makes following our guidelines easy.