Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Barriers to Reproducible Named Entity Recognition Evaluation
Paper and Code

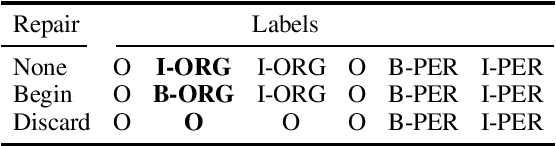

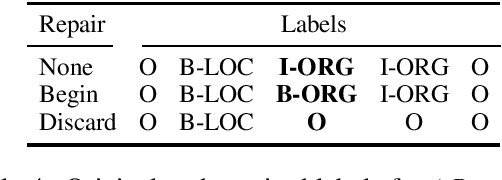
To address what we believe is a looming crisis of unreproducible evaluation for named entity recognition tasks, we present guidelines for reproducible evaluation. The guidelines we propose are extremely simple, focusing on transparency regarding how chunks are encoded and scored, but very few papers currently being published fully comply with them. We demonstrate that despite the apparent simplicity of NER evaluation, unreported differences in the scoring procedure can result in changes to scores that are both of noticeable magnitude and are statistically significant. We provide SeqScore, an open source toolkit that addresses many of the issues that cause replication failures and makes following our guidelines easy.
* Under review
View paper on